倒排索引流程图:(有三个文件,里边有三句话,分别统计每个单词在每个文件中出现的次数)
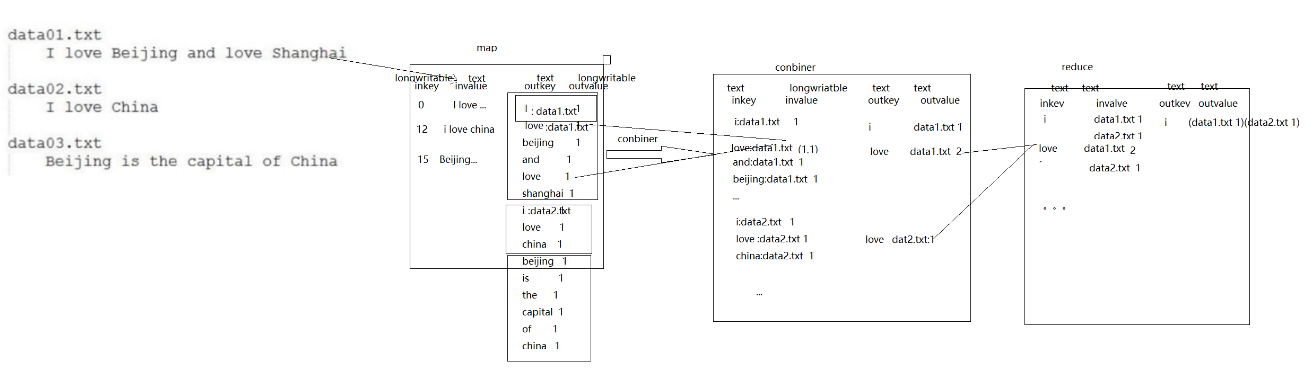
倒排索引数据流动过程分析图:

代码实现:
1 package com.zyx; 2 3 import org.apache.commons.lang.StringUtils; 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 import java.io.IOException; 16 public class App 17 { 18 public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>{ 19 @Override 20 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 21 String line = value.toString();//按行读取文件 22 String[] fields = StringUtils.split(line," ");//按空格进行分片 23 FileSplit fileSplit = (FileSplit) context.getInputSplit(); 24 String fileName = fileSplit.getPath().getName();//获取文件名 25 for(String field:fields) 26 { 27 context.write(new Text(field+"-->" + fileName),new IntWritable(1)); 28 } 29 } 30 } 31 public static class MyReduce extends Reducer<Text,IntWritable,Text,IntWritable>{ 32 @Override 33 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 34 int sum = 0; 35 for(IntWritable value:values) 36 { 37 sum+=value.get();//统计每个key值对应的value值 38 } 39 context.write(key,new IntWritable(sum)); 40 } 41 } 42 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 43 Configuration conf = new Configuration(); 44 conf.set("fs.defaultFS","hdfs://192.168.56.112:9000"); 45 Job job = Job.getInstance(conf); 46 job.setJarByClass(App.class); 47 job.setMapperClass(MyMap.class); 48 job.setMapOutputKeyClass(Text.class); 49 job.setMapOutputValueClass(IntWritable.class); 50 job.setReducerClass(MyReduce.class); 51 job.setMapOutputKeyClass(Text.class); 52 job.setMapOutputValueClass(IntWritable.class); 53 FileInputFormat.addInputPath(job,new Path("/idea/idea1/a.txt"));//读取HDFS上idea目录下的a.txt文件 54 FileInputFormat.addInputPath(job,new Path("/idea/idea1/b.txt")); 55 FileInputFormat.addInputPath(job,new Path("/idea/idea1/c.txt")); 56 FileOutputFormat.setOutputPath(job,new Path("/idea/idea2/out1.txt"));//将结果保存在idea目录下的out1目录下 57 job.waitForCompletion(true); 58 } 59 60 }