1.观察url:
明显观察出url规律:https://www.qiushibaike.com/text/page/X/
其中X是按页码顺序依次变化的。即1,2,3......。
2.主函数的编写:
def main():
url = "https://www.qiushibaike.com/text/page/1/"
for i in range(1,11):
url = "https://www.qiushibaike.com/text/page/%s/" %i
parse_page(url)
其中 parse_page() 是页面解析函数。以上代码可以实现爬取1-10页的段子。
3.页面解析的分析与编写:
查看目标段子的源代码:
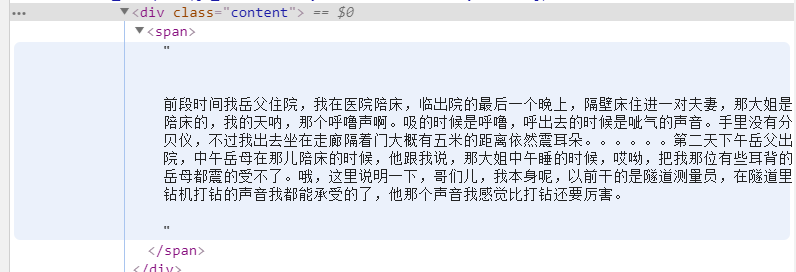
发现每个段子都放在div标签下的span标签。所以可以写出对应的正则表达式:<div class="content">.*?<span>(.*?)</span>
页面解析编写过程:
1)头部信息,获取响应,编码。
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.text
print(text)
尝试输出 text 看看是否有乱码情况。如出现乱码,可以 text = response.text 改成 text = response.content.decode("utf-8")
2)编写正则表达式,存放段子,除去多余部分,输出展示。
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.text
contents = re.findall(r'<div class="content".*?<span>(.*?)</span>',text,re.DOTALL)
duanzi = []
for content in contents:
x = re.sub(r'<(.*?)>',"",content,re.DOTALL)
duanzi.append(x.strip())
print(x.strip())
print("="*60)
使用re模块中的findall函数,找出该页面所有符合的字符,并存放在 duanzi 列表中。其中 re.DOTALL 表示 点号( . )可以匹配所有字符,包括换行符。 因为匹配的字符串中含有一些标签 所以需要去除,即 x = re.sub(r'<(.*?)>',"",content,re.DOTALL) 。最后为了明显显示出爬取的每条信息,使用 = 号分割。
4.全部代码以及结果显示:
import re
import requests
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.text
contents = re.findall(r'<div class="content".*?<span>(.*?)</span>',text,re.DOTALL)
duanzi = []
for content in contents:
x = re.sub(r'<(.*?)>',"",content,re.DOTALL)
duanzi.append(x.strip())
print(x.strip())
print("="*60)
def main():
url = "https://www.qiushibaike.com/text/page/1/"
for i in range(1,11):
url = "https://www.qiushibaike.com/text/page/%s/" %i
parse_page(url)
if __name__ == '__main__':
main()
