首先说一下我所理解的数据包。
我所理解的数据包就是用户和网站之间的一个交流,你把数据包传递到服务器,服务器再返回给你一个结果,这样你和网站就进行了一次交流。
而我们在网站里的操作,也是发送数据包请求来完成的。
那么我们如何去抓取我们所发送的数据包呢。
这里推荐一下火狐浏览器里的firebug插件。
首先我们百度搜索火狐浏览器,然后下载下来。
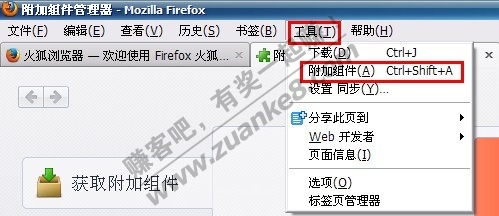
接着到菜单----附加组件----搜索firebug
<ignore_js_op>
<ignore_js_op>
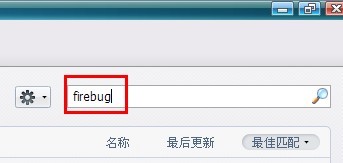
然后安装这个甲壳虫图片的就可以了。
<ignore_js_op>

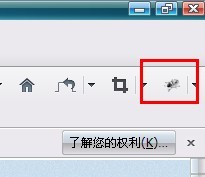
安装好了之后呢,我们看到浏览器右上角有一个灰色的甲壳虫图标,我们点击它,就成为亮色的了。
<ignore_js_op>
然后我们选择 网络---启动
<ignore_js_op>
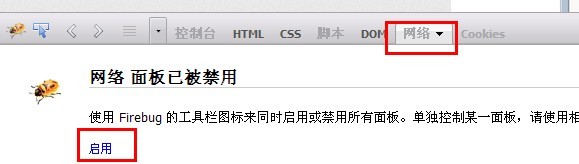
这样,这个firebug插件就已经开始对你的火狐浏览器抓包了。
这时候我们最好把“保持”给勾选上,因为有时候网页会跳转,那么跳转之前的数据包就会自动清空了,如果你保持的话,跳转之前的数据包也可以找到。
这里为什么推荐火狐浏览器里的firebug插件呢,因为firebug插件的抓包的时候,如果是缓存在电脑目录里的数据,他会显示灰色,这样我们分析数据包的时候直接跳过这些灰色的数据包就可以了。 而且火狐浏览器的插件也比较多。
<ignore_js_op>
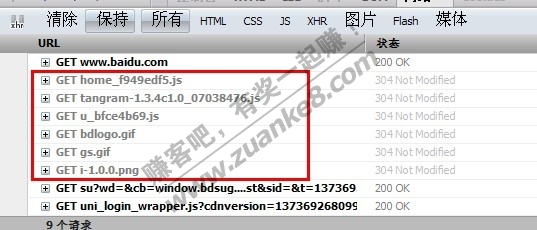
我们现在提交数据包的方式常见的有两类,一类是GET方式,一类是POST方式。 也有其他的方式,不过很少很少见到,主流还是GET和POST方式。
GET方式的数据包就跟我们平常访问网页一样,当我们打开http://www.baidu.com/就相当于提交了一个GET数据包。
那么以百度为例子。
我们抓取打开百度时候的数据包可以看到有很多一条一条的数据包,一般来说第一条就是我们访问的地址。我们把第一条展开看一下。
<ignore_js_op>
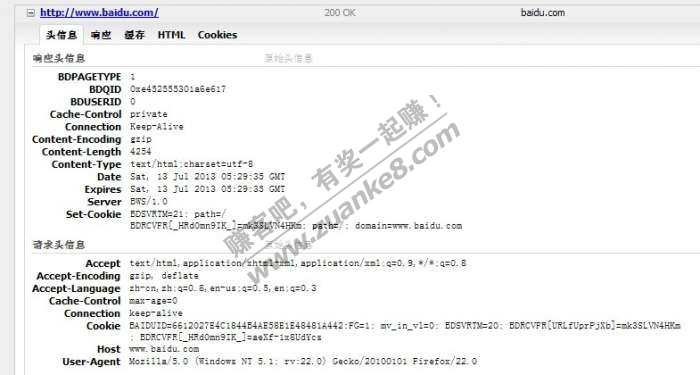
把请求头复制出来就是这样
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:22.0) Gecko/20100101 Firefox/22.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Cookie: BAIDUID=6612027E4C1844B4AE58E1E48481A442:FG=1; mv_in_vl=0; BDSVRTM=20; BDRCVFR[URLfUprPjXb]=mk3SLVN4HKm; BDRCVFR[_HRd0mn9IK_]=aeXf-1x8UdYcs
Connection: keep-alive
Cache-Control: max-age=0
最开始有一个GET,这个就是数据包的提交方式了,可以是GET或者POST。 后面是HTTP/1.1
而Host就是服务器名,可以是一个域名也可以是一个IP地址。
User-Agent,浏览器标识什么的,可以让服务器识别你的浏览器版本、语言、插件等等。
Accept,Accept-Language,Accept-Encoding,这里我就不多说了,有兴趣的朋友可以看看这个:http://jingyan.baidu.com/article/375c8e19770f0e25f2a22900.html
下面是Cookie,Connection和Cache-Control.
那么一个GET方式的数据包就是这样构成的。
然后我们看到数据包还有一个响应
<ignore_js_op>
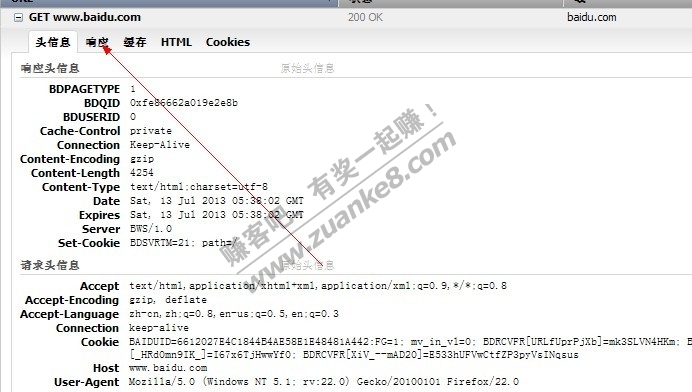
这里是我们访问了这个数据包后,服务器返回给我们的结果。
我们打开后看到是一对乱码
<ignore_js_op>
这个是很正常的,服务器只会给你返回一串数据,然后浏览器会根据数据来进行整理,然后展现给你,也就是你看到的百度页面。
那么到这里,就是一个完整的GET方式的数据包。
而POST数据包和GET数据包的本质是没有任何差别的,构成也很相似。
POST数据包只是为了来完成GET数据包没有办法完成的功能。
因为有时候我们要登录账号,登录账号要发送一个数据包给服务器,那如果是GET方式的话,登录的账号密码就会在浏览器地址栏里显示出来,这样就不太安全。
如果是POST数据包的话,就不会显示出来。
并且GET方式的数据包能查询的长度是有限的,好像最长是255字节,也可能会更多,反正不会超过某个限度,如果超过了这个限度的话,他会自动省去后面的字节。那么我们传递到服务器的时候,数据就损失了很多,服务器也会不知道我们是干嘛的。
而POST数据包就会没有这个问题。
下面抓一个百度的登录看一下。
<ignore_js_op>
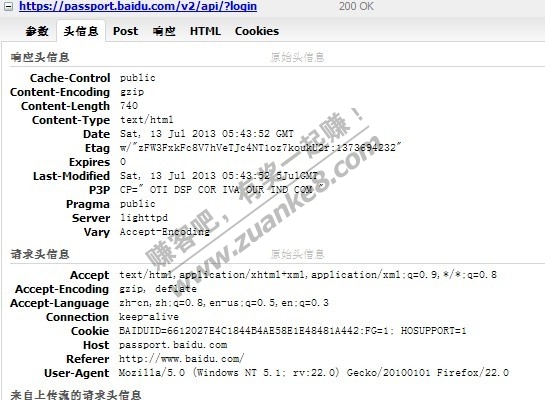
复制一下他的请求头信息
POST /v2/api/?login HTTP/1.1
Host: passport.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:22.0) Gecko/20100101 Firefox/22.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: http://www.baidu.com/
Cookie: BAIDUID=6612027E4C1844B4AE58E1E48481A442:FG=1; HOSUPPORT=1
Connection: keep-alive
那么我们可以看到,POST的请求头信息和GET的请求头是很相似的。只不过多了个POST数据。
<ignore_js_op>
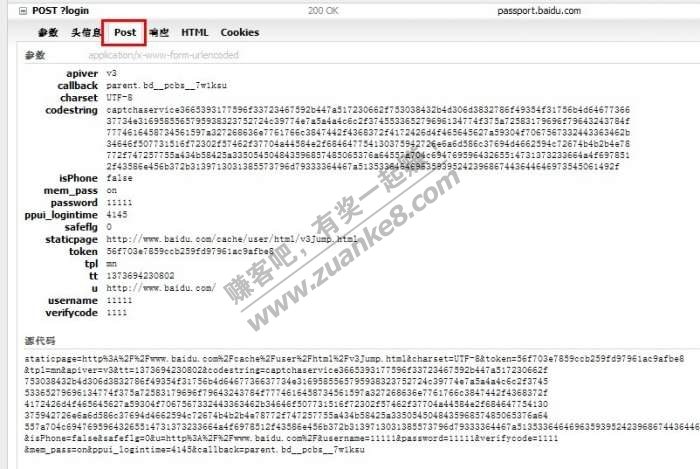
而这里我们可以看到,提交的数据是非常非常长的,如果用GET方式的话就可能不能完全提交到服务器。而且就算能提交,那么浏览器地址栏显示这么长一串内容,对用户的体验也是不太好的。反正我是看到地址栏满满的很长一段,就会不舒服。
言归正传,这里就是POST方式提交的数据。
然后其他的就跟GET方式差不多了, 头信息、返回响应什么的。
最后总结一下:
1、抓包用火狐浏览器的firebug插件,抓包的时候要记得勾选“保持”。
2、POST和GET方式的区别就在于长度问题,GET方式的长度是有限的,POST没有限制。
转载:http://bbs.125.la/thread-13851832-1-1.html