综合案例
1 综合案例
1.0 文件排序

解法:
1.读取数据
2.数据清洗,变换数据格式
3.从新分区成一个分区
4.按照key排序,返还带有位次的元组
5.输出
1.2 二次排序
题目大意:先按照第一个比,相同则按照第二个比
题意思路:
1.读取数据
2.转换格式如下


可用图片展示:

1.3 连接操作
案例介绍:
有两个表:movie表,和score表
score:包含的信息为:用户ID,电影ID,电影评分
movie:电影ID,电影名字
我们想要得到,评分超过4分的(电影ID,电影名字,电影评分)
思路如下:
首先先弄score表:
1.获取想要的信息
2.获取对应电影ID的平均值
3.更换格式:keyBy,如下

对于movie表进行连接,连接前需要变化下格式
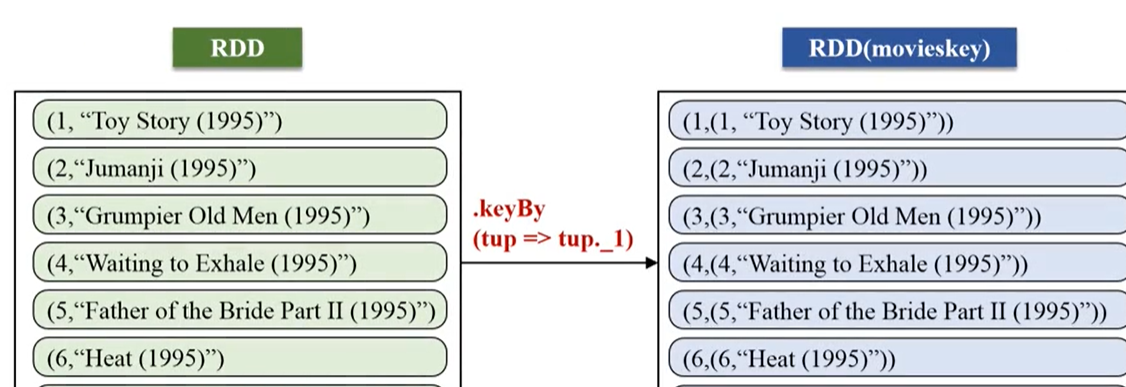
然后可通过相同的key进行连接join,后的结果如下:
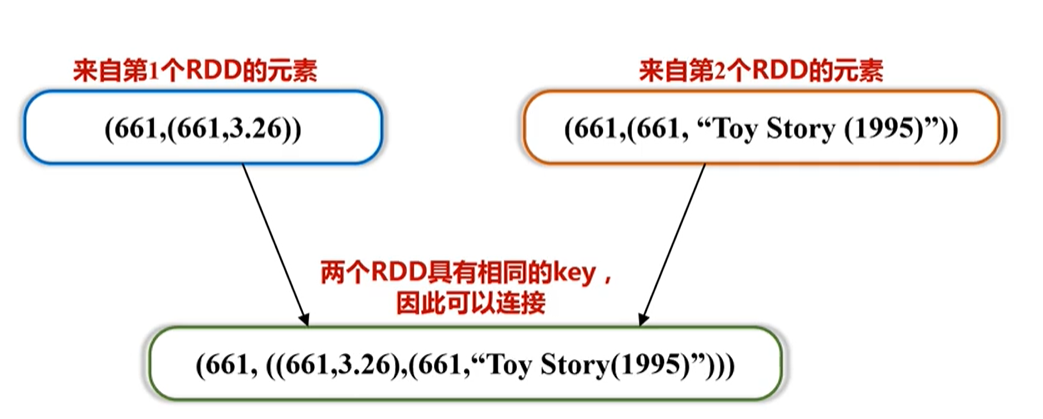
进行评分的过滤,然后取出需要的数据
输出:
score表:

movie表:

最终输出:
