第二部分:数据结构与算法
一、数据结构
1、数组、链表、栈、队列的应用
(1)数组
优点在于:
- 构建非常简单
- 能在 O(1) 的时间里根据数组的下标(index)查询某个元素
缺点在于:
- 构建时必须分配一段连续的空间
- 查询某个元素是否存在时需要遍历整个数组,耗费 O(n) 的时间(其中,n 是元素的个数)
- 删除和添加某个元素时,同样需要耗费 O(n) 的时间
(2) 链表
单链表:链表中的每个元素实际上是一个单独的对象,而所有对象都通过每个元素中的引用字段链接在一起。
双链表:与单链表不同的是,双链表的每个结点中都含有两个引用字段。
链表的优点:
- 链表能灵活地分配内存空间;
- 能在 O(1) 时间内删除或者添加元素,前提是该元素的前一个元素已知,当然也取决于是单链表还是双链表,在双链表中,如果已知该元素的后一个元素,同样可以在 O(1) 时间内删除或者添加该元素。
链表的缺点是:
- 不像数组能通过下标迅速读取元素,每次都要从链表头开始一个一个读取;
- 查询第 k 个元素需要 O(k) 时间。
应用场景:如果要解决的问题里面需要很多快速查询,链表可能并不适合;如果遇到的问题中,数据的元素个数不确定,而且需要经常进行数据的添加和删除,那么链表会比较合适。而如果数据元素大小确定,删除插入的操作并不多,那么数组可能更适合。
(3)栈(Stack)
特点:栈的最大特点就是后进先出(LIFO)。对于栈中的数据来说,所有操作都是在栈的顶部完成的,只可以查看栈顶部的元素,只能够向栈的顶部压⼊数据,也只能从栈的顶部弹出数据。
实现:利用一个单链表来实现栈的数据结构。而且,因为我们都只针对栈顶元素进行操作,所以借用单链表的头就能让所有栈的操作在 O(1) 的时间内完成。
应用场景:在解决某个问题的时候,只要求关心最近一次的操作,并且在操作完成了之后,需要向前查找到更前一次的操作.
(4)队列(Queue)
特点:和栈不同,队列的最大特点是先进先出(FIFO),就好像按顺序排队一样。对于队列的数据来说,我们只允许在队尾查看和添加数据,在队头查看和删除数据。
实现:可以借助双链表来实现队列。双链表的头指针允许在队头查看和删除数据,而双链表的尾指针允许我们在队尾查看和添加数据。
应用场景:直观来看,当我们需要按照一定的顺序来处理数据,而该数据的数据量在不断地变化的时候,则需要队列来帮助解题。在算法面试题当中,广度优先搜索(Breadth-First Search)是运用队列最多的地方。
(5)双端队列(Deque)
特点:双端队列和普通队列最大的不同在于,它允许我们在队列的头尾两端都能在 O(1) 的时间内进行数据的查看、添加和删除。
实现:与队列相似,我们可以利用一个双链表实现双端队列。
应用场景:双端队列最常用的地方就是实现一个长度动态变化的窗口或者连续区间,而动态窗口这种数据结构在很多题目里都有运用。
2、二叉搜索树、红黑树、B树的应用
https://www.cnblogs.com/feng9exe/p/8920738.html
二、LeetCode
1、LeetCode常用真题剖析与算法
2、哈希表的原理与分析
https://blog.csdn.net/yyyljw/article/details/80903391
3、理解时间、空间复杂度,调用递归
https://blog.csdn.net/m0_37734999/article/details/78751882
4、经典排序算法的对比
https://www.cnblogs.com/zhaoshuai1215/p/3448154.html
三、集合排序
1、掌握Java集合体系结构和层次关系及设计理念
(1)"Collection" 和 "Collections"的区别:
"Collection"是集合类(Collection)的顶级接口,然而”Collections“是一个提供了一系列静态方法的集合工具类;
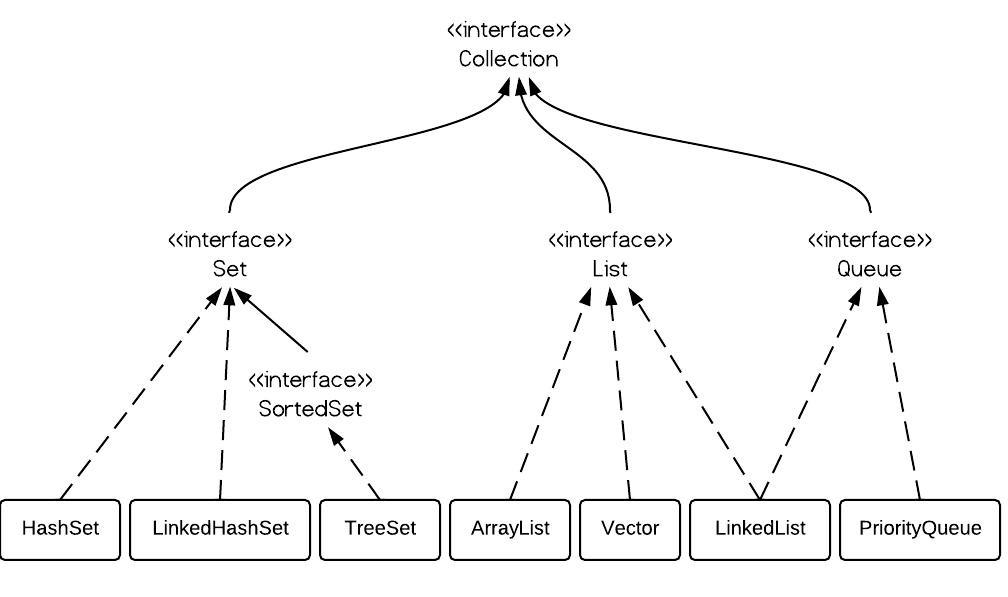
(2)Collection的类层次结构图
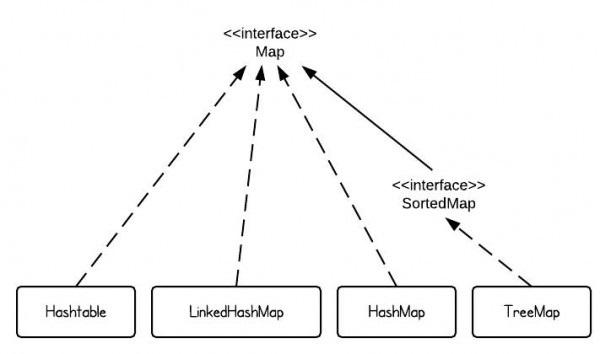
(3)Map的类层次结构图
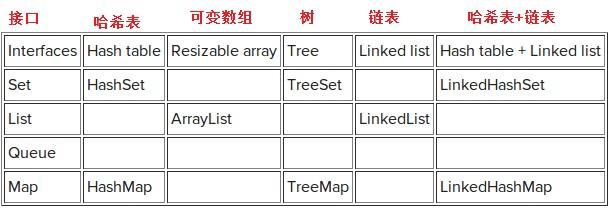
(4)总结
2、List、Set、Map的使用:集合框架设计思想还原,集合的继承扩展与详解
https://blog.csdn.net/yeshengchao/article/details/84000644
https://www.cnblogs.com/mlfz/p/10435954.html