目录:
一、点估计
1、矩估计法
2、顺序统计量法
3、最大似然法
4、最小二乘法
二、区间估计
1、一个总体参数的区间估计:
- 总体均值的区间估计
- 总体比例的区间估计
- 总体方差的区间估计
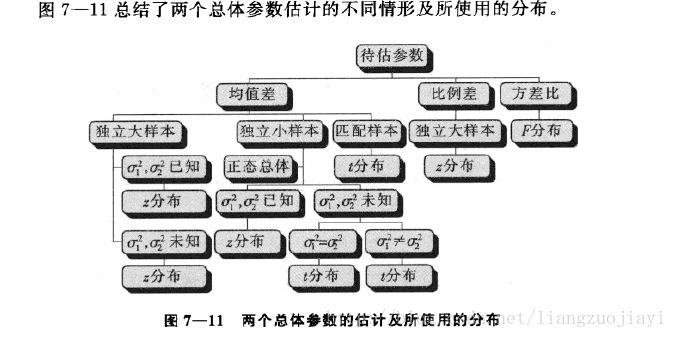
2、两个总体参数的区间估计:
- 两个总体均值之差的区间估计
- 两个总体比例之差的区间估计
- 两个总体方差比的区间估计
三、样本量的确定
1、估计总体均值时样本量的确定
2、估计总体比例时样本量的确定
一、点估计
点估计是用样本统计量来估计总体参数,因为样本统计量为数轴上某一点值,估计的结果也以一个点的数值表示,所以称为点估计。
点估计和区间估计属于总体参数估计问题。何为总体参数统计,当在研究中从样本获得一组数据后,如何通过这组信息,对总体特征进行估计,也就是如何从局部结果推论总体的情况,称为总体参数估计。
1、矩估计法
利用样本矩来估计总体中相应的参数。首先推导涉及感兴趣的参数的总体矩(即所考虑的随机变量的幂的期望值)的方程。然后取出一个样本并从这个样本估计总体矩。接着使用样本矩取代(未知的)总体矩,解出感兴趣的参数。从而得到那些参数的估计。
最简单的矩估计法是用一阶样本原点矩来估计总体的期望而用二阶样本中心矩来估计总体的方差。在寻找参数的矩法估计量时,对总体原点矩不存在的分布如柯西分布等不能用,另一方面它只涉及总体的一些数字特征,并未用到总体的分布,因此矩法估计量实际上只集中了总体的部分信息,这样它在体现总体分布特征上往往性质较差,只有在样本容量n较大时,才能保障它的优良性,因而理论上讲,矩法估计是以大样本为应用对象的。
如果总体中有 K个未知参数,可以用前 K阶样本矩估计相应的前k阶总体矩,然后利用未知参数与总体矩的函数关系,求出参数的估计量。
2、顺序统计量法
顺序统计量设![]() 是总体X的样本,将它们自小到大排成
是总体X的样本,将它们自小到大排成![]() ,则这个排列称为样本顺序统计量。抽取一个样本
,则这个排列称为样本顺序统计量。抽取一个样本![]() ,便有一组自小到大的观察值
,便有一组自小到大的观察值
3、最大似然法
4、最小二乘法
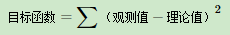
观测值就是我们的多组样本,理论值就是我们的假设拟合函数。目标函数也就是在机器学习中常说的损失函数,我们的目标是得到使目标函数最小化时候的拟合函数的模型。举一个最简单的线性回归的简单例子,比如我们有m个只有一个特征的样本:
样本采用下面的拟合函数: 。这样我们的样本有一个特征x,对应的拟合函数有两个参数θ0和θ1需要求出。
。这样我们的样本有一个特征x,对应的拟合函数有两个参数θ0和θ1需要求出。
目标函数为: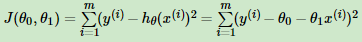
用最小二乘法做什么呢,使J(θ0,θ1)最小,求出使J(θ0,θ1)最小时的θ0和θ1,这样拟合函数就得出了。
参考:https://www.cnblogs.com/pinard/p/5976811.html
二、区间估计
区间估计是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。与点估计不同,进行区间估计时,根据样本统计量的抽样分布可以对样本统计量与总体参数的接近程度给出一个概率度量
1、一个总体参数的区间估计:转自:https://blog.csdn.net/liangzuojiayi/article/details/78043658
- 总体均值的区间估计

- 总体比例的区间估计

- 总体方差的区间估计
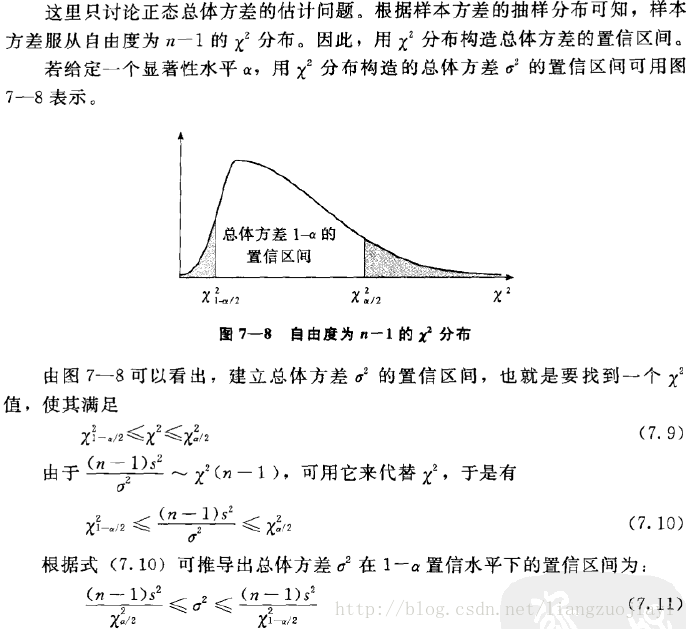

2、两个总体参数的区间估计:转自:https://blog.csdn.net/liangzuojiayi/article/details/78044718
- 两个总体均值之差的区间估计 大样本

小样本


- 两个总体比例之差的区间估计

- 两个总体方差比的区间估计

三、样本量的确定 : 转自:https://blog.csdn.net/rosa_zz/article/details/79562794
样本中个体的数目或组成抽样总体的单位数。
亦称必要样本单位数,是指满足调查目的要求的情况下,至少需要选择的样本单位数。
1、估计总体均值时样本量的确定
1.重复抽样
一旦确定了置信水平(1-α),Zα/2的值就确定了,对于给定的的值和总体标准差σ,就可以确定任一希望的允许误差所需要的样本容量。令E代表所希望达到的允许误差,即:
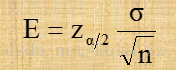
由此可以推到出确定样本容量的公式如下:
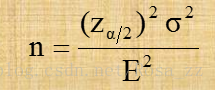
2.不重复抽样
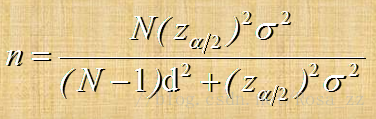
例:拥有MBA学位的研究生年薪的标准差大约为4000 元,假定想要估计年薪95%的置信区间,希望允许误差为10000 元,应抽取多大的样本容量?

2、估计总体比例时样本量的确定
1.重复抽样
一旦确定了置信水平(1-α),Zα/2的值就确定了。由于总体比例的值是固定的,所以允许误差由样本容量来确定,样本容量越大允许误差就越小。估计的精度就越好。因此,对于给定的的π值,就可以确定任一希望的允许误差所需要的样本容量。令E代表所希望达到的允许误差,即:
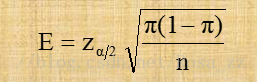
由此可以推导出重复抽样和无限总体抽样条件确定样本容量的公式如下:

2.不重复抽样
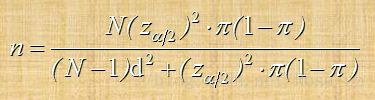
例:某社区想通过抽样调查了解居民参加体育活动的比率,如果把误差范围设定在5%,问如果以95%的置信水平进行参数估计,需要多大的样本?

确定样本容量的注意事项
一、在实际中采用不重复抽样,但常用重复抽样下的公式代替;
二、若和p未知,其处理方式是:
1.用过去近期的数据代替,
2.用样本数据代替,
3.取p=0.5或最接近0.5的值;
三、对同一总体,若求出的Nx,Np不等,这时取较大的作为必要样本容量,
以同时满足做两种调查的需要;
四、在实际工作中,常使用重复抽样下的简单随机抽样公式。