一,函数的命名空间
在python中有三种命名空间:内置命名空间,全局命名空间,局部命名空间。
内置命名空间 —— python解释器
- 就是python解释器一启动就可以使用的名字存储在内置命名空间中
- 内置的名字在启动解释器的时候被加载进内存里
全局命名空间 —— 我们写的代码但不是函数中的代码
- 是在程序从上到下被执行的过程中依次加载进内存的
- 放置了我们设置的所有变量名和函数名
局部命名空间 —— 函数
- 就是函数内部定义的名字
- 当调用函数的时候 才会产生这个名称空间 随着函数执行的结束 这个命名空间就又消失了
命名空间注意:
- 在正常情况下,直接使用内置的名字
- 当我们在全局定义了和内置名字空间中同名的名字时,会使用全局的名字
- 当我自己有的时候 我就不找我的上级要了
- 如果自己没有 就找上一级要 上一级没有再找上一级 如果内置的名字空间都没有 就报错
- 多个函数应该拥有多个独立的局部名字空间,不互相共享
需要注意的是这里提到的上一级可以参考下面的关系表

假如定义了一个函数function()其中,function表示函数的内存地址,function()表示调用函数,函数的内存地址()表示函数的调用。
二,作用域
作用域分为两种:全局作用域跟局部作用域。
全局作用域:作用在全局,内置和全局名字空间中的名字都属于全局作用域 ——globals()
局部作用域: 作用在局部,函数(局部名字空间中的名字属于局部作用域) ——locals()
对于不可变数据类型 在局部可是查看全局作用域中的变量,但是不能直接修改,如果想要修改,需要在程序的一开始添加global声明。
如果在一个局部(函数)内声明了一个global变量,那么这个变量在局部的所有操作将对全局的变量有效。但是不建议这样使用。
三,闭包
首先介绍一下闭包的概念:在一些语言中,在函数中可以(嵌套)定义另一个函数时,如果内部的函数引用了外部的函数的变量,则可能产生闭包。闭包可以用来在一个函数与一组“私有”变量之间创建关联关系。在给定函数被多次调用的过程中,这些私有变量能够保持其持久性。
在python中想要形成闭包必须具备这三个条件:
1.必须有一个内嵌函数(函数里定义的函数)——这对应函数之间的嵌套
2.内嵌函数必须引用一个定义在闭合范围内(外部函数里)的变量——内部函数引用外部变量
3.外部函数必须返回内嵌函数——必须返回那个内部函数
1 def func(): 2 x=5 3 def pow(): 4 nonlocal x 5 x=x*x 6 return x 7 return pow 8 a=func() 9 print(a()) 10 print(a())
“闭包”的作用——保存函数的状态信息,使函数的局部变量信息依然可以保存下来。这里用到了nonlocal关键字,该关键字的作用和local的作用类似,就是让“内部函数”可以修改“外部函数(装饰器)”的局部变量值。
四,装饰器
在前面我们讲到的装饰器,没有传参数。但是有一种情况,就是有的函数需要加,有的不需要,或者有的函数有时候需要加,有时候又不要了呢。我们想到就是能不能通过给装饰器传一个参数,通过参数来判断需不需要执行。


1 def times_out(judge): 2 def times(f): 3 def internal(*args,**kwargs): 4 if judge: 5 stime=time.time() 6 res=f(*args,**kwargs) 7 etime=time.time() 8 print('cost time is %s' %(etime-stime)) 9 return res 10 else: 11 res=f(*args,**kwargs) 12 return res 13 return internal 14 return times 15 import time 16 judge=True #执行装饰器就为True,不执行改为false 17 @times_out(judge) 18 def test(): 19 time.sleep(1) 20 print('this is test') 21 return 'nb' 22 print(test())
我们可以发现想要传参数就是在外面加一层函数达到传参的效果。但是问题又来了,如果同一个函数需要用到多个装饰器,那执行的顺序或者流程又是什么呢。我想了想,只有拖着疲惫的身体跟大家分享一下我对这个的分析吧。当然为了让大家更好的明白执行顺序,我们的装饰器功能就比较简单了。
1 def f1(f): 2 def inner1(*args,**kwargs): 3 print('this is f1 befor') 4 res=f(*args,**kwargs) 5 print('this is f1 after') 6 return res 7 return inner1 8 def f2(f): 9 def inner2(*args,**kwargs): 10 print('this is f2 befor') 11 res=f(*args,**kwargs) 12 print('this is f2 after') 13 return res 14 return inner2 15 @f2 #f=f2(f)=f2(inner1)=inner2 16 @f1 #f=f1(f)=inner1 17 def say(): 18 print('this is main') 19 say() #say()=f()=inner(2)
上述代码执行结果
1 this is f2 befor 2 this is f1 befor 3 this is main 4 this is f1 after 5 this is f2 after
下面的上面代码的流程图,方便大家理解,还有就是当有多装饰器时,先执行离函数近的那个装饰器。
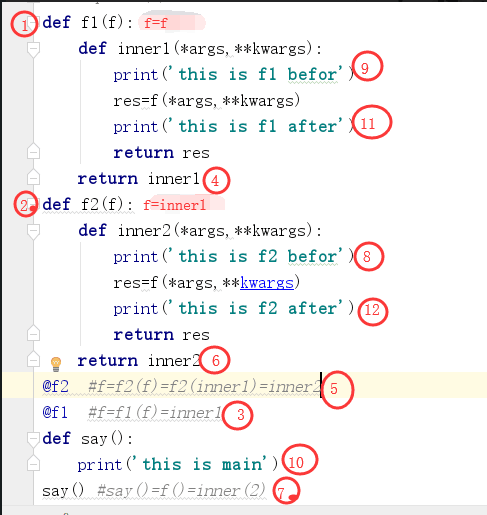
当然装饰器还有可能不止两个,但是你只要明白两个装饰器的原理,再多的装饰器的流程你都能搞清楚具体执行流程了。
五,生成器高级版
以前我在学生成器的时候学得比较简单,没想到现在回过头在看生成器相关的知识时,发现,卧槽,还能这么玩啊,当时我都懵了,现在跟大家分享一下下面几种生成器的例子。可能理解起来比较困难,估计有点抽象,但是还是很重要的。下面两道题,你先算一下答案是好多,然后自己运行一下,看看最终结果跟你想的差距。
1 def test(): 2 for i in range(4): 3 yield i 4 g=test() 5 g1=(i for i in g) 6 g2=(i for i in g1) 7 print(list(g1)) 8 print(list(g2))
下面是我画的流程分析,有一点抽象。需要提醒的是,生成器在前面并没有执行哦,只有在print(list(g1))的时候才开始从里面取值。

如果你实在难以理解,可以想象成在list(g1)的时候已经把g中的数据取完了,然后g,g1里面都没有值了,所以当g2来取值时,什么都没有了。
下面还有一个更加复杂的,理解起来更加困难,我觉得还是最好自己加断点调试一下。
1 def add(n,i): 2 return n+i 3 def test(): 4 for i in range(4): 5 yield i 6 g=test() 7 for n in [1,10]: 8 g=(add(n,i) for i in g) 9 print(list(g))
这道题的流程分析,理解起来,emmm,很困难。下面的流程图是我个人理解,加上调试得出的。希望能帮助到你吧。
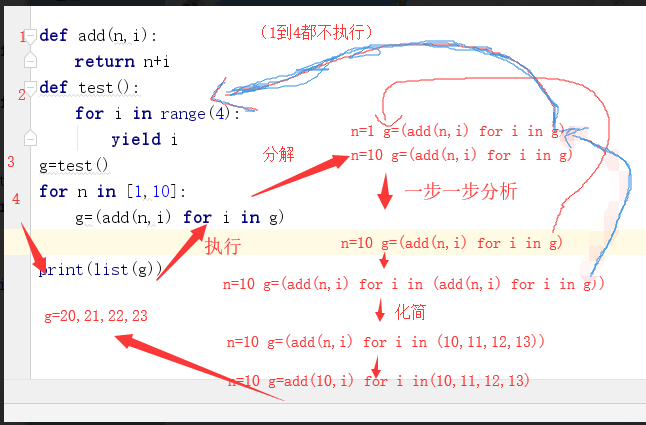
这道题理解确实有点麻烦,做这种题,需要把他先分解,然后一步一步分析。希望我这个很丑的流程图,能够让你理解起来容易一点吧。