1 简介
这篇论文的主要贡献是两个神经网络结构。一个是现在常见的 BiLSTM + CRF,另一个是受到 shift-reduce parsers 启发的网络结构,其中利用了 Stack-LSTM 来计算中间内容的向量表示。话不多说,直接切入讲网络结构,然后以 QA 的形式讨论其他细节。
2 LSTM-CRF Model
网络结构如下,不过这里其实少了一层 Linear 层。在论文 2.3 节中,说到 "These representations are concatenated and linearly projected onto a layer whose size is equal to the number of distinct tags"。在 BiLSTM 层和 CRF 层中间,还需要一个 Linear 层,将 BiLSTM 输出的维度映射成 CRF 需要的维度。CRF 需要的维度是多少呢? 论文说和不同标签的个数相等。前面的网络学习到的其实是 CRF 层中的 emission 分数!! 损失函数利用 CRF 的损失函数即可。

3 Transition-Based Chunking Model
3.1 transition-based parsers
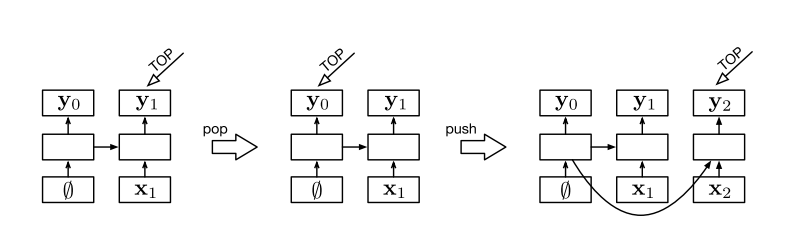
这个方法受到 transitioni-based parsers 的启发,作者设计了如下动作。借助两个栈,Stack 和 Buffer,定义了三种动作来 parse 一个句子。SHIFT 将 Buffer 中的栈顶元素移入 Stack。REDUCE(y) 将 Stack 中的所有元素向量化之后移入 Out,Out 只增多一个元素。Figure 2 还保留了 S,不过在 Figure 3 中是全部移除的。OUT 直接将 Buffer 中的栈顶元素带着标签向量化之后移入 Out。(ps. 这里说的三种动作并非三个动作,这三种动作中 REDUCE(y) 可以衍生出很多个动作,比如 REDUCE(PER), REDUCE(LOC) 等)
"Mark Watney visited Mars",它的标注可以是:"B-PER I-PER O B-LOC"。如果我们要使用这个方法,我们不能使用这种标注格式了,在输入之前,需要将标记序列转化为动作序列。作者没有给出处理方法,我这里提供一个将 BIO 转为动作序列的思路。第一步,在每个实体的最后插入一个 REDUCE(y),其中 y 对应实体的类型。第二步,将所有的 B-X, I-X 直接转为 SHIFT。第三步,将 O 转为 OUT。比如:
- Mark Watney visited Mars
- B-PER I-PER O B-LOC
- B-PER I-PER REDUCE(PER) O B-LOC REDUCE(LOC)
- SHIFT SHIFT REDUCE(PER) O SHIFT REDUCE(LOC)
- SHIFT SHIFT REDUCE(PER) OUT SHIFT REDUCE(LOC)

3.2 Stack-LSTM
[2] 介绍了一个使用了栈的 LSTM。传统的 LSTM 中,一个神经元输入的隐状态来自上一个神经元的输出。Stack-LSTM 特别之处在于使用了栈,一个神经元输入的隐状态来自于栈顶元素。栈顶元素可以是前面任意一步的结果。
3.3 Model
接下来就是模型了。
论文中 3.1 节介绍的有点太概括了,我这里是看 [1] 理解的网络结构。3.1 节说将四个部分输入到 Stack-LSTM 进行向量化(取 LSTM 最后的输出),这四部分是:Stack, Buffer, Output, History。
- Stack 和 Buffer 的输入就是词向量,需要词的 Embedding。
- Output 输入的向量在 3.2 节中介绍了,3.2 节说
SHIFT的时候,将 Stack 中的词向量带着对应的REDUCE(y)中的标签y一起,输入到 LSTM。这里的标签y还需要进行向量化,因此需要一个标签的 Embedding。 - History,存放的是执行动作的历史,所以这里又需要动作的 Embedding。
对于每一个步,可以计算四个部分的向量,将这四个部分的向量拼接起来,用一个 Linear 映射到动作空间,最后使用 Softmax[3] 来计算损失函数。对于预测,可以取动作空间概率最大的那个动作,直到 buffer 和 stack 同时为空,即终止。对于训练,可以使用 softmax 损失函数,最后对每一步的 softmax 损失进行求和得到总的损失。
3.3.1 例子
这个部分结合 "Mark Watney visited Mars",分析每个动作对四个部分的影响。
- Stack,当
SHIFT时,需要 push 操作。当REDUCE(y)时,需要 pop 全部。同时,将 pop 出来的词向量加上标签 y 的向量(这里要做一次 Embedding),输入到一个 LSTM 中,获得最后的输出,放入 Output。 - Buffer,开始的时候,按照句子的逆序 push,最先是 Mars,最后是 Mark。当
SHIFT时,pop 一次,更新 Buffer 的向量。当OUTPUT的时候,执行相同的操作。所以,Buffer 这里,可以说是一开始就把所有的中间结果计算出来,然后逆序取出。 - Output,这里直接使用普通的 LSTM 即可,因为每次都是 push,不会有 pop。
- History,这里同样使用普通的 LSTM,每次执行操作,将操作做一次 Embedding,然后输入 LSTM。
4 实验分析
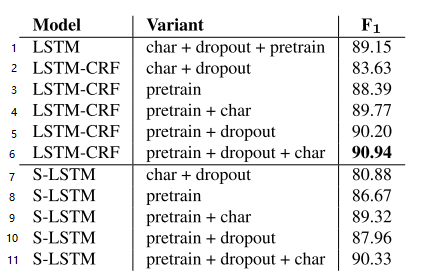
对比第 1、6 条,CRF 可以提升一个百分点。对比第 2、5 条,预训练效果要显著比通过 char 学习到的词向量好。对比第 2、5、6 条,叠加预训练向量和 char 学习到的向量,可以提高 F1。对比 (3, 5)、(8, 10)、(4, 6)、(9, 11),发现 dropout 提高了 F1,原文说 "We observe a significant improvement in our model's performance after using dropout",emmm,非常的 significant 嘛。以后训练模型的时候,dropout 用起来! 对比两个模型,发现 LSTM-CRF 显著比 S-LSTM 好,每一个变种的效果都好。
参考链接
[1] https://github.com/tianlinyang/stack-lstm-ner
[2] https://arxiv.org/pdf/1505.08075
[3] https://juejin.im/post/6844903620480073742