一、编译&生成&测试&删除
1.编写模块代码,查看如下
gedit 1.c(编写)
cat 1.c(查看)
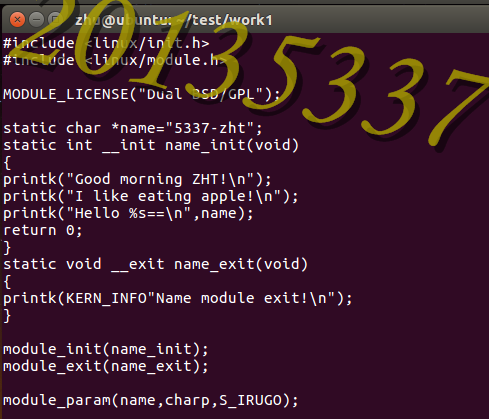
MODULE_AUTHOR("Z")
MODULE_DESCRIPTION(模块用途的简单描述);
MODULE_VERSION(模块的版本字符串);
MODULE_ALIAS(模块的别名);
2.查看版本信息

3.写Makefile并查看
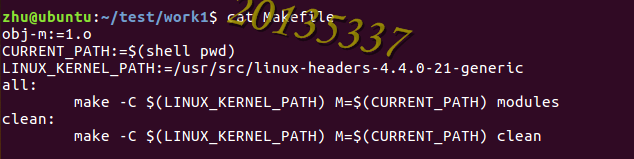
obj-m :这个变量是指定你要声称哪些模块模块的格式为 obj-m := <模块名>.o
modules-objs :这个变量是说明声称模块modules需要的目标文件 格式要求 <模块名>-objs := <目标文件>
切记:模块的名字不能取与目标文件相同的名字。如在这里模块名不能取成 mymod;
KDIR :这是我们正在运行的操作系统内核编译目录。也就是编译模块需要的环境
M= :指定我们源文件的位置
PWD :这是当前工作路径$(shell )是make的一个内置函数。用来执行shell命令。
4.make自动生成很多文件

5.加载、测试、删除模块
dmesg(查看内核信息)
- 加载、测试模块


- 卸载模块


- 其他

dmesg | tail -12 查看内核输出信息;tail -12 显示最后12条。
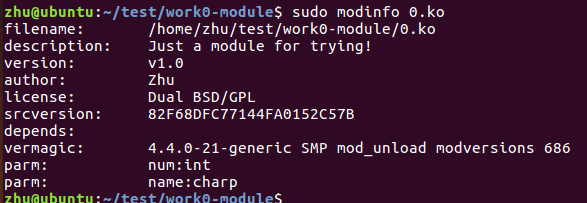
modinfo查看模块信息:
sudo modinfo 1.ko
depmod分析可加载模块的依赖性,并生成modules.dep文件和映射文件
modprobe Linux内核添加删除模块
二、系统调用(增加223号)
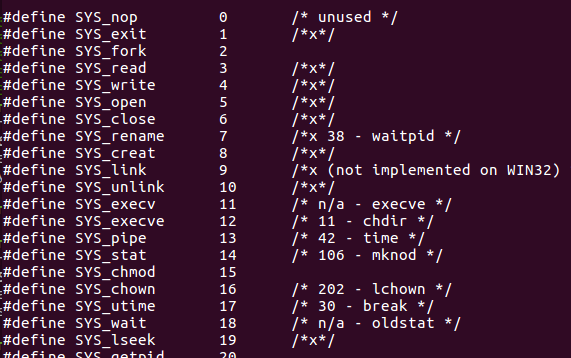
1.查看本机系统调用表地址

查看系统调用号

2.源码(详细代码略)、测试程序

测试程序
#include <stdio.h>
#include <stdlib.h>
int main()
{
unsigned long x = 0;
x = syscall(223);
printf("Hello, %ld
", x);
return 0;
}
分析
代码
static int clear_cr0(void) //使cr0寄存器的第17位设置为0(即是内核空间可写)
{
unsigned int cr0 = 0;
unsigned int ret;
asm volatile ("movl %%cr0, %%eax":"=a"(cr0)); //将cr0寄存器的值移动到eax的寄存器中,同时输出到cr0变量中
ret = cr0;
cr0 &= 0xfffeffff; //将cr0变量的值中的第17位清0,一会将修改后的值写入cr0寄存器
asm volatile ("movl %%eax, %%cr0": :"a"(cr0)); //将cr0变量的值做为输入,输入到寄存器eax中,同时移动到寄存器cr0中
return ret;
}
static int __init call_init(void)
{
sys_call_table_my = (unsigned long*)(SYS_CALL_TABLE_ADDRESS);
printk("call_init.......
");
anything_saved = (int (*)(void))(sys_call_table_my[NUM]); //保存系统调用表中的NUM位置上的系统调用
orig_cr0 = clear_cr0(); //使内核地址空间可写
sys_call_table_my[NUM] =(unsigned long) &sys_mycall; //用自己的系统调用替换NUM位置上的系统调用
setback_cr0(orig_cr0); //使内核地址空间不可写
return 0;
}
asm volatile("movl %%eax,%%cr0"::"a"(val));
举例说明:volatile int i=10; int j = i; ... int k = i; volatile 告诉编译器i是随时可能发生变化的,每次使用它的时候必须从i的地址中读取,因而编译器生成的可执行码会重新从i的地址读取数据放在k中。 volatile 影响编译器编译的结果,指出,volatile 变量是随时可能发生变化的,与volatile变量有关的运算,不要进行编译优化,以免出错,(VC++ 在产生release版可执行码时会进行编译优化,加volatile关键字的变量有关的运算,将不进行编译优化。)。其中编译器编译优化是:由于编译器发现两次从i读数据的代码之间的代码没有对i进行过操作,它会自动把上次读的数据放在k中。而不是重新从i里面读。这样以来,如果i是一个寄存器变量或者表示一个端口数据就容易出错,所以说volatile可以保证对特殊地址的稳定访问,不会出错。
模块加载函数static int __init call_init(void):先保存系统调用表中223位置的系统调用,然后用static int clear_cr0(void)清零cr0的第十六 位,使内核空间可写,在内核空间可写的情况下用自己的系统调用asmlinkage long sys_mycall(void)替换223位置的系统调用,在完成替换后重新将cr0第十六位置位static void setback_cr0(int val)。
模块卸载函数static void __exit call_exit(void):用static int clear_cr0(void)清零cr0的第十六位,使内核空间可写,将保存的系统调用anything_saved恢复,完成后重新将cr0第十六位置位static void setback_cr0(int val)。
3.结果
测试代码为52.c
编译gcc 52.c -o b
运行 ./b


三、增加模块,功能:存在某指定文件,则输出“open success”,否则输出“open error”
asmlinkage long sys_mycall(void) //定义自己的系统调用
{
struct file *fp;
fp = filp_open("/home/zhu/mm", O_RDWR, 0644); //打开指定的文件
if (IS_ERR(fp)) //如果失败,输出“error”
{
printk("open error!!!!!!!!!!!!!!!!!!!!!!!!!
");
return 0;
}
else //成功,输出“success”
{
printk("open success!!!!!!!!!!!!!!!!!!!!!!!
");
}
return 0;
}
make
sudo insmod XXX.ko
./test.c

四、asmlinkage
0.函数定义前加宏asmlinkage ,表示这些函数通过堆栈而不是通过寄存器传递参数。
1.gcc编译器在汇编过程中调用c语言函数时传递参数有两种方法:一种是通过堆栈,另一种是通过寄存器。缺省时采用寄存器,假如你要在你的汇编过程中调用c语言函数,并且想通过堆栈传递参数,你定义的c函数时要在函数前加上宏asmlinkage。
1.采用asmlinkage,绝对不是因为不同架构可以通用户,而是因为用户态寄存器在系统调用进入内核态时,会把用户态的寄存器全部压栈,通过合理的构造。正好满足用户态通过寄存器传递参数,内核态通过栈取参数的标准要求。这是很巧妙的安排,是高效的体现!其实还可以发现,内核只有在系统调用时才用asmlinkage,其它函数都没有。这是有意而为之的。
2.用户调用syscall的时候,参数都是通过寄存器传进来的。中间内核由把所有的参数压栈了, 所以这个asmlinkage可以通过到gcc,恰好可以用正确的调用方式取到参数。(系统调用做的工作除了函数调用,其本质就是现场保护、压栈之类的操作)
3.内核前面的那些统一处理很重要,这样后端真正的的syscall 实现函数就可以得到统一的调用方式了,而不是之间面对不同的abi。确实比较方便了。不然每个syscall函数里面都要自己去处理不同abi,多很多重复代码。
4.也可以考虑在这个统一的处理的时候,把参数全部按照一定的规范放到寄存器。 但这个方法不能在所有的cpu架构上面都做的到。
5.“统一”要比这个“寄存器传参”要重要。
6.从用户切换到内核,要做大量的处理。相比较其他部分,参数的开销不算什么。