一 mini batch
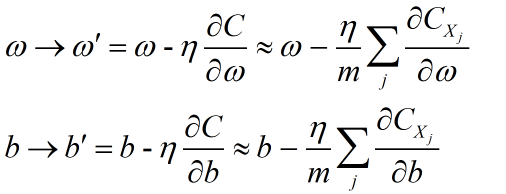
在使用梯度下降法训练神经网络时,如上左式,C是在整个训练样本的代价函数,当样本数量很大时,∂C/∂ω计算代价很大,因为我们需要在整个数据集上的每个样本上计算。在实践中,我们可以从数据集中随机采取少量样本,然后计算这些样本上的平均值,用来估计整体样本的值。(公式右)
假设训练集样本个数为n,随机采样个数为m。
1.使用整个训练集的优化算法成为批量(batch)或者确定性(deterministic)梯度算法。(m=n)
2.每次使用单个样本的优化算法被成为随机(stochastic)或者在线(online)算法。(m=1)
3.大多数用于深度学习的方法介于以上两者之间,使用一个以上而且又不是全部的训练样本,传统上,这些会被称为小批量(minibatch)或小批量随机(minibatch stochastic)方法,现在通常简单将他们成为随机(stochastic)算法。(1<m<n)
我们在选取m值得时候,一般选取为2的幂数,16,32,64,128,256等。并且小批量数据是从训练样本随机抽取的。
#将训练集数据打乱,然后将它分成多个适当大小的小批量数据 random.shuffle(training_data)
mini_batches = [training_data[k:k+mini_batch_size] for k in range(0,n,mini_batch_size)]
补充知识:小批量随机梯度下降的一个有趣动机是,只要没有重复使用样本,他将遵循着真实泛化误差的梯度。很多小批量随机梯度下降方法的实现都会打乱数据顺序一次,然后多次遍历数据来更新参数。第一次遍历时,每个小批量样本都用来计算真实泛化误差的无偏估计。第二次遍历时,估计将是有偏的,因为他重新抽取了已经用过的样本,而不是从和原先样本相同的数据生成分布中获取新的无偏的样本。 使用在线学习的方法,可以最小化泛化误差,随着数据集的规模的迅速增长,超越了计算能力的增速,机器学习应用每个样本只使用一次的情况变得原来 越常见,在使用一个非常大的训练集时,过拟合不在是问题,而欠拟合和计算效率变成了主要的问题。
因此在训练集数据较大的情况下,我们可以选取适当的抽样个数m,然后只遍历一次训练集。这样可以最小化泛化误差。
二 指数加权平均
指数加权平均它同样是用来给梯度下降增速的。 在我们的正常的梯度下降中,不论是mini batch还是 full batch,梯度下降的效果大概是下面这个样子的。

梯度下降算法就像是上面这个图一样,像一个碗一样。这是我们优化成本函数J的方式,不停的更新w和b的值。让函数移动到最下面的那个红色的点,也就是全局最优解。在这个过程中在纵轴上我们是上下波动的,横轴上我们不停的像最优解移动。 在这中间我们发现纵轴上下波动的太大导致我们在横轴上的移动速度不是很快。 这就需要我们增加迭代次数或者调大学习率来达到最后到达最优解的目的。 但是调大学习率会导致每一次迭代的步长过大,也就是摆动过大,误差较大。 而增加迭代次数则明显的增加了训练时间。 这时候指数加权就出现了。
什么是指数加权?
通过这样一个公式,比如我们现在有100天的温度值,要求这100天的平均温度值。24,25,24,26,34,28,33,33,34,35..........32。

化简开得到如下表达式:
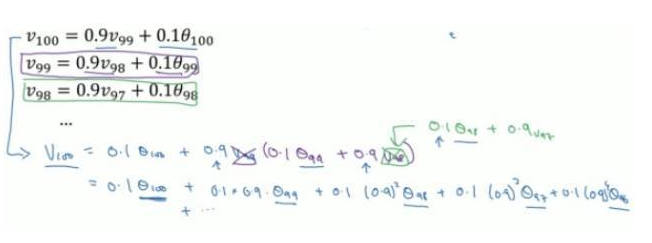
通过上面表达式,我们可以看到,V100等于每一个时刻天数的温度值再乘以一个权值。本质就是以指数式递减加权的移动平均。各数值的加权而随时间而指数式递减,越近期的数据加权越重,但较旧的数据也给予一定的加权。而在我们上面提到的普通平均数求法,它的每一项的权值都是一样的,如果有n项,权值都为1/n。
通过计算,我们发现0.910≈1/e≈0.35,也就是说对于β=0.9而言,10天之后权重就下降到1/3.
对于β=0.98而言,50天之后权重就下降到1/3.
即有: (1-ε)1/ε≈1/e
13
对于V的理解,你可以将其认为该数值表示的是1/(1-β)天的平均值。例如这里取0.9,那么这个V值表示的是十天以来的温度的加权平均值.如果我们设置V是0.98,那么我们就是在计算50天内的指数加权平均,这时我们用,图中的绿线表示指数加权平均值。

我们看到这个高值的β=0.98得到的曲线要平坦一些,是因为你多平均了几天的温度.所以波动更小,更加平坦.缺点是曲线向右移动,这时因为现在平均的温度值更多,所以会出现一定的延迟.对于这个β=0.98值的理解在于有0.98的权重给了原先的值,只有0.02的权重给了当日的值.我们现在将β=0.5作图运行后得到黄线,由于仅平均了两天的温度,平均的数据太少,所以得到的曲线有更多的噪声,更有可能出现异常值,但是这个曲线能更快的适应温度变化,所以指数加权平均数经常被使用.
为什么我们要使用指数加权平均?
实际处理数据时,我们会使用以下公式:
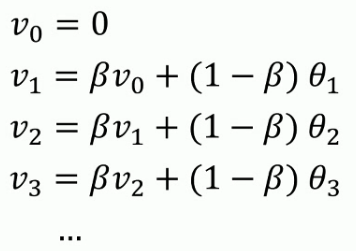
内存代码仅仅占用一行数字而已,不断覆盖掉原有的V值即可,只占单行数字的存储和内存.虽然不是最精确的计算平均值的方法,但是相比于原有的计算平均值需要保存所有数据求和后取平均的方法效率更高和资源占用率大大减小.所以在机器学习中大部分采用指数加权平均的方法计算平均值.
指数加权平均的偏差修正
当我们取β=0.98,实际上我们得到的不是绿色曲线,而是紫色曲线,因为使用指数加权平均的方法在前期会有很大的偏差,为此我们引入了偏差修正的概念。

当 t 大于 0, β 的 t 次方接近于 0, 当 t 很大时, 偏差修正几乎没有作用, 当 t 很大时,紫线基本和绿线重合了,不过在开始阶段,偏差修正可以帮助你更好预测温度,偏差修正可以帮助你从紫线变成绿线。
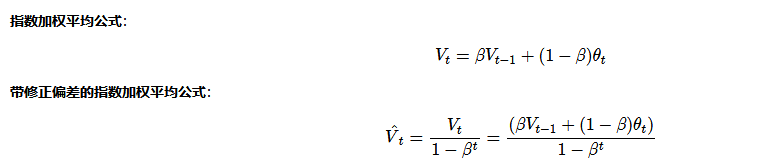
随着t的增大, β 的 t 次方接近于 0,修正后的公式就会还原到原始公式。
在机器学习中,在计算指数加权平均数的大部分时候,大家不太在乎偏差修正,大部分宁愿熬过初始阶段,拿到具有偏差的估测,然后继续计算下去,我们观看上面的图,我们会发现,随着t的增加,紫线基本和绿线重合了。
三 动量 momentum
假设图中是你的成本函数,你需要优化你的成本函数函数形象如图所示,其中红点所示就是你的最低点。使用常规的梯度下降方法会有摆动这种波动减缓了你训练模型的速度,不利于使用较大的学习率,如果学习率使用过大则可能会偏离函数的范围。为了避免摆动过大,你需要选择较小的学习。.

我们在之前的学习中知道梯度下降是一个优化成本函数J的过程,不停的更新w和b的参数来使成本函数J最小。 公式是这样的: 每一次迭代都更新w和b的值, w = w - α*∂J/∂w,b = b - α*∂J/∂b。
我们可以对算法进行一些优化,利用Momentum梯度下降法可以在纵向减小摆动的幅度在横向上加快训练的步长。基本思想:计算梯度的指数加权平均数并利用该梯度更新你的权重。指数加权就是在更新w的时候做一些手脚。看下图。(dw = ∂J/∂w,db=∂J/∂w)

可以看到我们多了一个求Vdw和Vdb, 分别在对w和b的导数上求指数加权平均。然后更新w和b的时候不再是减去α*∂J/∂w了,而是导数的指数加权平均值。其中β就是加权。这也是我们的超参数之一。一般设置为0.9. 它的效果可以在上图中看到。蓝色部分是正常的梯度下降,红色部分是增加了指数加权平均的梯度下降,增加了指数加权后会减少纵轴的上下摆动从而让横轴上更快的移动来达到增速的作用。
α控制学习率,β控制指数加权平均数,β最常用的值是0.9
此处的指数加权平均算法不一定要使用带修正偏差,因为经过10次迭代的平均值已经超过了算法的初始阶段,所以不会受算法初始阶段的影响。
四 RMSprop
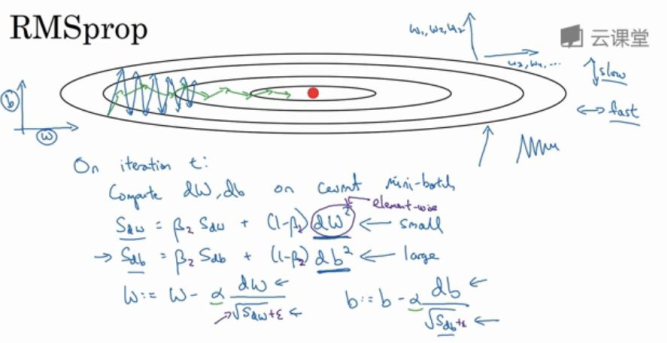
RMSprop (root mean square prop),也可以加速梯度下降。对于梯度下降,横轴方向正在前进,但是纵轴会有大幅度的波动.我们现将横轴代表参数w,纵轴代表参数b.横轴也可以代表w1,w2,w3,....但是为了便于理解,我们将其称之为b和w。
更新公式
Sdw = βSdw + (1-β)(dw)2
Sdb = βSdb + (1-β)(db)2
接着RMSprop会这样更新参数值
w = w - α / sqrt( Sdw)
b = b - α / sqrt( Sdb)
- w的在横轴上变化变化率很小,所以dw的值十分小,所以Sdw也很小,而b在纵轴上波动很大,所以斜率在b方向上特别大.所以这些微分中,db较大,dw较小.这样w除数是一个较小的数,总体来说,w的变化很大.而b的除数是一个较大的数,这样b的更新就会被减缓.纵向的变化相对平缓。
- 实际使用中公式建议为:
w = w - α / sqrt(ε + Sdw)
b = b - α / sqrt(ε + Sdb)
为了确保算法不会除以 0 ,在实际操作中, 你要在除数加上一个很小很小的参数 ε, 不用管 ε 是多少, 可以是10-8 ,这只是保障数值能稳定一些,无论如何你都不会除以一个很小很小的数。
主要目的是为了减缓参数下降时的摆动,并允许你使用一个更大的学习率。
五 Adam(Adapitve Moment Estimation )
在深度学习的历史中出现了很多优化算法,但许多都比较局限,而 RMSprop 以及 Adam优化算法算是稍有的经受住人们考研的两种算法,适用于不同的深度学习结构。
Adam 优化算法基本上就是将 RMSprop 和 Momentum 进行结合,首先需要初始化,迭代 t 次(t 为 mini-batch 的划分 batch 数),用 mini-batch 梯度下降计算 dw,db,接下来计算Momentum 指数加权平均数,β1 为 Momentum 的超参数, β2 为 RMSprop 的超参数,一般使用 Adam 都要计算偏差修正,然后更新参数。所以 Adam 结合了 RMSprop 梯度下降和 Momentum 算法,并且是一种极其常用的学习算法,被证明能有效适用于不同的神经网络,适用于广泛的结构。

本算法有许多超参数: 学习率 α,β1 常用缺省值为 0.9(dw 的加权值), β2 常用缺省值为 0.999((dw)2 的加权值), ε 的选择则没那么重要,通常设置为10-8 ,但你不必去设置它,因为它并不会影响算法表现,在使用 Adam 优化算法的时候,往往可以用缺省值即可,就像β1 ,β2 , ε, 然后尝试不同的学习率, 看看那个效果好。
参考文章
[2] 改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
[3] [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法