1.选一个自己感兴趣的主题或网站。(所有同学不能雷同)
https://www.bilibili.com/video/av4343074
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
import requests
import json
def getHTML(html):
count=1
fi=open('bilibili.txt','w',encoding='utf-8')
while(True):
url=html+str(count)
url=requests.get(url)
if url.status_code==200:
cont=json.loads(url.text)
else:
break
lengthRpy = len(cont['data']['replies'])
if lengthRpy!=0:
for i in range(lengthRpy):
comMsg=cont['data']['replies'][i]['content']['message']
fi.write(comMsg + ' ')
leng=len(cont['data']['replies'][i]['replies'])
for j in range(leng):
comMsgRp=cont['data']['replies'][i]['replies'][j]['content']['message']
fi.write(comMsgRp + ' ')
else:
break
count += 1
fi.close()
print('共',count-1,'页评论写入成功!')
url="https://api.bilibili.com/x/v2/reply?type=1&oid="
dizhi='4343074'
html=url+dizhi+'&pn='
getHTML(html)
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
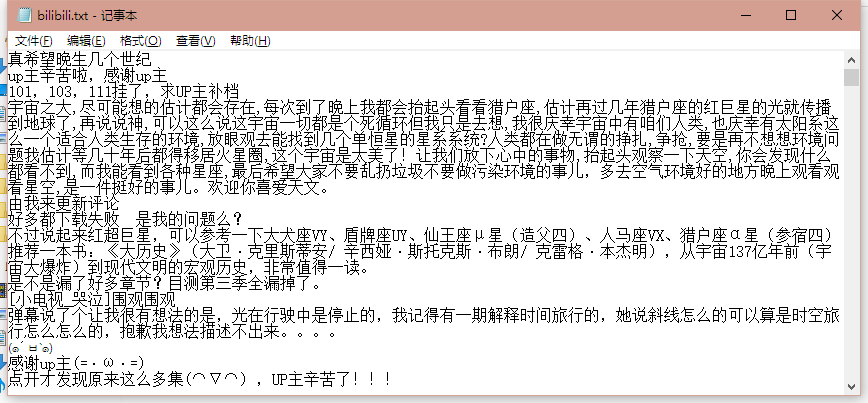
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
进入开发者选项,选中newwork-仔细查找和通过查找资料得知评论api为
http://api.bilibili.com/x/reply
例:https://api.bilibili.com/x/v2/reply?type=1&oid=4251267&pn=1 其中pn为页数,oid为地址编号
然后选取评论,再保存为文件
读取文本,使用第三方库(jieba)将文本中的高频词汇分出,为词云设置背景图片和词云颜色。
结果:
