日期:2021..05.04
作者:杨传伟
完成任务:爬取腾讯视频电影片库首页所有电影信息(电影名字、播放链接、评分、播放权限)并存到数据库。
爬虫源码

1 import requests
2 import json
3 from bs4 import BeautifulSoup #网页解析获取数据
4 import sys
5 import re
6 import urllib.request,urllib.error #制定url,获取网页数据
7 import sqlite3
8 import xlwt #excel操作
9 import time
10 import pymysql
11 import traceback
12 #连接数据库 获取游标
13 def get_conn():
14 """
15 :return: 连接,游标
16 """
17 # 创建连接
18 conn = pymysql.connect(host="82.157.112.34",
19 user="root",
20 password="root",
21 db="MovieRankings",
22 charset="utf8")
23 # 创建游标
24 cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
25 if ((conn != None) & (cursor != None)):
26 print("数据库连接成功!游标创建成功!")
27 else:
28 print("数据库连接失败!")
29 return conn, cursor
30 #关闭数据库连接和游标
31 def close_conn(conn, cursor):
32 if cursor:
33 cursor.close()
34 if conn:
35 conn.close()
36 return 1
37
38 #爬取腾讯视频电影数据
39 def get_ten():
40 conn,cursor=get_conn()
41 sql="select count(*) from movieten"
42 cursor.execute(sql)
43 conn.commit()
44 all_num=cursor.fetchall()[0][0]
45
46 print("movieten数据库有",all_num,"条数据!")
47 # https://v.qq.com/channel/movie?listpage=1&channel=movie&sort=18&_all=1&offset=0&pagesize=30
48 url="https://v.qq.com/channel/movie?listpage=1&channel=movie&sort=18&_all=1" #链接
49 param={ #参数字典
50 'offset':0,
51 'pagesize':30
52 }
53 headers={ #UA伪装
54 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '+
55 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'
56 }
57 # param['offset']=all_num
58 offset = 0 #拼接url
59 dataRes = []
60 findLink = re.compile(r'href="(.*?)"') # 链接
61 findName = re.compile(r'title="(.*?)"') # 影片名
62 findScore= re.compile(r'<div class="figure_score">(.*?) </div>') #评分
63 #3*170
64 for i in range(0,300):
65 # res = urllib.request.urlopen(url) #urllib不推荐使用
66 res = requests.get(url=url,params=param,headers=headers) #编辑request请求
67 # print(url)
68 res.encoding='utf-8' #设置返回数据的编码格式为utf-8
69 html=BeautifulSoup(res.text,"html.parser") #BeautifulSoup解析
70 part_html = html.find_all(r"a", class_="figure") #找到整个html界面里a标签对应的html代码,返回值是一个list
71 # print(part_html)
72 if (len(part_html) == 0):
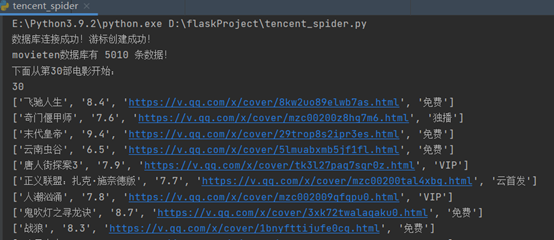
73 print("页面返回空!")
74 return dataRes
75 offset = offset + 30 #修改参数字典+30部电影
76 print("下面从第"+str(offset)+"部电影开始:")
77 param['offset'] = offset
78 print(param['offset'])
79 for i in part_html: #遍历每一个part_html
80 # print(i)
81 words = str(i)
82 name=re.findall(findName, words)# 添加影片名
83 score=re.findall(findScore, words)# 添加评分
84 link=re.findall(findLink, words)# 添加链接
85 findState=BeautifulSoup(words,'lxml') #单独解析播放状态
86 state=findState.select('a > img') #找到img父级标签
87 if(len(state)==1): #免费电影不存在播放状态的标志,所以当img长度是1的时候,需要补上一个空串
88 state.append("")
89 state_text=str(state[1]) #拿到第二个img对应的内容,使用正则匹配到alt属性对应的字符串
90 # print(state_text)
91 temp_state=re.findall('<img alt="(.*?)"', state_text)
92 if(len(temp_state)==0):
93 temp_state.insert(0,"免费") # 添加播放状态---免费
94 # print(temp_state[0])
95 list_=[]
96 if(len(score)==0):
97 score.insert(0,"暂无评分")
98 for i in dataRes:
99 if name[0] in i[0]:
100 name.insert(0,name[0]+"(其他版本)")
101 list_.append(name[0])
102 list_.append(score[0])
103 list_.append(link[0])
104 list_.append(temp_state[0])
105 # list_.append(statu)
106 # print(list_)
107 print(list_)
108 dataRes.append(list_)
109 # print(dataRes) #打印最终结果
110 # list=html.select(".figure_score")
111 # for item in list:
112 # print(item)
113
114 #把同一部电影的信息放到一个 [ ] 里面
115
116 return dataRes
117 #插入到腾讯电影数据库
118 def insert_ten():
119 """
120 插入腾讯电影数据
121 :return:
122 """
123 cursor = None
124 conn = None
125 try:
126 list = get_ten()
127 print(f"{time.asctime()}开始插入腾讯电影数据")
128 conn, cursor = get_conn()
129 sql = "insert into movieten (id,name,score,path,state) values(%s,%s,%s,%s,%s)"
130 for item in list:
131 try:
132 cursor.execute(sql,[0,item[0],item[1],item[2],item[3]])
133 except pymysql.err.IntegrityError:
134 print("重复!跳过!")
135 conn.commit() # 提交事务 update delete insert操作
136 print(f"{time.asctime()}插入腾讯电影数据完毕")
137 except:
138 traceback.print_exc()
139 finally:
140 close_conn(conn, cursor)
141 return ;
142 if __name__ == '__main__':
143 # conn,cursor=get_conn()
144 # list=[]
145 # res_list=get_ten()
146 # print(res_list)
147 insert_ten()
html分析文件
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 </head> 7 <body> 8 <a href="https://v.qq.com/x/cover/aox91j5e2nis6sc.html" class="figure" target="scene=%E9%A2%91%E9%81%93%E9%A1%B5& 9 pagename=%E7%94%B5%E5%BD%B1%E9%A2%91%E9%81%93&columnname=%E5%85%A8%E9%83%A8_%E5%88%97%E8%A1%A8%E9%A1%B5& 10 controlname=listpage&cid=aox91j5e2nis6sc&vid=&pid=&datatype=1&playertype=1&controlidx=0& 11 columnidx=0&plat_bucketid=9231003&cmd=1" tabindex="-1" data-float="aox91j5e2nis6sc" title="老师•好" data-floatid="8"> 12 13 <img class="figure_pic" src="//puui.qpic.cn/vcover_vt_pic/0/aox91j5e2nis6sc1568017385/220" alt="老师•好" onerror="picerr(this,'v')"> 14 15 <div class="figure_caption">01:52:59</div> 16 17 <div class="figure_score">8.1 </div> 18 <img class="mark_v mark_v_VIP" src="//vfiles-raw.gtimg.cn/vupload/20201015/tag_vip_x1.png" 19 srcset="//vfiles-raw.gtimg.cn/vupload/20201015/tag_vip_x2.png 2x" alt="VIP" onerror="picerr(this)"> 20 21 </a> 22 </body> 23 </html>
截图:
5.4 李楠
今日主要学习了使用正则表达式进行数据解析,成功爬取到地区与语言,下面为测试爬取的代码:
1 def get_tencent_data():
2 url_bean = 'https://movie.douban.com/subject/26752088/'
3
4 headers = {
5 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36',
6 }
7
8 text=requests.get(url=url_bean,headers=headers).text
9 ex=' <span class="pl">制片国家/地区:</span> (.*?)<br/>'
10 test=re.findall(ex,text,re.S)
11 ex2='<span class="pl">语言:</span> (.*?)<br/>'
12 test = re.findall(ex2, text, re.S)
13 summary = test[0].replace(" / ", " ")
14 print(summary)
15
16
17 之后对之前的爬取代码进行了优化,并加上了国家与语言:
18 def insert_data(data_beans,headers,cursor,conn):
19 try:
20 #外层循环(五十个拥有20个电影数据的数组)
21 for data_bean in data_beans:
22 #20个电影数据
23 for i in data_bean:
24 # 分配数据
25 score = i["rate"].replace(" ", "")
26 director = i["directors"] # []
27 director_str = ""
28 for j in director:
29 director_str = director_str + " " + j
30 name = i["title"].replace(" ", "")
31 img = i["cover"].replace(" ", "")
32 star = i["casts"] # []
33 star_str = ""
34 for j in star:
35 star_str = star_str + " " + j
36 # 分配数据
37
38 # 获取电影详细数据的网址
39 url_details = i["url"].replace(" ", "")
40 r = requests.get(url_details, headers=headers)
41 soup_bean = BeautifulSoup(r.text, "lxml")
42 # 获取详细数据
43 span = soup_bean.find_all("span", {"property": "v:genre"})
44 type = ""
45 for i in span:
46 type = type + " " + i.text
47 span = soup_bean.find_all("span", {"property": "v:runtime"})
48 timelen = span[0].text.replace(" ", "")
49 span = soup_bean.find_all("span", {"property": "v:initialReleaseDate"})
50 date = span[0].text.replace(" ", "")
51 span = soup_bean.find("a", {"class", "rating_people"})
52 scorenum = span.text.replace(" ", "")
53 span = soup_bean.find("span", {"property": "v:summary"})
54 summary = span.text.replace(" ", "") # 将空格去掉
55 ex = ' <span class="pl">制片国家/地区:</span> (.*?)<br/>'
56 test = re.findall(ex, r.text, re.S)
57 area = test[0].replace(" ", "")
58 ex2 = '<span class="pl">语言:</span> (.*?)<br/>'
59 test = re.findall(ex2, r.text, re.S)
60 language = test[0].replace(" / ", " ")
61 print(url_details)
62 # 获取详细数据
63 sql = "insert into moviebean values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
64 cursor.execute(sql,
65 [name, star_str, director_str, type, area, date, summary, score, language, img, scorenum,
66 timelen])
67 conn.commit() # 提交事务 update delete insert操作 //*[@id="info"]/text()[2]
68 print(f"{time.asctime()}插入数据完毕")
69 except:
70 traceback.print_exc()
71
72 def get_tencent_data():
73 #豆瓣的网址
74 url_bean = 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start='
75
76 headers = {
77 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36',
78 }
79 # num=[0,1020,2020,3020,4020,5020,6020,7020,8020,9020]
80 # partial_big_loop =partial(big_loop,url_bean=url_bean,headers=headers)
81 # #大循环在10个线程中进行
82 # pool=Pool(10)
83 # pool.map(partial_big_loop,num)
84 # pool.close()
85 # pool.join()
86 cursor = None
87 conn = None
88 conn, cursor = get_conn()
89 data_beans=[]
90 num=6420#1440/3020/2760/3100/3180/3440/3300/3660/3860/4000/4020/4260/4380/4440(Data too long for column 'language' at row 1)
91 # /4500/4680/4900/4960/5000/5140/5160/5200/5340/5440/5480/5520/5580//5600/5660/5820/5920/6000/6020/6100/6140/6320
92 b=0;
93 while b<=500:
94 a = 1
95 b=b+1
96 while a <= 1:
97 num_str = '%d' % num
98 num = num + 20
99 a = a + 1;
100 # 获取豆瓣页面电影数据
101 r = requests.get(url_bean + num_str, headers=headers)
102 print(num_str)
103 res_bean = json.loads(r.text);
104 print(url_bean+num_str)
105 data_beans.append(res_bean["data"])
106 print(f"{time.asctime()}开始插入数据")
107 insert_data(data_beans, headers,cursor,conn)
108 data_beans=[]
109 print(f"{time.asctime()}所有数据插入完毕")
110 close_conn(conn, cursor)
111
112
113 初步写完了查询模块,根据类型,时间,地区查询,并可以按照评分与热度正序或倒序排列:
114
115 def find_class_order(str):
116 sql="select title,star,director,score,date_time,area,type_movie,scorenum,img from moviebean where 1=1 "
117 "and (type_movie like "+"'%"+str[0]+"%'"+") and (date_time like "+"'%"+str[1]+"%'"+") and(area like "+"'%"+str[2]+"%'"+") "
118 if(str[3]=="star_1"):
119 sql=sql+" order by score desc "
120 if(str[3]=="star_0"):
121 sql=sql+" order by score "
122 if(str[3]=="hot_1"):
123 sql=sql+" order by scorenum desc "
124 if(str[3]=="hot_0"):
125 sql=sql+" order by scorenum limit "
126 sql=sql+"limit "+str[4]
127 print(sql)
128 res = query(sql)
129 print(res)
130 return res
5.4 章英杰
任务进度: 昨天天设计页面时过于心急,工作出发点出了问题,想着直接在豆瓣网页的基础上做修改,却忽略了整个页面的分块布局问题,导致整个页面模块布局还没有设计好就去设计每一块的具体内容,今天发现页面布局不合理无法继续进行,于是重新写了页面布局。
页面布局主要分为了五部分,标题搜索框部分、电影分类部分、电影排行榜部分、广告部分和底部结尾部分。
产品页面:

任务看板
