基本概念
整个集合框架就围绕一组标准接口而设计。你可以直接使用这些接口的标准实现,诸如: LinkedList, HashSet, 和 TreeSet 等,除此之外你也可以通过这些接口实现自己的集合。
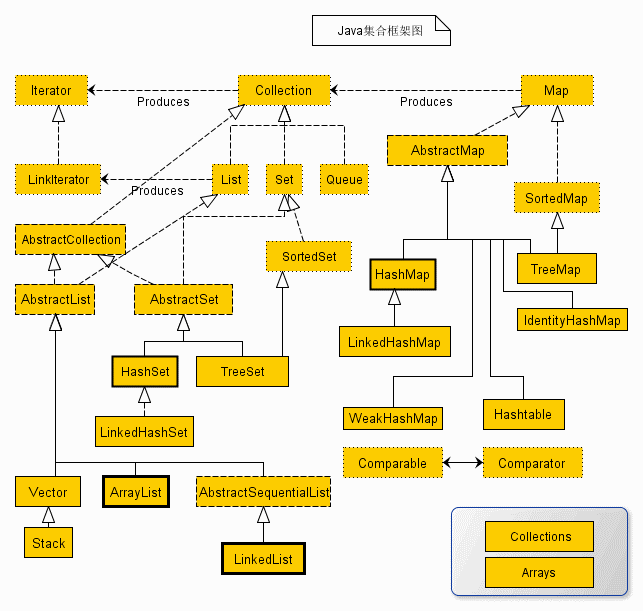
分成了两大类:Collection类和Map类
Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap
尽管 Map 不是集合,但是它们完全整合在集合中
内容:
-
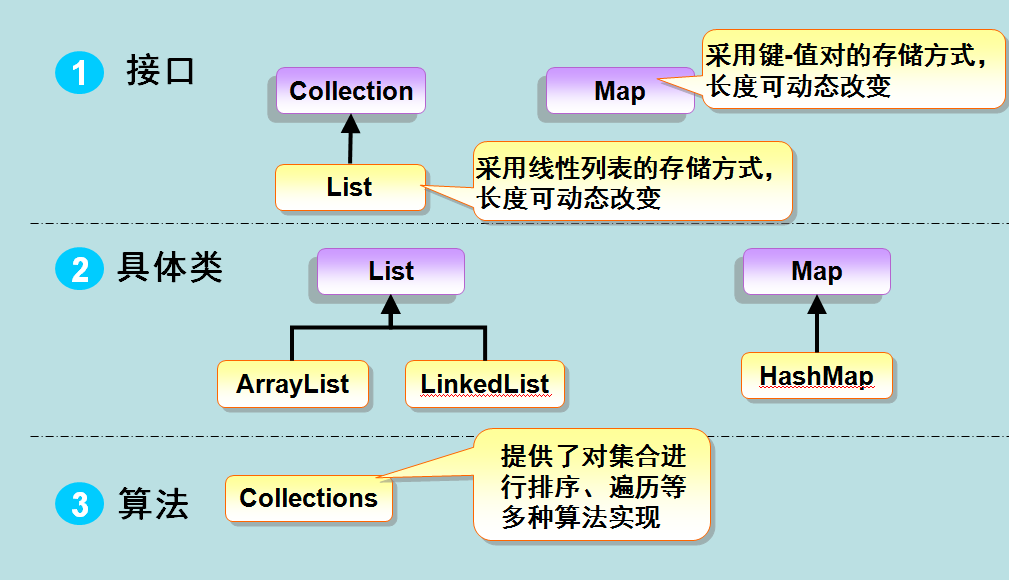
接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
-
实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
-
算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
集合框架体系如图所示
接口
集合框架定义了一些接口。本节提供了每个接口的概述:
| 序号 | 接口描述 |
|---|---|
| 1 | Collection 接口 Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。Collection 接口存储一组不唯一,无序的对象。 |
| 2 | List 接口 List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。List 接口存储一组不唯一,有序(插入顺序)的对象。 |
| 3 | Set Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。Set 接口存储一组唯一,无序的对象。 |
| 4 | SortedSet 继承于Set保存有序的集合。 |
| 5 | Map Map 接口存储一组键值对象,提供key(键)到value(值)的映射。 |
| 6 | Map.Entry 描述在一个Map中的一个元素(键/值对)。是一个Map的内部类。 |
| 7 | SortedMap 继承于 Map,使 Key 保持在升序排列。 |
| 8 | Enumeration 这是一个传统的接口和定义的方法,通过它可以枚举(一次获得一个)对象集合中的元素。这个传统接口已被迭代器取代。 |
Set和List的区别
-
Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素。
-
Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>。
-
List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> 。
实现类(集合类)
Java提供了一套实现了Collection接口的标准集合类。其中一些是具体类,这些类可以直接拿来使用,而另外一些是抽象类,提供了接口的部分实现。
标准集合类汇总于下表:
| 序号 | 类描述 |
|---|---|
| 1 | AbstractCollection 实现了大部分的集合接口。 |
| 2 | AbstractList 继承于AbstractCollection 并且实现了大部分List接口。 |
| 3 | AbstractSequentialList 继承于 AbstractList ,提供了对数据元素的链式访问而不是随机访问。 |
| 4 | LinkedList 该类实现了List接口,允许有null(空)元素。主要用于创建链表数据结构,该类没有同步方法,如果多个线程同时访问一个List,则必须自己实现访问同步,解决方法就是在创建List时候构造一个同步的List。例如:List list=Collections.synchronizedList(newLinkedList(...));LinkedList 查找效率低。 |
| 5 | ArrayList 该类也是实现了List的接口,实现了可变大小的数组,随机访问和遍历元素时,提供更好的性能。该类也是非同步的,在多线程的情况下不要使用。ArrayList 增长当前长度的50%,插入删除效率低。 |
| 6 | AbstractSet 继承于AbstractCollection 并且实现了大部分Set接口。 |
| 7 | HashSet 该类实现了Set接口,不允许出现重复元素,不保证集合中元素的顺序,允许包含值为null的元素,但最多只能一个。 |
| 8 | LinkedHashSet 具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。 |
| 9 | TreeSet 该类实现了Set接口,可以实现排序等功能。 |
| 10 | AbstractMap 实现了大部分的Map接口。 |
| 11 | HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。 该类实现了Map接口,根据键的HashCode值存储数据,具有很快的访问速度,最多允许一条记录的键为null,不支持线程同步。 |
| 12 | TreeMap 继承了AbstractMap,并且使用一颗树。 |
| 13 | WeakHashMap 继承AbstractMap类,使用弱密钥的哈希表。 |
| 14 | LinkedHashMap 继承于HashMap,使用元素的自然顺序对元素进行排序. |
| 15 | IdentityHashMap 继承AbstractMap类,比较文档时使用引用相等。 |
在前面的教程中已经讨论通过java.util包中定义的类,如下所示:
| 序号 | 类描述 |
|---|---|
| 1 | Vector 该类和ArrayList非常相似,但是该类是同步的,可以用在多线程的情况,该类允许设置默认的增长长度,默认扩容方式为原来的2倍。 |
| 2 | Stack 栈是Vector的一个子类,它实现了一个标准的后进先出的栈。 |
| 3 | Dictionary Dictionary 类是一个抽象类,用来存储键/值对,作用和Map类相似。 |
| 4 | Hashtable Hashtable 是 Dictionary(字典) 类的子类,位于 java.util 包中。 |
| 5 | Properties Properties 继承于 Hashtable,表示一个持久的属性集,属性列表中每个键及其对应值都是一个字符串。 |
| 6 | BitSet 一个Bitset类创建一种特殊类型的数组来保存位值。BitSet中数组大小会随需要增加。 |
算法
集合框架定义了几种算法,可用于集合和映射。这些算法被定义为集合类的静态方法。
在尝试比较不兼容的类型时,一些方法能够抛出 ClassCastException异常。当试图修改一个不可修改的集合时,抛出UnsupportedOperationException异常。
集合定义三个静态的变量:EMPTY_SET,EMPTY_LIST,EMPTY_MAP的。这些变量都不可改变。
| 序号 | 算法描述 |
|---|---|
| 1 | Collection Algorithms 这里是一个列表中的所有算法实现。 |
迭代器
通常情况下,你会希望遍历一个集合中的元素。例如,显示集合中的每个元素。
一般遍历数组都是采用for循环或者增强for,这两个方法也可以用在集合框架,但是还有一种方法是采用迭代器遍历集合框架,它是一个对象,实现了Iterator 接口或ListIterator接口。
迭代器,使你能够通过循环来得到或删除集合的元素。ListIterator 继承了Iterator,以允许双向遍历列表和修改元素。
| 序号 | 迭代器方法描述 |
|---|---|
| 1 | 使用 Java Iterator 这里通过实例列出Iterator和listIterator接口提供的所有方法。 |
遍历 ArrayList
实例
import java.util.*;
public class Test{
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
//第一种遍历方法使用 For-Each 遍历 List
for (String str : list) { //也可以改写 for(int i=0;i<list.size();i++) 这种形式
System.out.println(str);
}
//第二种遍历,把链表变为数组相关的内容进行遍历
String[] strArray=new String[list.size()];
list.toArray(strArray);
for(int i=0;i<strArray.length;i++) //这里也可以改写为 for(String str:strArray) 这种形式
{
System.out.println(strArray[i]);
}
//第三种遍历 使用迭代器进行相关遍历
Iterator<String> ite=list.iterator();
while(ite.hasNext())//判断下一个元素之后有值
{
System.out.println(ite.next());
}
}
}
解析:
三种方法都是用来遍历ArrayList集合,第三种方法是采用迭代器的方法,该方法可以不用担心在遍历的过程中会超出集合的长度。
遍历 Map
实例
import java.util.*;
public class Test{
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
}
比较器
TreeSet和TreeMap的按照排序顺序来存储元素. 然而,这是通过比较器来精确定义按照什么样的排序顺序。
这个接口可以让我们以不同的方式来排序一个集合。
| 序号 | 比较器方法描述 |
|---|---|
| 1 | 使用 Java Comparator 这里通过实例列出Comparator接口提供的所有方法 |
总结
Java集合框架为程序员提供了预先包装的数据结构和算法来操纵他们。
集合是一个对象,可容纳其他对象的引用。集合接口声明对每一种类型的集合可以执行的操作。
集合框架的类和接口均在java.util包中。
任何对象加入集合类后,自动转变为Object类型,所以在取出的时候,需要进行强制类型转换。
Java Map 接口
Map接口中键和值一一映射. 可以通过键来获取值。
-
给定一个键和一个值,你可以将该值存储在一个Map对象. 之后,你可以通过键来访问对应的值。
-
当访问的值不存在的时候,方法就会抛出一个NoSuchElementException异常.
-
当对象的类型和Map里元素类型不兼容的时候,就会抛出一个 ClassCastException异常。
-
当在不允许使用Null对象的Map中使用Null对象,会抛出一个NullPointerException 异常。
-
当尝试修改一个只读的Map时,会抛出一个UnsupportedOperationException异常。
| 1 | void clear( ) 从此映射中移除所有映射关系(可选操作)。 |
|---|---|
| 2 | boolean containsKey(Object k)如果此映射包含指定键的映射关系,则返回 true。 |
| 3 | boolean containsValue(Object v)如果此映射将一个或多个键映射到指定值,则返回 true。 |
| 4 | Set entrySet( )返回此映射中包含的映射关系的 Set 视图。 |
| 5 | boolean equals(Object obj)比较指定的对象与此映射是否相等。 |
| 6 | Object get(Object k)返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。 |
| 7 | int hashCode( )返回此映射的哈希码值。 |
| 8 | boolean isEmpty( )如果此映射未包含键-值映射关系,则返回 true。 |
| 9 | Set keySet( )返回此映射中包含的键的 Set 视图。 |
| 10 | Object put(Object k, Object v)将指定的值与此映射中的指定键关联(可选操作)。 |
| 11 | void putAll(Map m)从指定映射中将所有映射关系复制到此映射中(可选操作)。 |
| 12 | Object remove(Object k)如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。 |
| 13 | int size( )返回此映射中的键-值映射关系数。 |
| 14 | Collection values( )返回此映射中包含的值的 Collection 视图。 |
Collection一个对象存储方式是add
Map 两个对象存储方式 put()
Map集合中,不能出现重复键,每一个键最多只能映射一个值,但是不同键可以有相同值
实例
//实例化一个hashmap对象 public void hashMapTest() { Map<String, Integer> map=new HashMap<String, Integer>(); map.put("1",1); map.put("2", 2); System.out.println(map); }//{1=1, 2=2} }
map的分类和常见的情况
HashMap Hashtable LinkedHashMap 和TreeMap.
Hashmap 是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。 HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
public class MapTest { //实例化一个hashmap对象 public void hashMapTest() { Map<String, Integer> map=new HashMap<String, Integer>(); map.put("1",1); map.put("2", 3); map.put("0",2); map.put("3",4); map.put("4",0); System.out.println(map); //结果:{0=2, 1=1, 2=3, 3=4, 4=0} } }
观察上面的结果发现,输出map时,是按照key的顺序输出的。即根据建的hashcode值存储数据的。
Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
LinkedHashMap 是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比 LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
适用情况
一般情况下,我们用的最多的是HashMap,在Map 中插入、删除和定位元素
HashMap 是最好的选择。
要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
如果需要输出的顺序和输入的相同,那么用LinkedHashMap 可以实现,它还可以按读取顺序来排列.
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。在遍历的时候会比HashMap慢
TreeMap能够把它保存的记录根据键排序,默认是按升序排序,也可以指定排序的比较器。当用Iterator遍历TreeMap时,得到的记录是排过序的。
Java List 接口
List接口扩展了集合,并声明存储元素的序列集合的行为。
-
元素可以插入或访问他们的列表中的位置,使用从零开始的索引。
-
列表可以包含重复的元素。
-
除了由集合中定义的方法列表定义了一些它自己的,其它总结如下表。
-
如果集合不能被修改将抛出一个UnsupportedOperationException,当一个对象与另一个不兼容时产生ClassCastException。
List接口总结于下表的方法:
| 序号 | 方法描述 |
|---|---|
| 1 | void add(int index, Object obj) Inserts obj 插入到调用列表中的索引通过索引处。达到或超出插入点任何预先存在的要素被上移。因此,不会有元素被覆盖。 |
| 2 | boolean addAll(int index, Collection c) 插入c的所有元素入索引通过索引处的调用列表。等于或超出插入点任何预先存在的要素被上移。因此,没有任何元素被覆盖。如果调用列表更改并返回true,否则返回false。 |
| 3 | Object get(int index) 返回存储调用集合中指定索引处的对象。 |
| 4 | int indexOf(Object obj) 返回调用列表obj的第一个实例的索引。如果obj不是列表中的一个元素,则返回-1。 |
| 5 | int lastIndexOf(Object obj) 返回调用列表obj的最后一个实例的索引。如果obj不是列表中的一个元素,则返回-1。 |
| 6 | ListIterator listIterator( ) 返回一个迭代器调用列表的开始。 |
| 7 | ListIterator listIterator(int index) 返回一个迭代器调用列表开头的在指定索引处。 |
| 8 | Object remove(int index) 从调用列表删除index位置的元素,并返回被删除的元素。结果列表中被压缩。也就是说,随后的元素的索引减一。 |
| 9 | Object set(int index, Object obj) 赋予obj转换通过索引调用列表中指定的位置。 |
| 10 | List subList(int start, int end) 返回一个列表,其中包括在调用列表,从开始元素end-1。在返回列表中的元素也被调用对象的引用。 |
实例
以下是表示List接口如何使用的示例:
import java.util.*;
public class CollectionsDemo {
public static void main(String[] args) {
List a1 = new ArrayList();
a1.add("Zara");
a1.add("Mahnaz");
a1.add("Ayan");
System.out.println(" ArrayList Elements");
System.out.print(" " + a1);
List l1 = new LinkedList();
l1.add("Zara");
l1.add("Mahnaz");
l1.add("Ayan");
System.out.println();
System.out.println(" LinkedList Elements");
System.out.print(" " + l1);
}
}
以上实例编译运行结果如下:
ArrayList Elements
[Zara, Mahnaz, Ayan]
LinkedList Elements
[Zara, Mahnaz, Ayan]
Java Set集合
Set 表示唯一对象的集合。集合中元素的排序是不相关的。
集合框架提供三种类型的集合:
-
数学集
-
排序集
-
导航集
数学集
-
Set接口对数学中的一组进行建模。集合是唯一元素的集合。 -
Java最多允许一个Set中的一个空元素。
Set中元素的排序并不重要。 -
Java不保证
Set中元素的排序。 -
当循环遍历
Set的所有元素时,你得到Set中的每个元素一次。 -
集合框架提供
HashSet类作为实现为设置接口。无序、不重复、一个可为空
以下代码显示了如何创建一个Set并向其添加元素。 当向集合添加重复元素时,它们将被忽略。
如果比较它们,则在集合中的两个元素被认为是相等的使用equals()方法返回true。
import java.util.HashSet;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<String> s1 = new HashSet<>();
// Add a few elements
s1.add("HTML");
s1.add("CSS");
s1.add("XML");
s1.add("XML"); // Duplicate
// Create another set by copying s1
Set<String> s2 = new HashSet<>(s1);
// Add a few more elements
s2.add("Java");
s2.add("SQL");
s2.add(null); // one null is fine
s2.add(null); // Duplicate
System.out.println("s1: " + s1);
System.out.println("s1.size(): " + s1.size());
System.out.println("s2: " + s2);
System.out.println("s2.size(): " + s2.size());
}
}
上面的代码生成以下结果。

LinkedHashSet
集合框架提供LinkedHashSet类作为Set接口的另一个实现类。
HashSet不保证顺序元素。LinkedHashSet在插入元素时保持元素顺序。
import java.util.LinkedHashSet;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<String> s1 = new LinkedHashSet<>();
s1.add("A");
s1.add("B");
s1.add("C");
s1.add("D");
System.out.println("LinkedHashSet: " + s1);
}
}
上面的代码生成以下结果。

集合操作
我们可以对集合执行并集,交集和差分运算。
// Union of s1 and s2 will be stored in s1
s1.add(s2);
// Intersection of s1 and s2 will be stored in s1
s1.retainAll(s2);
// Difference of s1 and s2 will be stored in s1
s1.removeAll(s2);
在集合操作期间,修改s1。要保持原始设置不变,请在操作之前复制:
Set s1Unions2 = new HashSet(s1); // Make a copy of s1
s1Unions2.addAll(s2);
要测试集合s1是否是另一个集合s2的子集,请使用s2.containsAll(s1)方法。
import java.util.HashSet;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<String> s1 = new HashSet<>();
s1.add("HTML");
s1.add("CSS");
s1.add("XML");
Set<String> s2 = new HashSet<>();
s2.add("Java");
s2.add("Javascript");
s2.add("CSS");
System.out.println("s1: " + s1);
System.out.println("s2: " + s2);
performUnion(s1, s2);
performIntersection(s1, s2);
performDifference(s1, s2);
testForSubset(s1, s2);
}
public static void performUnion(Set<String> s1, Set<String> s2) {
Set<String> s1Unions2 = new HashSet<>(s1);
s1Unions2.addAll(s2);
System.out.println("s1 union s2: " + s1Unions2);
}
public static void performIntersection(Set<String> s1, Set<String> s2) {
Set<String> s1Intersections2 = new HashSet<>(s1);
s1Intersections2.retainAll(s2);
System.out.println("s1 intersection s2: " + s1Intersections2);
}
public static void performDifference(Set<String> s1, Set<String> s2) {
Set<String> s1Differences2 = new HashSet<>(s1);
s1Differences2.removeAll(s2);
Set<String> s2Differences1 = new HashSet<>(s2);
s2Differences1.removeAll(s1);
System.out.println("s1 difference s2: " + s1Differences2);
System.out.println("s2 difference s1: " + s2Differences1);
}
public static void testForSubset(Set<String> s1, Set<String> s2) {
System.out.println("s2 is subset s1: " + s1.containsAll(s2));
System.out.println("s1 is subset s2: " + s2.containsAll(s1));
}
}
上面的代码生成以下结果。