综合练习
词频统计预处理
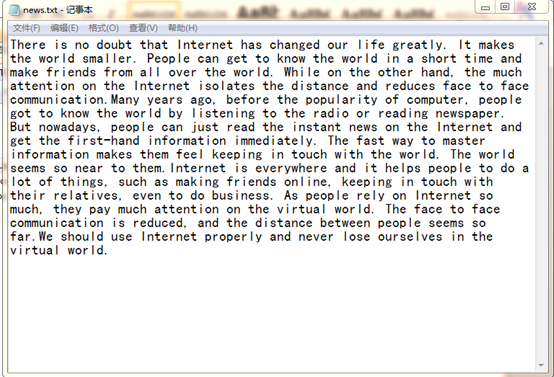
下载一首英文的歌词或文章
将所有,.?!’:等分隔符全部替换为空格
将所有大写转换为小写
生成单词列表
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
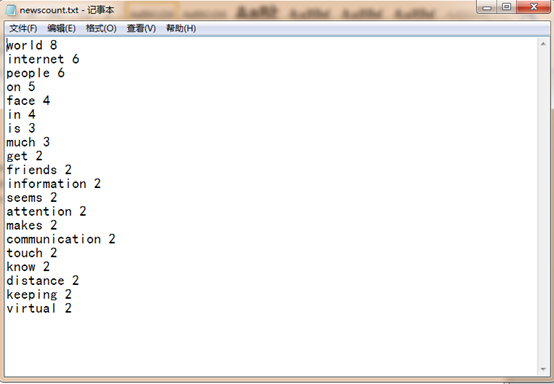
输出词频最大TOP20
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f=open('news.txt','r')
s=f.read()
f.close()
s1='''.?!'",'''
exclude={'the','a','an','and','of','to','as','so'}
for c in s1:
s=s.replace(c," ")
strlist=s.lower().split()
strdict={}
#通过遍历列表创建字典
# for m in strlist:
# strdict[m]=strdict.get(m,0)+1
# 通过遍历集合创建字典
strset=set(strlist)-exclude
for w in strset:
strdict[w]=strlist.count(w)
dictlist=list(strdict.items())
dictlist.sort(key=lambda x:x[1],reverse=True)
f=open('newscount.txt','a')
for i in range(20):
f.write(dictlist[i][0]+' '+str(dictlist[i][1])+'
')
f.close()
2.中文词频统计
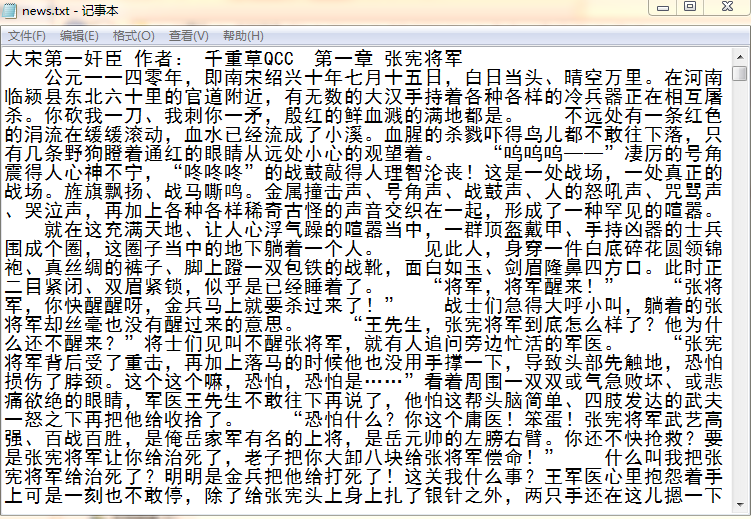
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
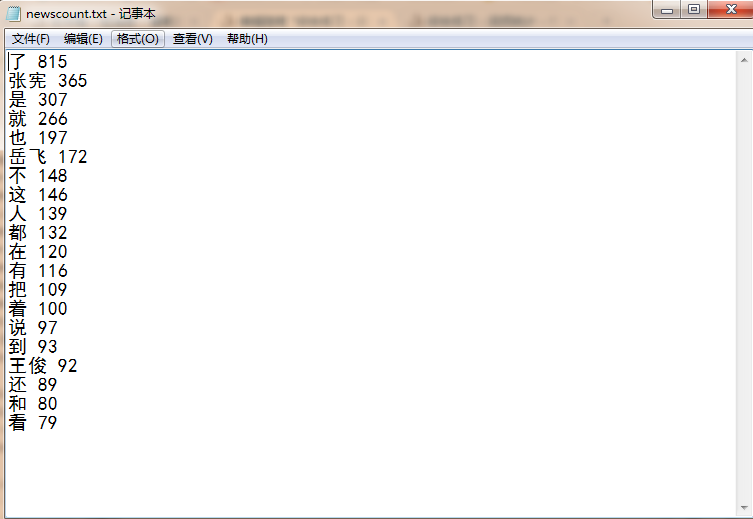
输出词频最大TOP20(或把结果存放到文件里)
import jieba
n= open('news.txt','r',encoding='UTF-8')
news=n.read()
n.close()
news = list(jieba.cut(news))
s= {",","。",":","“","”","?"," ",";","!","、","ufeff","
","u3000"}
newsset=set(news)-s
exclude={'的','地','他','你','我','又','与'}
newsset=newsset-exclude
strdict = {}
# 通过遍历列表创建字典
for i in newsset:
strdict[i] = news.count(i)
dictlist = list(strdict.items())
dictlist.sort(key=lambda x: x[1], reverse=True)
f = open('newscount.txt', 'a')
for i in range(20):
f.write(dictlist[i][0] + ' ' + str(dictlist[i][1]) + '
')
f.close()