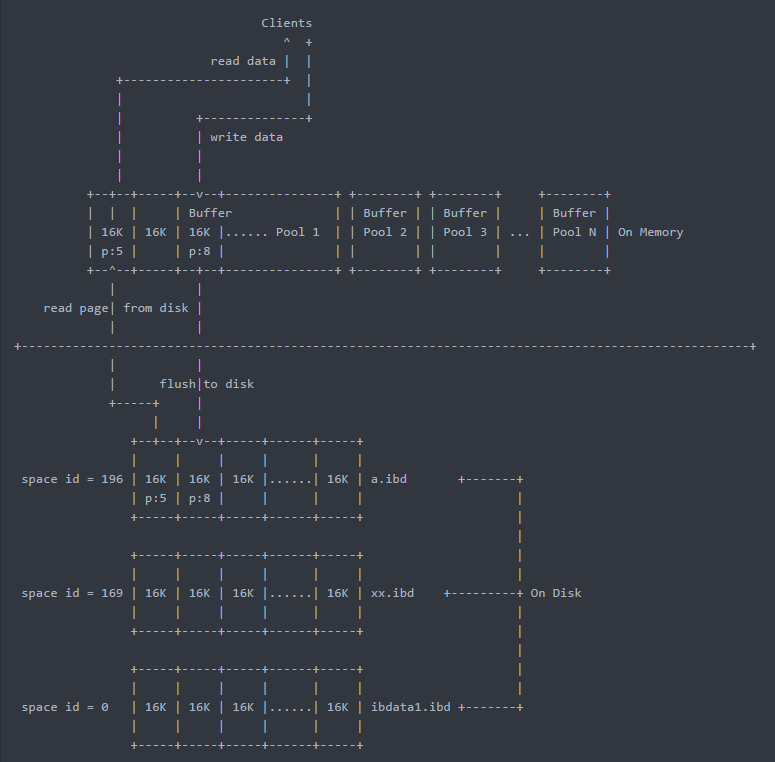
Ⅰ、缓冲池介绍
innodb存储引擎缓冲池(buffer pool) ,类似于oracle的sga,里面放着数据页 、索引页 、change buffer 、自适应哈希 、锁(5.5之前)等内容
综上所示:
- 每次读写数据都是通过Buffer Pool
- 当Buffer Pool中没有用户所需要的数据时才去硬盘中获取
- 通过innodb_buffer_pool_size进行设置总容量,该值设置的越大越好
Ⅱ、缓冲池性能问题
2.1 性能线性扩展
假设服务器72核,ht超线程后,144个逻辑核,跑测试按道理144个核应该跑满,如果跑不满,就说明并发有瓶颈,我加核了,却用不上,性能上不去
5.1之前这个问题经常被吐槽,现在不存在这个问题了
1G空间下面如果有65536个page,对这些page进行管理,每次都要对bp加锁(latch),如果bp大了,就有瓶颈,这里说的锁是bp的latch,和数据库的lock不是一回事
qps达到1w,每秒钟要获得至少1w次latch(就看bp的latch,不谈释放和唤醒latch),开销比较大
核比较多,latch或者并发设计的不好,性能则不能线性扩展 ,而这个bp对于扩展性非常重要,所有的热点的page都在里面,每次访问这些page都要获得bp的latch
2.2 如何提升上述缓冲池性能问题
调整innodb_buffer_pool_instances参数,设置为cpu的数量
默认5.5为1,5.6和5.7是8(前提是缓冲池大于1G)
假设开始这个值是1,现调整为4,原来1个bp管理65536个页,现在4个bp,每个bp管理16384个页,拆成4个分片,将热点打散,latch变少了,并发性能提升了,这是非常常见的内核层对并发调优的手段,经测试,不调整与调整后性能相差30%
tips:
设置多个缓冲池的时候,必须满足每个池子大于1G才生效,否则,即使my.cnf中设置了innodb_buffer_pool_instances,重启看看是没用的
Ⅲ、buffer pool中热点数据的管理
3.1 buffer pool的组成
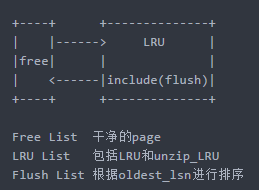
缓冲池中的热点是以page为单位来管理,并不是三种List加起来等于总的bp大小,而是Free List + LRU List(Flush List是包含在LRU list里面的)
- Free List 放空白的page
buffer Pool刚启动时,有一个个16K的空白的页,这些页就存放(链表串联)在Free List中
- LRU List 包括LRU和unzip_LRU
当读取一个数据页的时候,就从Free List中取出一个页,存入数据,并将该页读到LRU List中
当Free List给一个页给LRU List时,这个过程中需要一个并发控制,也就是之前说的latch,假设现在有两个线程都读到磁盘上这个页,则都需要问Free List来申请空闲页,谁先来先给谁,latch就是对这三个List进行并发控制访问的
- Flush List包含脏页(数据经过修改,但是未刷入磁盘的页),根据oldest_lsn进行排序
假设被读到的页,马上被更新,这个页就叫脏页,会被放入到Flush List列表中,但只是放了一个指针,而不是实际的页(只要修改过,就放入,不管修改几次)
如何查看缓冲池中的脏页?
SELECT
pool_id,
lru_position,
space,
page_number,
table_name,
oldest_modification,
newest_modification
FROM
information_schema.INNODB_BUFFER_PAGE_LRU
WHERE
oldest_modification <> 0
AND oldest_modification <> newest_modification;
结果集为空,则表示没有脏页,线上小心,不要乱执行,此sql消耗比较大
tips:
Flush list 中存放的不是一个页,而是页的指针(page number)
小结:
LRU List存放的是所有已经使用的页,里面既有干净页也有脏页,Flush List中只有指向脏页的指针
3.2 查看buffer pool的状态
方法1:show engine innodb statusG
...
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 303387
Buffer pool size 8192 #缓冲池中共8192个page
Free buffers 7772 #空白页(Free List),线上很可能是0
Database pages 420 #在使用的页(LRU List)
Old database pages 0 #LRU中教冷的page
Modified db pages 0 #脏页
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s #youngs表示old变为new
Pages read 368, created 52, written 322
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 420, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
...
如果设置了多个buffer pool
找到individual buffer pool info看每一个bp的情况
方法2:看两张元数据表
先说下,这东西比较大,看起来不是很方便,不太推荐
root@localhost) [(none)]> SELECT
-> pool_id,
-> pool_size,
-> free_buffers,
-> database_pages,
-> old_database_pages,
-> modified_database_pages
-> FROM
-> information_schema.innodb_buffer_pool_statsG
*************************** 1. row ***************************
pool_id: 0
pool_size: 8192
free_buffers: 7772
database_pages: 420
old_database_pages: 0
modified_database_pages: 0
1 row in set (0.00 sec)
(root@localhost) [(none)]> SELECT
-> space, page_number, newest_modification, oldest_modification
-> FROM
-> information_schema.innodb_buffer_page_lru
-> LIMIT 1G
*************************** 1. row ***************************
space: 0
page_number: 7
newest_modification: 5330181742 #该页最近一次(最新)被修改的LSN值
oldest_modification: 0 #该页在Buffer Pool中第一次被修改的LSN值,FLush List是根据该值进行排序的,该值越小,表示该页应该最先被刷新
1 row in set (0.01 sec)
3.2 LRU算法解析
MySQL中使用了midpoint LRU算法来管理LRU List
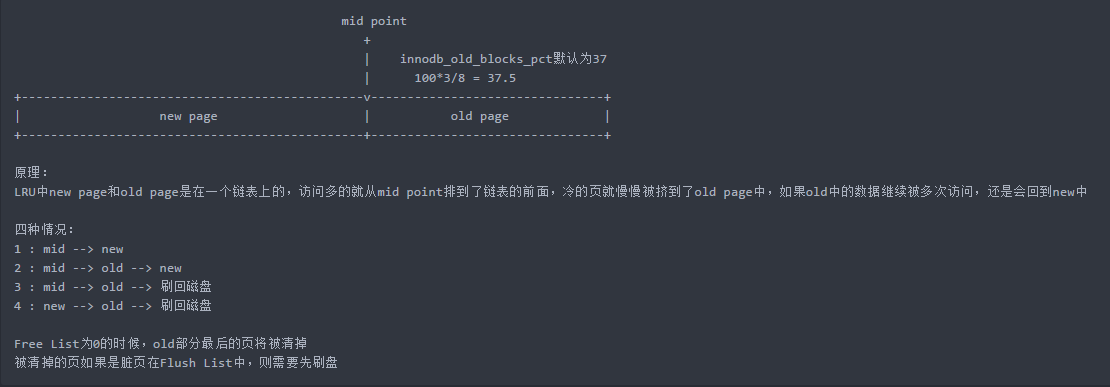
- 当该页被第一次读取时,将该页先放在mid point的位置(因为无法保证一定是活跃)
- 当被读到第二次时才将改页放入到new page的首部
- innodb_old_blocks_pct参数控制mid point的位置,默认是37,即3/8的位置
3.3 缓冲池防污染
有一种场景,某个page一下子被扫了n次,但其实他并不是热页,这时候如果按照之前说的,这个page会被放到new里面去,这其实就污染了缓冲池
那什么时候会出现一个page每秒被读n次呢?
scan的时候,select * from tb_name;如果这个page里有10条记录,这个page就会被读10次
我们可以通过将一个page固定在midpoint位置一定的时间来解决这个问题
set global innodb_old_blocks_time=1;
通常 select * 扫描操作不会高于1秒,一个页很快就被扫完了
无论读多少次,在innodb_old_blocks_time的时间内都不管(都视作只读取了一次),等这个时间过去了(时间到),如果该页还是被读取了,才把这个页放到new page的首部,如果设为0,则表示读到第二次就放到new里去
如果开发有个scan操作,就需要设置一下,操作完后再改回来。最好的方案是放到从机上,避免扫描语句污染LRU
tips:
①如果一个page中10条记录一次读,读这十条记录的时候这个页就会被锁成只读,那其他线程对这个页的操作就不被允许了,数据库是一个并发系统,这是不合理的,这样读一个页hold住锁的时间会长,所以是每读一条记录去读一次页,然后马上释放,把读到的位置————游标(这个游标和数据库的游标不是一回事)保存下来,下次再要读的时候,从打开这个游标继续读,但是位置可能会变化,所以会重新去读这个页,以此确保各个线程公平调度
②myisam缓存data是交给操作系统缓存 ,和pg一样
3.4 buffer pool的预热
背景:
在MySQL启动后(MySQL5.6之前),Buffer Pool中页的数据是空的,需要大量的时间才能把磁盘中的页读入到内存中,导致启动后的一段时间性能很差
例:启动的时候load
64GB BP 10M/s读取 100min
预热策略:将LRU列表dump出来,通过较顺序读取的方式预热50M~200M
预热方法:
select count(1) from table force index(primary)
select count(1) from index
说明:
上面两种方法很痤。并没有预热真正的热点数据,只是把数据读进来了,粒度非常粗,比如你数据100G,bp10G,那真正的热点很大部分不是热点数据
网易试过共享内存来做,数据库重启bp不清,不过操作系统重启了也就白搭了
好办法:
MySQL5.6 开始有办法了
(root@172.16.0.10) [(none)]> show variables like 'innodb_buffer_pool%';
+-------------------------------------+----------------+
| Variable_name | Value |
+-------------------------------------+----------------+
| innodb_buffer_pool_chunk_size | 134217728 |
| innodb_buffer_pool_dump_at_shutdown | ON | #在停机时dump出buffer pool中的(space,page)
| innodb_buffer_pool_dump_now | OFF | #set一下,表示现在就从buffer pool中dump
| innodb_buffer_pool_dump_pct | 25 | #dump的bp的前百分之多少,是每个buffer pool最近使用的页数,而不是整体,可写到[mysqld-5.7]中
| innodb_buffer_pool_filename | ib_buffer_pool | #dump出的文件的名字
| innodb_buffer_pool_instances | 1 |
| innodb_buffer_pool_load_abort | OFF |
| innodb_buffer_pool_load_at_startup | ON | #启动时加载dump的文件,恢复到buffer pool中
| innodb_buffer_pool_load_now | OFF | #set一下,表示现在加载 dump的文件
| innodb_buffer_pool_size | 1879048192 |
+-------------------------------------+----------------+
10 rows in set (0.00 sec)
- 关闭数据库之前把bp中的space和page_no给dump出来(不是整个bp,5.6还没正式发布的时候就是dump所有)
- 重启的时候会把dump出来的内容load进bp,dump出来是无序的,load之前根据space和pageno进行排序,load是异步的,返回速度还可以,对bp基本没影响
- dump的越多,启动的越慢
- 频繁dump会导致Buffer Pool中的数据越来越少,是因为设置了innodb_buffer_pool_dump_pct,默认25,姜总用的40
- 如果做了高可用,可以定期dump,然后将该dump的文件传送到slave上,然后直接load(slave上的(Space,Page)和Master上的 大致相同 )
简单演示一把:
(root@localhost) [(none)]> set global innodb_buffer_pool_dump_now = 1;
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [(none)]> show status like 'Innodb_buffer_pool_dump_status';
+--------------------------------+--------------------------------------------------+
| Variable_name | Value |
+--------------------------------+--------------------------------------------------+
| Innodb_buffer_pool_dump_status | Buffer pool(s) dump completed at 180302 16:57:45 |
+--------------------------------+--------------------------------------------------+
1 row in set (0.00 sec)
进入数据目录
[root@VM_0_5_centos data3306]# ll *pool
-rw-r----- 1 mysql mysql 604 Mar 2 16:59 ib_buffer_pool
[root@VM_0_5_centos data3306]# head ib_buffer_pool
0,568
0,567
0,566
0,565
0,278
0,564
0,563
0,562
164,3
164,2
停止服务
[root@VM_0_5_centos data3306]# mysqld_multi stop 3306
截取错误日志
2018-03-02T09:01:10.292549Z 0 [Note] InnoDB: Starting shutdown...
2018-03-02T09:01:10.392851Z 0 [Note] InnoDB: Dumping buffer pool(s) to /mdata/data3306/ib_buffer_pool
2018-03-02T09:01:10.393059Z 0 [Note] InnoDB: Buffer pool(s) dump completed at 180302 17:01:10
启动服务,加载热数据
[root@VM_0_5_centos data3306]# mysqld_multi start 3306
(root@localhost) [(none)]> set global innodb_buffer_pool_load_now = 1;
Query OK, 0 rows affected (0.00 sec)
再截取错误日志
2018-03-02T09:06:40.526294Z 0 [Note] InnoDB: Loading buffer pool(s) from /mdata/data3306/ib_buffer_pool
2018-03-02T09:06:40.526487Z 0 [Note] InnoDB: Buffer pool(s) load completed at 180302 17:06:40
tips:
注意一下innodb_buffer_pool_dump_pct这个参数,先看下下面这个流程
(root@localhost) [(none)]> set global innodb_buffer_pool_dump_pct=100;
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [(none)]> set global innodb_buffer_pool_dump_now = 1;
Query OK, 0 rows affected (0.00 sec)
[root@VM_0_5_centos data3306]# cat ib_buffer_pool |wc -l
576
(root@localhost) [(none)]> set global innodb_buffer_pool_dump_pct=20;
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [(none)]> set global innodb_buffer_pool_dump_now = 1;
Query OK, 0 rows affected (0.00 sec)
[root@VM_0_5_centos data3306]# cat ib_buffer_pool |wc -l
115
看上去没啥问题,但要注意的是,当你有多个缓冲池的时候,比如有4个,每个里面有100个page,它不是整体来dump前百分之25,而是dump每个缓冲池里面最前面的15个page
Ⅳ、异步读
发现全表扫描,如果已经扫了一部分内容,innodb会异步读取这部分内容后面的一部分,即使你没读到,异步读有两种情况,如下:
随机预读
innodb_random_read_ahead
线性预读
innodb_read_ahead_threshold 该参数目前缺省值为0
- 线性预读放到以extent为单位,而随机预读放到以extent中的page为单位
- 线性预读是将下一个extent提前读取到buffer pool中,随机预读是将当前extent中的剩余的page提前读取到buffer pool中