自定义分区策略
思路
Command+Option+shift+N 调出查询页面,找到producer包的Partitioner接口
Partitioner下有一个DefaultPartitioner实现类
这里就有之前提到kafka数据分区策略
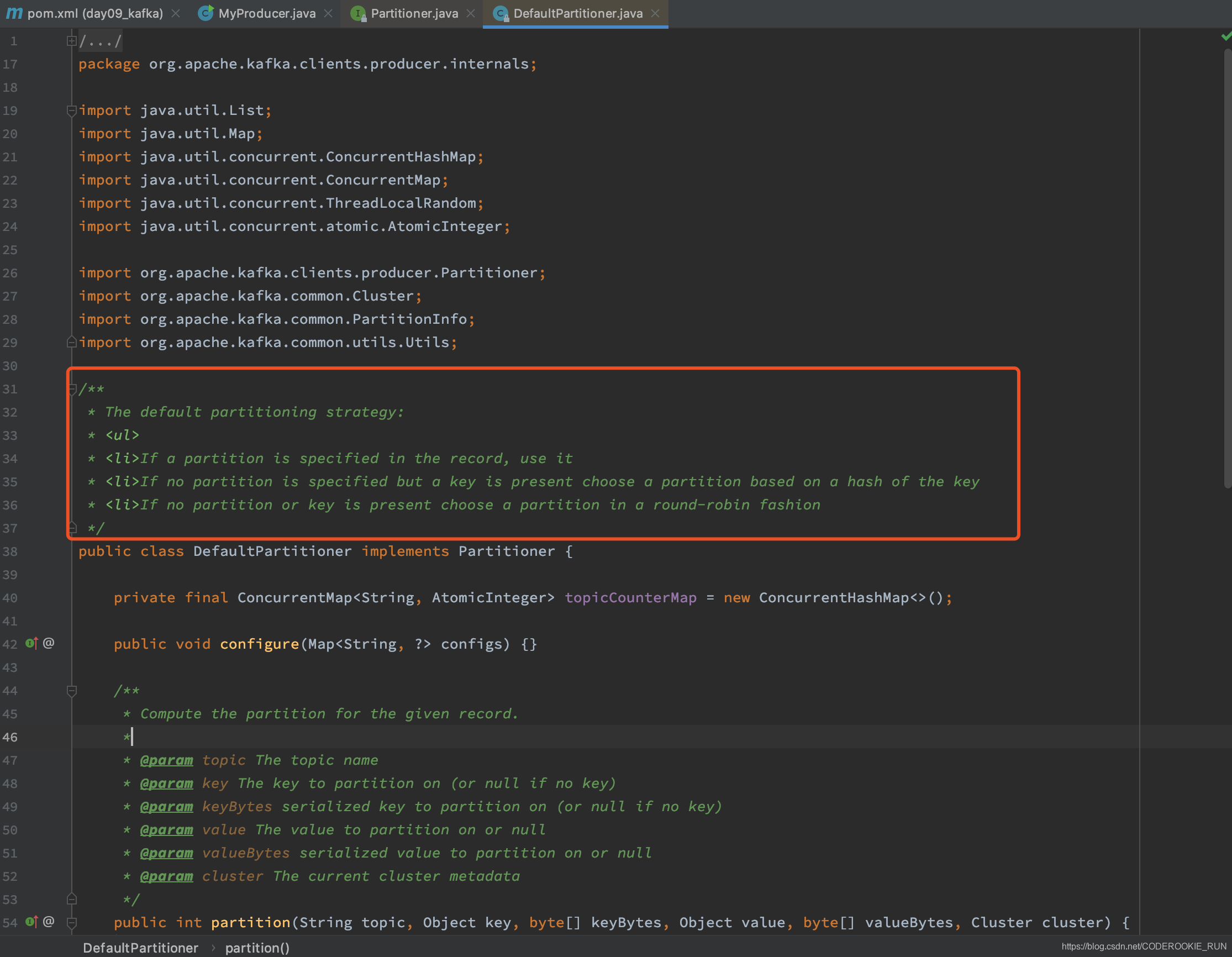
自定义分区策略
创建一个MyPartitioner类,继承并重新定义上面的Partitioner类
package cn.itcast.kafka.demo1;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class MyPartitioner implements Partitioner {
/**
* 此方法是确定分区规则
* @param topic
* @param key
* @param keyBytes
* @param value
* @param valueBytes
* @param cluster
* @return 返回的int值为分区
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//return 3 则指定发送数据到3分区
return 3;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
还需要在MyProducer中添加一行代码
props.put("partitioner.class","cn.itcast.kafka.demo1.MyPartitioner");
而且在MyProducer类中不需要指定分区号
producer.send(new ProducerRecord<String, String>("test" , "mykey" + i,"这是第" + i + "条message"));