1. 应用K-means算法进行图片压缩
from sklearn.datasets import load_sample_image
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.image as imgs
import sys
#读取图片
ch=load_sample_image("china.jpg")
plt.imshow(ch)
plt.show()
#观察图片
print('大小:',ch.size)
print('降低分辨率前的像素分布:',ch.shape)
print('内存:',sys.getsizeof(ch))
#图片降低分辨率
img=ch[::3,::3]
plt.imshow(img)
print('降低分辨率后的像素分布:',img.shape)
plt.show()
#二维线性
x=img.reshape(-1,3)
#模型训练
model=KMeans(n_clusters=64).fit(x)
#预测值pre,聚类点center
pre=model.predict(x)
print('像素分布:',pre)
center = model.cluster_centers_
print("颜色点:",center)
#压缩后的图片
new_img=center[pre].reshape(img.shape)
plt.imshow(new_img.astype(np.uint8))
plt.show()
#对边修改前后
print('压缩前文件大小:',ch.size)
print('压缩前文件大小:',new_img.size)
print('压缩前内存大小:',sys.getsizeof(ch))
print('压缩后内存大小:',sys.getsizeof(new_img))
压缩前:

压缩后:



2. 观察学习与生活中可以用K均值解决的问题。、
根据nba球员进球率分析出场均得分能力,对于nba来说,出色的得分球员能让整支队伍处于乘风破浪的节奏上。拥有着快速的得分节奏意味着获胜的机会变大。
#研究NBA选手平均进球拿分的命中率预测场均得分情况
import pandas as pd
from numpy import *
import numpy as np
#导入nba球员数据
data = pd.read_excel("nba.xlsx")
name= data['球员'].values
data0 = data['投篮'].values
data1 = data['罚球'].values
data2 = data['三分'].values
data3 = data['得分'].values
datax = np.zeros([200,4])
datax[:,0]=data0
datax[:,1]=data1
datax[:,2]=data2
datax[:,3]=data3
print(datax.shape)
#假设聚簇为4,k值可变换
k=4
#创建一个多维数组来收集得分等级
dist = np.zeros([data.shape[0],datax.shape[1]+1])
#初始化质点中心
def initcent(x, k):
center = x[:k, :]
return center
#通过欧式距离选取出最接近均值的下标,放入dist多维数组中
def nearest(x, center):
a=[]
for j in range(k):
a.append(np.sqrt(sum((x-center[j, :]) ** 2)))
# print(a)
return a
def xclassify(x,dist, center):
for i in range(x.shape[0]):
dist[i,:k]=nearest(x[i,:],center)
dist[i, k] = np.argmin(dist[i,:k])
return dist
#迭代聚簇点
def kcmean(x, dist, center,k):
centerNew = np.zeros([k,center.shape[1]])
for c in range(k):
p = []
q = np.where(dist[:,k] == c)
for i in range(datax.shape[1]):
n = mean(x[q][:,i].reshape(-1,1))
p.append(n)
# print(p)
# print(centerNew[c])
if all(centerNew[c]!=p):
centerNew[c] = p
return np.array(centerNew)
#通过多次迭代质点,确定最优质点
center = initcent(datax,k)
while True:
xclas = xclassify(datax, dist, center)
centerNew=kcmean(datax, xclas, center,k)
if all(center == centerNew):
break
else:
center = centerNew
#打印10条数据
for i in range(10):
print('球员:',name[i],',''场均得分能力等级:',dist[i,k])
#通过图例确定质点的含义
plt.scatter(dist[:,k], datax[:,3], c=array(xclas[:,k]), s=50, cmap='rainbow', marker='p', alpha=0.5)
plt.show()
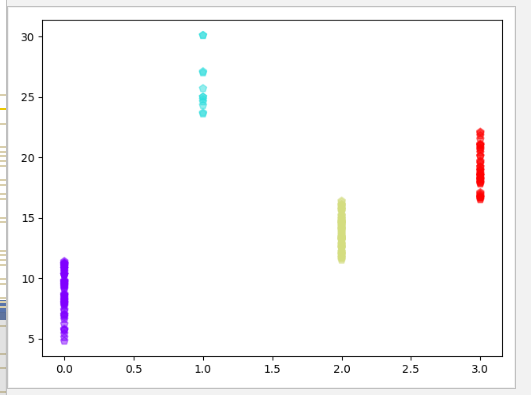
#得分能力等级为1 则为得分能很强,4则为比较强,2则为比较好,0则为一般
