在HBase客户端到服务端的通信过程中,可能会碰到各种各样的异常。例如有几种常见导致重试的异常:
-
待访问Region所在的RegionServer发生宕机,此时Region已经被挪到一个新的RegionServer上,但由于客户端meta缓存的因素,首次RPC请求仍然访问到了老的RegionServer上。后续将重试发起RPC。
-
-
访问meta表或者ZooKeeper异常。
首先来了解一下HBase常见的几个超时参数:
-
hbase.rpc.timeout:表示单次RPC请求的超时时间,一旦单次RPC超时超过该时间,上层将收到TimeoutException。默认为60000,单位毫秒。
-
hbase.client.retries.number:表示调用API时最多容许发生多少次RPC重试操作。默认为35,单位次。
-
hbase.client.pause:表示连续两次RPC重试之间的sleep时间,默认100,单位毫秒。注意,HBase的重试sleep时间是按照随机退避算法来计算的,若hbase.client.pause=100,则第一次RPC重试前将休眠100ms左右 ,第二次RPC重试前将休眠200ms左右,第三次RPC重试前将休眠300ms左右,第四次重试将休眠500ms左右,第五次重试前将休眠1000ms左右,第六次重试则将休眠2000ms左右....也就是重试次数越多,则休眠的时间会越来越长。因此,若按照默认的hbase.client.retries.number=35的话,则可能长期卡在休眠和重试两个步骤中。
-
hbase.client.operation.timeout:表示单次API的超时时间,默认为1200000,单位毫秒。注意,get/put/delete等表操作称之为一次API操作,一次API可能会有多次RPC重试,这个operation.timeout限制的是 API操作的总超时。
假设某业务要求单次HBase的读请求延迟不超过1秒,那么该如何设置上述4个超时参数呢?
首先,很明显hbase.client.operation.timeout应该设成1秒。
其次,在SSD集群上,如果集群参数设置合适且集群服务正常,则基本可以保证p99延迟在100ms以内,因此hbase.rpc.timeout设成100ms。
这里,hbase.client.pause用默认的100ms。
最后,在1秒钟之内,第一次PRC耗时100ms,休眠100ms;第二次RPC耗时100ms,休眠200ms;第三次RPC耗时100ms,休眠300ms;第四次RPC耗时100ms,休眠500ms。因此,在hbase.client.operation.timeout内,至少可执行4次RPC重试,真实的单次 RPC耗时可能更短(因为有hbase.rpc.timeout保证了单次RPC最长耗时),所以hbase.client.retries.number可以稍微设大一点(保证在1秒内有更多的重试,从而提高请求成功的概率),设成6次。
2.CAS接口
CAS接口是Region级别串行执行的,吞吐受限。HBase客户端提供一些重要的CAS(Compare And Swap)接口,例如:
boolean checkAndPut(byte[] row, byte[] family,byte[] qualifier,byte[] value, Put put)
long incrementColumnValue(byte[] row,byte[] family,byte[] qualifier,long amount)
这些接口在高并发场景下,能很好的保证读取写入操作的原子性。例如有多个分布式的客户端同时更新一个计数器count,则可以通过increment接口来保证任意时刻只有一个客户端能成功原子地执行count++操作。
但是需要特别注意的一点是,这些CAS接口在RegionServer这边是Region级别串行执行的。也就是说同一个Region内部的多个CAS操作是严格串行执行的,不同Region间的多个CAS操作可以并行执行。
这里可以简要说明一下CAS(以checkAndPut为例)的设计原理:
-
服务端首先需要拿到Region的行锁(row lock),否则容易出现两个线程同时修改一行数据的情况,从而破坏了行级别的原子性。
-
等待该Region内的所有写入事务都已经成功提交并在mvcc上可见。
-
通过get操作拿到需要check的行数据,进行条件检查。若条件不符合,则终止CAS。
-
将checkAndPut的put数据持久化。
-
释放第1步拿到的行锁。
关键在于第2步,必须要等所有正在写入的事务成功提交并在mvcc上可见。由于branch-1的HBase是写入完成时,是先释放行锁,再sync WAL,最后推mvcc(写入吞吐更高)。所以,第1步拿到行锁之后,若跳过第2步则可能未读取到最新的版本,从而导致以下情况的发生:
两个客户端并发对x=100这行数据进行increment操作时:
-
客户端A读取到x=100,开始进行increment操作,将x设成101。
-
注意此时客户端A行锁已释放,但A的Put操作mvcc仍不可见。客户端B依旧读到老版本x=100,进行increment操作,又将x设成101。
这样,客户端认为成功执行了两次increment操作,但是服务端却只increment了一次,导致语义矛盾。
因此,对那些依赖CAS(Compare-And-Swap: 指increment/append这样的读后写原子操作)接口的服务,需要意识到这个操作的吞吐是受限的,因为CAS操作本质上Region级别串行执行的。当然,在HBase2.x上已经调整设计,对同一个Region内的不同行可以并行执行CAS,这大大提高的Region内的CAS吞吐。
3.Scan Filter设置
HBase作为一个数据库系统,提供了多样化的查询过滤手段。最常用的就是Filter,例如一个表有很多个列簇,用户想找到那些列簇不为C的数据。那么,可设计一个如下的Scan:
Scan scan = new Scan;
scan.setFilter(new FamilyFilter(CompareOp.NOT_EQUAL, new BinaryComparator(Bytes.toBytes("C"))));
如果想查询列簇不为C且Qualifier在[a, z]区间的数据,可以设计一个如下的Scan:
Scan scan = new Scan;
FamilyFilter ff = new FamilyFilter(CompareOp.NOT_EQUAL, new BinaryComparator(Bytes.toBytes("C")));
ColumnRangeFilter qf = new ColumnRangeFilter(Bytes.toBytes("a"), true, Bytes.toBytes("b"), true);
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL, ff,qf);
scan.setFilter(filterList);
上面代码使用了一个带AND的FilterList来连接FamilyFilter和ColumnRangeFilter。
有了Filter,大量无效数据可以在服务端内部过滤,相比直接返回全表数据到客户端然后在客户端过滤,要高效很多。但是,HBase的Filter本身也有不少局限,如果使用不恰当,仍然可能出现极其低效的查询,甚至对线上集群造成很大负担。后面将列举几个常见的例子。
(1)PrefixFilter
PrefixFilter是将rowkey前缀为指定字节串的数据都过滤出来并返回给用户。例如,如下scan会返回所有rowkey前缀为'def'的数据。注意,这个scan虽然能拿到预期的效果,但却并不高效。因为对于rowkey在区间(-oo, def)的数据,scan会一条条 依次扫描一次,发现前缀不为def,就读下一行,直到找到第一个rowkey前缀为def的行为止,代码如下:
Scan scan = new Scan;
scan.setFilter(new PrefixFilter(Bytes.toBytes("def")));
这主要是因为目前HBase的PrefixFilter设计的相对简单粗暴,没有根据具体的Filter做过多的查询优化。这种问题其实很好解决,在scan中简单加一个startRow即可,RegionServer在发现scan设了startRow,首先寻址定位到这个startRow,然后从这个位置开始扫描数据,这样就跳过了大量的(-oo, def)的数据。代码如下:
Scan scan = new Scan;
scan.setStartRow(Bytes.toBytes("def"));
scan.setFilter(new PrefixFilter(Bytes.toBytes("def")));
当然,更简单直接的方式,就是将PrefixFilter直接展开成扫描[def, deg)这个区间的数据,这样效率是最高的,代码如下:
Scan scan = new Scan;
scan.setStartRow(Bytes.toBytes("def"));
scan.setStopRow(Bytes.toBytes("deg"));
在设置StopRow的时候,可以考虑使用字符“~”拼接,因为hbase rowkey是以ascii码来排序的,ascii码中常见字符排序是(0~9排序) < (A~Z大写字母排序) < (a~z小写字母排序) < (~),这里的“~”字符是比小写的z还要大(详细见https://baike.baidu.com/item/ASCII/309296?fromtitle=ascii%E7%A0%81&fromid=99077&fr=aladdin)。这时候比如我们查账号为987654321的所有交易数据为可以如下设置:
Scan scan = new Scan;
scan.setStartRow(Bytes.toBytes("987654321"));
scan.setStopRow(Bytes.toBytes("987654321~"));
此外,如果rowkey中变态的还包含了中文,“~”字符也可能不能完全包含所有的数据,这时候可以将字符“~”换成十六进制的0xFF,将0xFF转为String类型,拼接到账号后面。
(2)PageFilter
在HBASE-21332中,有一位用户说,他有一个表,表里面有5个Region,分别为(-oo, 111), [111, 222), [222, 333), [333, 444), [444, +oo)。表中这5个Region,每个Region都有超过10000行的数据。他发现通过如下scan扫描出来的数据居然超过了3000行:
Scan scan = new Scan;
scan.withStartRow(Bytes.toBytes("111"));
scan.withStopRow(Bytes.toBytes("4444"));
scan.setFilter(new PageFilter(3000));
乍一看确实很诡异,因为PageFilter就是用来做数据分页功能的,应该要保证每一次扫描最多返回不超过3000行。但是需要注意的是,HBase里面Filter状态全部都是Region内有效的,也就是说,Scan一旦从一个Region切换到另一个Region之后, 之前那个Filter的内部状态就无效了,新Region内用的其实是一个全新的Filter。具体这个问题来说,就是PageFilter内部计数器从一个Region切换到另一个Region之后,计数器已经被清0。因此,这个Scan扫描出来的数据将会是:
-
在[111,222)区间内扫描3000行数据,切换到下一个region [222, 333)。
-
在[222,333)区间内扫描3000行数据,切换到下一个region [333, 444)。
-
在[333,444)区间内扫描3000行数据,发现已经到达stopRow,终止。
因此,最终将返回9000行数据。
理论上说,这应该算是HBase的一个缺陷,PageFilter并没有实现全局的分页功能,因为Filter没有全局的状态。我个人认为,HBase也是考虑到了全局Filter的复杂性,所以暂时没有提供这样的实现。当然如果想实现分页功能,可以不通过Filter,而直接通过limit来实现,代码如下:
Scan scan = new Scan;
scan.withStartRow(Bytes.toBytes("111"));
scan.withStopRow(Bytes.toBytes("4444"));
scan.setLimit(1000);
但是,如果你用的hbase不是1.4.0以上版本的,是没有setLimit()的。这个时候也有一种方式就是PageFilter+指定split策略来实现。
上面已经说了,如果要查询的数据分布在了多个region,PageFilter就不灵了。那我们就想办法让要查询的数据都可以在一个region里就行了。方式如下:
指定split策略为DelimitedKeyPrefixRegionSplitPolicy,该split策略的介绍如下:
A custom RegionSplitPolicy implementing a SplitPolicy that groups rows by a prefix of the row-key with a delimiter. Only the first delimiter for the row key will define the prefix of the row key that is used for grouping.This ensures that a region is not split “inside” a prefix of a row key.
I.e. rows can be co-located in a region by their prefix.
As an example, if you have row keys delimited with _ , like userid_eventtype_eventid, and use prefix delimiter _, this split policy ensures that all rows starting with the same userid, belongs to the same region.
也就是保证相同前缀的数据在同一个region中,例如rowKey的组成为:userid_timestamp_transno,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
也就是使用这个split策略,在做split找region的中心点时候,会将userid考虑在内 (更多内容可参考https://blog.csdn.net/fenglibing/article/details/82735979)。
这样子就完美解决了。
使用方式如下:
-
通过代码指定
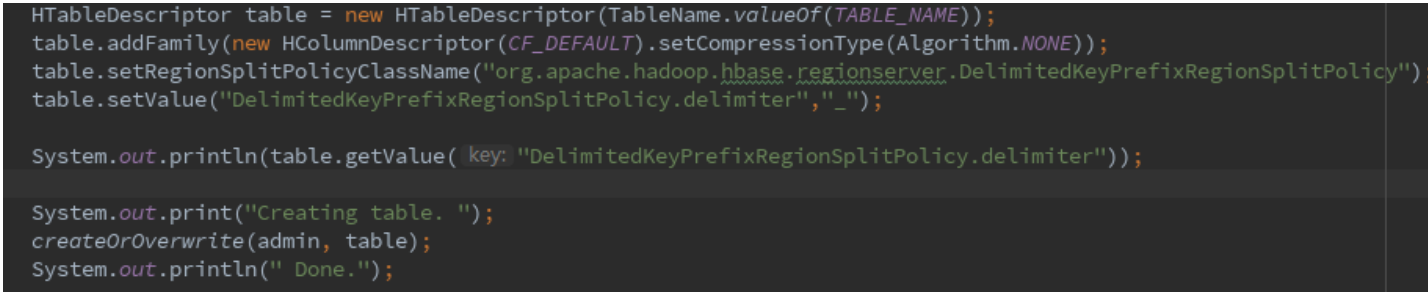
创建后查看表信息

-
hbase shell方式指定
disable 'test1'
drop 'test1'
create 'test1',{NAME => 'f1'},METADATA => {'DelimitedKeyPrefixRegionSplitPolicy.delimiter' => '_','SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.DelimitedKeyPrefixRegionSplitPolicy' }
创建后查看表信息

3.少量写和批量写
HBase是一种对写入操作非常友好的系统,但是当业务有大批量的数据要写入到HBase中时,仍会碰到写入瓶颈的问题。为了适应不同数据量的写入场景,HBase提供了3种常见的数据写入API:
-
table.put(put)——这是最常见的单行数据写入API,在服务端是先写WAL,然后写MemStore,一旦MemStore写满就flush到磁盘上。这种写入方式的特点是,默认每次写入都需要执行一次RPC和磁盘持久化。因此,写入吞吐量受限于磁盘带宽,网络带宽,以及flush的速度。但是,它能保证每次写入操作都持久化到磁盘,不会有任何数据丢失。最重要的是,它能保证put操作的原子性。
-
table.put(List<Put> puts)——HBase还提供了批量写入的接口,特点是在客户端缓存一批put,等凑足了一批put,就将这些数据打包成一次RPC发送到服务端,一次性写WAL,并写MemStore。相比第一种方式,省去了多次往返RPC以及多次刷盘的开销,吞吐量大大提升。不过,这个RPC操作的 耗时一般都会长一点,因此一次写入了多行数据。另外,如果List<put>内的put分布在多个Region内,则并不能保证这一批put的原子性,因为HBase并不提供跨Region的多行事务,换句话说,就是这些put中,可能有一部分失败,一部分成功,失败的那些put操作会经历若干次重试。
-
bulk load——本质是通过HBase提供的工具直接将待写入数据生成HFile,将这些HFile直接加载到对应的Region下的CF内。在生成HFile时,跟HBase服务端没有任何RPC调用,只有在load HFile时会调用RPC,这是一种完全离线的快速写入方式。bulk load应该是最快的批量写手段,同时不会对线上的集群产生巨大压力,当然在load完HFile之后,CF内部会进行Compaction,但是Compaction是异步的且可以限速,所以产生的IO压力是可控的。因此,对线上集群非常友好。
例如,我们之前碰到过一种情况,有两个集群,互为主备,其中一个集群由于工具bug导致数据缺失,想通过另一个备份集群的数据来修复异常集群。最快的方式,就是把备份集群的数据导一个快照拷贝到异常集群,然后通过CopyTable工具扫快照生成HFile,最后bulk load到异常集群,就完成了数据的修复。
另外的一种场景是,用户在写入大量数据后,发现选择的split keys不合适,想重新选择split keys建表。这时,也可以通过Snapshot生成HFile再bulk load的方式生成新表。
4.业务发现请求延迟很高,但是HBase服务端延迟正常
某些业务发现HBase客户端上报的p99和p999延迟非常高,但是观察了HBase服务端这边的p99和p999延迟则正常。这种情况一般需要观察HBase客户端这边的监控和日志。按照我们的经验,一般来说,有这样一些常见问题:
-
HBase客户端所在进程Java GC。由于HBase客户端作为业务代码的一个Java依赖,则如果业务进程一旦发生较为严重的Full GC就可能导致HBase客户端看到的延迟很高。
-
业务进程所在机器的CPU或者网络负载较高,对于上层业务来说一般不涉及磁盘资源的开销,所以主要看load和网络是否过载。
-
HBase客户端层面的bug,这种情况出现的概率不大,但也不排除有这种可能。
5.Batch数据量太大,导致异常
Batch数据量太大,可能导致MultiActionResultTooLarge异常。HBase的batch接口,容许用户把一批操作通过一次RPC发送到服务端,以便提升系统的吞吐量。这些操作可以是Put、Delete、Get、Increment、Append等等一系列操作。像Get或者Increment的Batch操作中,需要先把对应的数据块(Block)从HDFS中读取到HBase内存中,然后通过RPC返回相关数据给客户端。