1. 基础
1.1 python导入
from pymongo import MongoClient #引入库
官方文档:http://api.mongodb.com/python/current/tutorial.html
mongo中存储的数据格式像json格式:
{ "_id" : ObjectId("5ab066a52514qeqwewqeq"), "updated_on" : "2018-03-20 09-40-48", "configuration_date" : "2018-03-20 09-57-30", "updated_by" : "xxxxx", "element_content" : { "type_" : "DYNAMIC", "hostname" : "TDC5_SVR-C8750-S9", "value_port" : "Port-channel1", "vlan" : "307", "mac_address" : "0000.0a09.ah01" } }
1.2 连接数据库
client=MongoClient(192.163.1.22, 88) #创建连接 client["admin"].authenticate(username,pwd,mechanism='SCRAM-SHA-1') #验证身份,连接DB服务器 db=client["mysqlserver"] #根据名字连接我的数据库,或者client.mysqlserver table=db["tablename"] #表名,或者db.tablename
1.3 关闭连接
db.close() #关闭数据库连接
2 查询数据
2.1 find()
content = table.find({"name":"kate","key":"aaa"},{'name' : 1, 'age' : 1, 'skills' : 1}) #根据表里的字段查找,第一个{}放where条件,第二个{}指定哪些列显示,0不显示,1显示
返回数据是一个迭代对象,若想取出迭代对象的内容,需要使用
for i in content:
print i
以下则为打印内容
{'_id': ObjectId('342srfserer232er45'), 'name': 'daisy1', 'age': 25, 'skills': 'xxx'}
{'_id': ObjectId('342srfserer232er46'), 'name': 'daisy2', 'age': 22, 'skills': 'xxx'}
{'_id': ObjectId('342srfserer232er47'), 'name': 'daisy3', 'age': 23, 'skills': 'xxx'}
2.2 find_one()
table.fine_one({"age": 33})
返回一条数据:
{'_id': ObjectId('342srfserer232er45'), 'name': 'daisy1', 'age': 25, 'skills': 'xxx'} #只返回一条数据
2.3 操作符
table.find({ '$or' : [{'name' : 'hurry'}, {'age' : 18}] },{'name' : 1, 'age' : 1, 'skills' : 1}) #or 查询
table.find({'age' : {'$gte' : 20, '$lte' : 30}}) #( <, <=, >, >= )分为是( $lt, $lte, $gt, $gte )
table.find({'age' : {'$in' : [10, 22, 26]}}) #$in ,$nin
table.find({"age":{"$in":(20,30,35)}}) #找出age是20、30、35的数据
table.find({"$or":[{"age":20},{"age":35}]}) #找出age是20或者age是35的数据
table.find({{"quantity":{"$in":[20,50]}}}) #查找quantity是20或者是50的数据
table.find({"quantity":{"$regex":"goo.d","$options":"$i"}}) #正则查询某个字段,忽略大小写
2.4 排序与去重
table.find(xxxxx).sort("name") #按照name进行排序 table.find(xxxxx).sort([("age",1)]) #按照age,升序排列。1为升序,-1降序
table.distinct("date") #表中date字段去重,去重后返回的数据已自动排列,返回的是去重字段的列表
2.5 翻页
table.find(xxxx).limit(20).skip(2) #limit每页显示20条数据,skip第2页
3. 插入数据
table.insert_one({"name":"lss","age":8})
table.insert_many( [ {"name":"lss","age":8}, {"name":"aaa","age":5} ] )
table.insert( [ {"name":"lss","age":8}, {"name":"aaa","age":5} ]) #多条数据时,不需要遍历,效率高
table.save({"name":"zhangsan","age":18}) #需要遍历列表,一个个插入
4. 更新数据
table.update({"name":"daisy"},{'$set':{"age":20}}) 更新name为daisy的数据,设置age=20
5.删除
table.remove({"date":111}) #删除表中字段date的值等于111的数据
6.聚合框架
6.1 定义:
Aggregate是mongoDB提供的众多工具中的比较重要的一个,类似于SQL语句中的group by。聚合工具可以可以让开发人员直接使用mongDB原生的命令操作数据库中的数据,并且按照要求进行聚合。
MongoDB提供了三种执行聚合的方法:Aggregation Pipleline,map-reduce功能和 Single Purpose Aggregation Operations
其中用来做聚合操作的几个函数是
-
aggregate(pipeline,options)指定 group 的 keys, 通过操作符$push/$addToSet/$sum等实现简单的 reduce, 不支持函数/自定义变量 -
group({ key, reduce, initial [, keyf] [, cond] [, finalize] })支持函数(keyf)mapReduce的阉割版本 -
mapReduce -
count(query) -
distinct(field,query)
6.2 Aggregation Pipleline
管道是将上一个命令输出的数据作为下一个命令的参数。
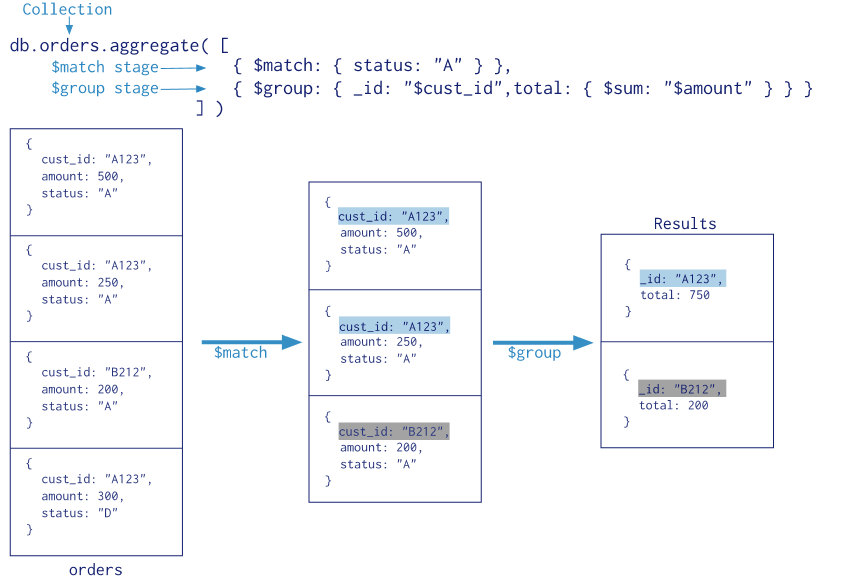
db.collection.aggregate([{$match:{status:"A"}}, {$group:{_id:"$cust_id", total:{$sum:"$amount"}}}])
aggregate是一个数组,其中包含多个命令。通过遍历pipleline数组对collection中的数据进行操作。
$match :查询条件
$group :聚合的配置
-
_id代表你想聚合的数据的主键,上述数据中,你想聚合所有cust_id相同的条目的amount的总和,那_id即被设置为cust_id。_id为必须,你可以填写一个空值。 -
total代表你最后想输出的数据之一,这里total是每条结果中amount的总和。 -
$sum是一个聚合的操作符,另外的操作符你可以在官方文档中找到。上图中的命令表示对相同主键(_id)下的amount进行求和。如果你想要计算主键出现的次数,可以把命令写成如下的形式{$sum: 1}
所有的数据先经过$match命令,只留下了status为A的数据,接着,对筛选出的数据进行聚合操作,对相同cust_id的数据进行计算amount总和的操作,最后输出结果。
pipeline 支持的方法
-
$geoNeargeoNear命令可以在查询结果中返回每个点距离查询点的距离 -
$group指定 group 的_id(key/keys) 和基于操作符($push/$sum/$addToSet/...) 的累加运算 -
$limit限制条件 -
$match输入过滤条件 -
$out将输出结果保存到collection -
$project修改数据流中的文档结构 -
$redact是$project/$match功能的合并 -
$skip 跳过 -
$sort对结果排序 -
$unwind拆解数据
db[collection].aggregate(
[{"$match": {"configuration_date":configuration_date}},{"$group": {"_id": {"element_content":"$element_content"}}}]
)
#group 是指定格式,输出是什么样子的格式
{
"_id":
{
"element_content":xxxxxx
}
}