这个以前在紫书贪心专题见过不过没注意,昨天做题遇见感觉很神哦。
通俗的来说就是为一群字符分配唯一一个对应的编码,为了方便识别规定任何一个编码都不可以是其他编码的前缀,也就是前缀码;
例如对于字符集 X={A(45),B(13),C(12),D(16),E(9),F(5)}, 其中括号内为出现的频率,一种很简单的编码是{000,001,010,011,100,101},这样所占的空间就是(45+13+12+16+9+5)*3=300,huffman就是使得占用的空间减小,比如{0,101,100,111,1101,1100},总长度是 45+3*13+3*12+3*16+4*9+4*5=224,是不是变小了呢,但是对于{0,1,00,01,10,11}这个编码来说尽管他很小但是是不正确的,如果收到了001,那究竟是AAB,CB还是AD呢,换句话说这样存在前缀的编码会产生混淆。
因此我们提出最优编码问题,给出N个字符以及各自的频率,每个字符赋予一个01编码,使得总长度最小。
huffman编码的核心就是从底至上来编码而不是从上往下,开始时每个字符对应着一个单独的叶子结点,权值就是频率,每次挑选权值最小的两颗子树合并,新树的权值是左右儿子的权值加上非左右儿子且在树上的叶子结点的权值,最后剩下一棵树时根节点的权值就是答案。
显然这样编码的话是一定满足没有前缀包含的情况发生的,因为所有的字符都位于叶子结点这是显而易见的。每合并两颗子树相对应的叶子结点也就增加的一层所以代价增加了SUM{当前所有叶子结点权值},让儿子加上这些就是当前结点的权值,因为要使得权值最小显然应该优先挑出最小的两个权值进行合并。
说到这里就显然了,这是石子合并问题,用一个优先队列就能算出最小的权值了。
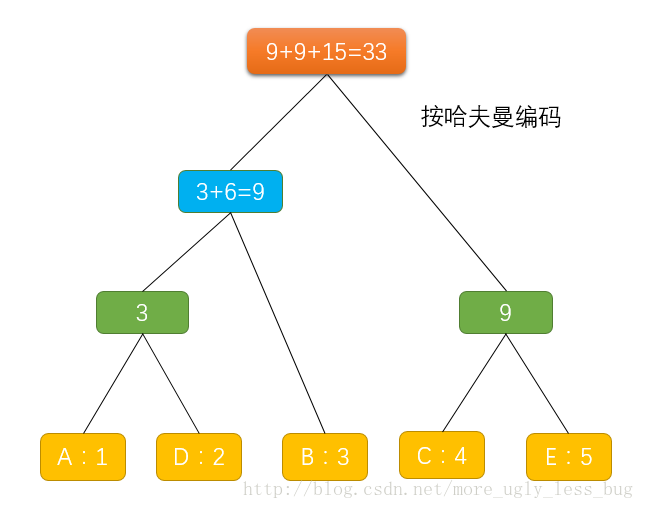
有一个变形是对于这串字符集必须使得对应的编码呈现非降序排列,求此时的最小权值,其实就是相邻石子合并问题,每次必须合并相邻的两堆石子。