
前台提交按纽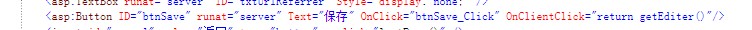
后以赋值

后台取值

后台取值
Base64编解码
C#

/*
编码规则
Base64编码的思想是是采用64个基本的ASCII码字符对数据进行重新编码。
它将需要编码的数据拆分成字节数组。
以3个字节为一组。按顺序排列24 位数据,再把这24位数据分成4组,即每组6位。
再在每组的的最高位前补两个0凑足一个字节。
这样就把一个3字节为一组的数据重新编码成了4个字节。
当所要编码的数据的字节数不是3的整倍数,
也就是说在分组时最后一组不够3个字节。
这时在最后一组填充1到2个0字节。
并在最后编码完成后在结尾添加1到2个 “=”。
*/
//下面是64个基本的编码
var base64EncodeChars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
var base64DecodeChars = new Array(
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
//编码的方法
function base64encode(str) {
var out, i, len;
var c1, c2, c3;
len = str.length;
i = 0;
out = "";
while (i < len) {
c1 = str.charCodeAt(i++) & 0xff;
if (i == len) {
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt((c1 & 0x3) << 4);
out += "==";
break;
}
c2 = str.charCodeAt(i++);
if (i == len) {
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xF0) >> 4));
out += base64EncodeChars.charAt((c2 & 0xF) << 2);
out += "=";
break;
}
c3 = str.charCodeAt(i++);
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xF0) >> 4));
out += base64EncodeChars.charAt(((c2 & 0xF) << 2) | ((c3 & 0xC0) >> 6));
out += base64EncodeChars.charAt(c3 & 0x3F);
}
return out;
}
//解码的方法
function base64decode(str) {
var c1, c2, c3, c4;
var i, len, out;
len = str.length;
i = 0;
out = "";
while (i < len) {
do {
c1 = base64DecodeChars[str.charCodeAt(i++) & 0xff];
} while (i < len && c1 == -1);
if (c1 == -1)
break;
do {
c2 = base64DecodeChars[str.charCodeAt(i++) & 0xff];
} while (i < len && c2 == -1);
if (c2 == -1)
break;
out += String.fromCharCode((c1 << 2) | ((c2 & 0x30) >> 4));
do {
c3 = str.charCodeAt(i++) & 0xff;
if (c3 == 61)
return out;
c3 = base64DecodeChars[c3];
} while (i < len && c3 == -1);
if (c3 == -1)
break;
out += String.fromCharCode(((c2 & 0XF) << 4) | ((c3 & 0x3C) >> 2));
do {
c4 = str.charCodeAt(i++) & 0xff;
if (c4 == 61)
return out;
c4 = base64DecodeChars[c4];
} while (i < len && c4 == -1);
if (c4 == -1)
break;
out += String.fromCharCode(((c3 & 0x03) << 6) | c4);
}
return out;
}
function utf16to8(str) {
var out, i, len, c;
out = "";
len = str.length;
for (i = 0; i < len; i++) {
c = str.charCodeAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
out += str.charAt(i);
} else if (c > 0x07FF) {
out += String.fromCharCode(0xE0 | ((c >> 12) & 0x0F));
out += String.fromCharCode(0x80 | ((c >> 6) & 0x3F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
} else {
out += String.fromCharCode(0xC0 | ((c >> 6) & 0x1F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
}
}
return out;
}
function utf8to16(str) {
var out, i, len, c;
var char2, char3;
out = "";
len = str.length;
i = 0;
while (i < len) {
c = str.charCodeAt(i++);
switch (c >> 4) {
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
// 0xxxxxxx
out += str.charAt(i - 1);
break;
case 12: case 13:
// 110x xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x1F) << 6) | (char2 & 0x3F));
break;
case 14:
// 1110 xxxx 10xx xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
char3 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x0F) << 12) |
((char2 & 0x3F) << 6) |
((char3 & 0x3F) << 0));
break;
}
}
return out;
}
////编码
//value = base64encode(utf16to8(src))
////解码
//value = utf8to16(base64decode(src))