IBM在spark summit上分享的内容,包括编译spark源码,运行spark时候常见问题(缺包、OOM、GC问题、hdfs数据分布不均匀等),spark任务堆/thread dump
目录

编译spark的问题
1.正确配置相关环境,如Maven,JRE
2.显示指定你要集成的功能
3.编译速度比较慢的话,可以根据自己的环境设置多core提高速度


spark运行时遇到的问题
1.在不清楚spark某些配置时候,可以在spark-submit时候使用--verbose打印出当前环境具体信息

2.缺少外部jar包问题,可以使用--packages参数指定缺失的jar包,--packages会先到本地maven仓库中找指定的jar包,如果本地仓库没有,就需要外部maven仓库下载。
所以一般在生成环境,--packages不一定合适。在jar包比较少的情况下,可以通过--jars指定,比较多的话,也可以通过指定class path。这两种方式都是比较合适的

2.Spark Driver OOM,默认driver内存一般都比较小(512M),建议自己指定。这个要根据实际情况设置

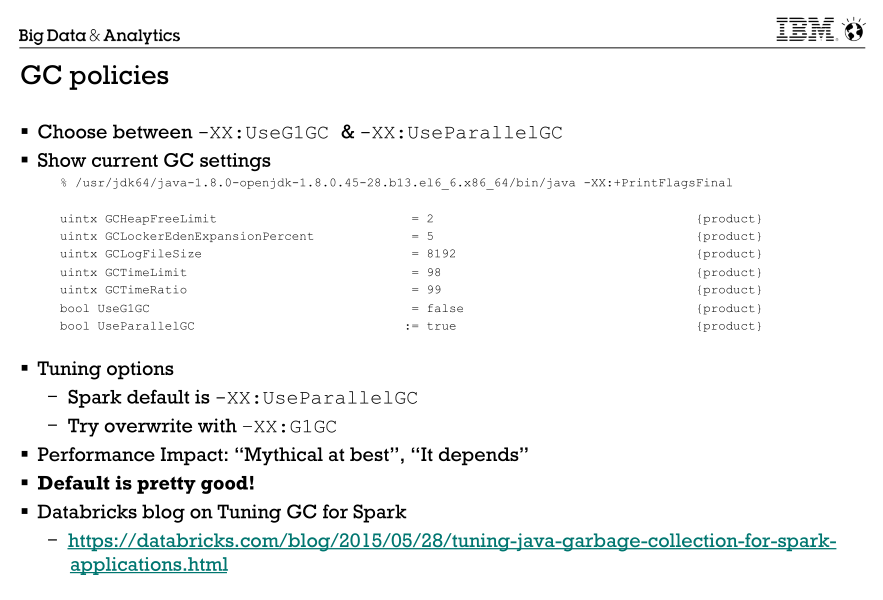
3.GC时间过长,首先应该从代码逻辑判断是否有问题,然后考虑内存是否太小,最后考虑GC算法,目前来说G1 GC是针对大堆(4G以上)首选的GC算法,databricks有一遍关于spark任务优化G1 GC的文章写的很不错,链接在下面。


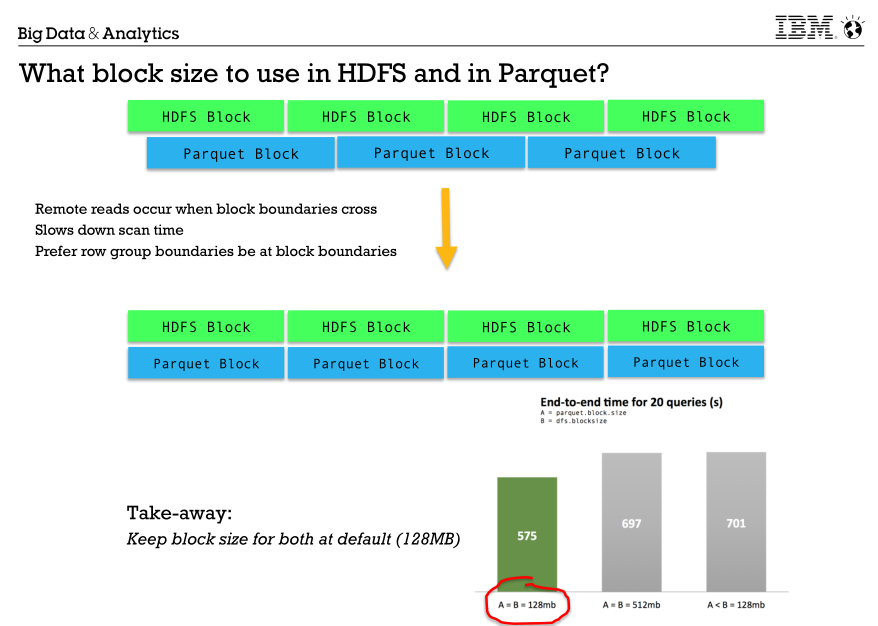
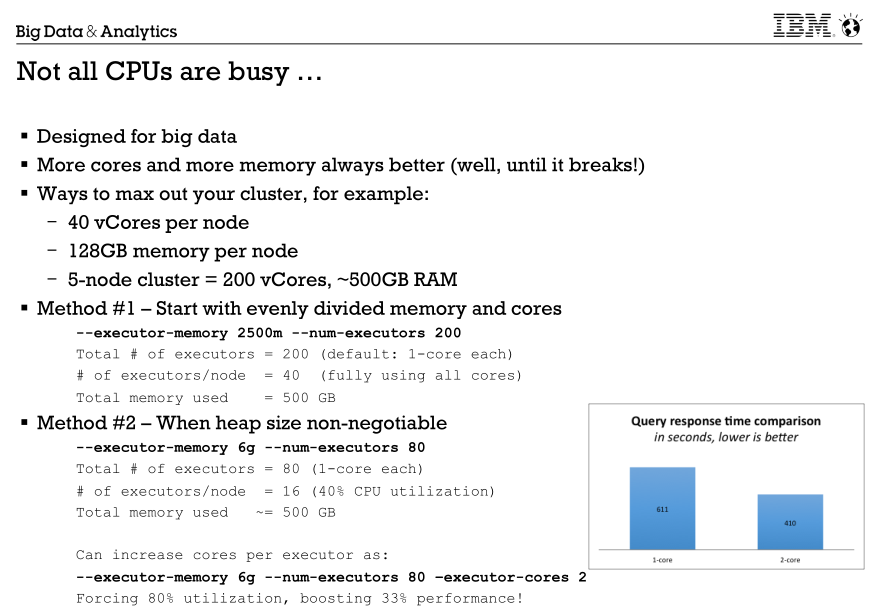
4.关于spark任务资源的问题,如何最大化利用资源
5.关于spark的"scratch" ,尽量不要使用默认的/tmp,图中描述的比较详细了。

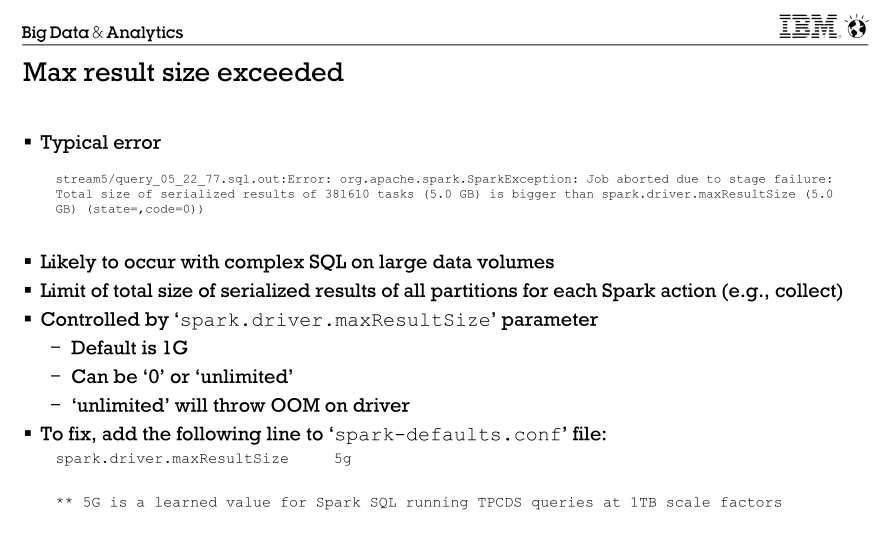
6.这种问题一般是用户在spark-sql中直接查询返回的数据量过大造成。也可能是用户应用中使用了拉取数据到driver端的API(例如:collect、show)。
解决方法:用户应该考虑拉取数据到driver端是否合理?如果不合理,增加过滤条件或者采用insert overwrite directory命令解决;如果合理,则适当增加spark.driver.maxResultSize的大小。