什么是回表查询?
InnoDB使用聚集索引,数据根据主索引存储在叶子节点上,辅助索引的data域存储主键。
myisam使用非聚集索引,即主索引(B+树)的叶子节点存储数据的地址(需要回表),myisam可以没有主键,数据也不是存储在B+主索引的叶子节点上的。
设有表:
t(id PK, name KEY, sex, flag);
画外音:id是聚集索引,name是普通索引。
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
即:
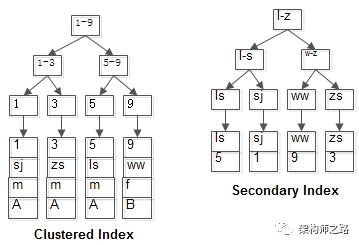
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
比如执行sql select * from t where name='ls';

需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是回表查询
什么是索引覆盖?
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引',
就是select的数据列只用从索引中就能够取得,不必从数据表中读取。
如何实现索引覆盖进行优化查询?
常见的方法是:将被查询的字段,建立到联合索引里去。
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
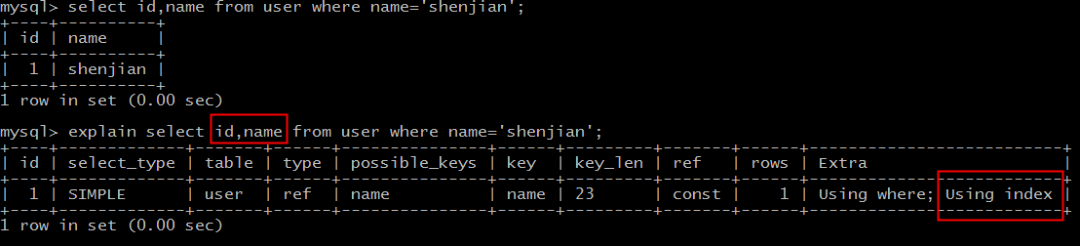
select id,name from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
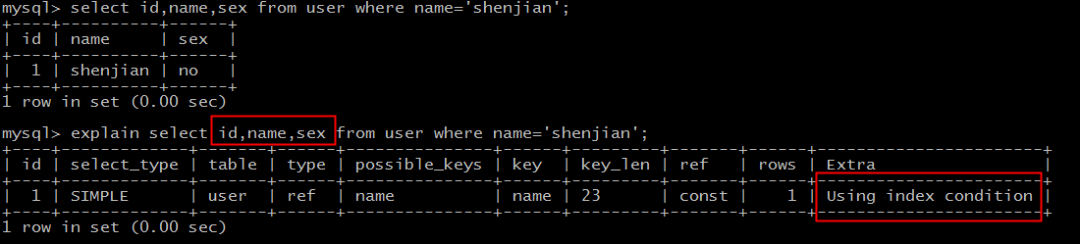
select id,name,sex* from user where name='shenjian';*
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
如果把(name)单列索引升级为联合索引(name, sex)就不同了。
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex)
)engine=innodb;

select id,name ... where name='shenjian';
select id,name,sex* ... where name='shenjian';*
都能够命中索引覆盖,无需回表。