之前第一次练习爬虫的时候看网上的代码有些会设置headers,然后后面的东西我又看不懂,今天终于知道了原来这东西是用来模拟浏览器上网用的,因为有些网站会设置反爬虫机制,所以如果要获取内容的话,需要使用浏览器上网才可以。
获取headers的方法很简单,首先打开审查元素界面,有个Network选项,点进去会显示如下:
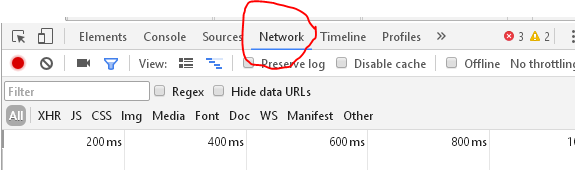
接下来刷新一下:
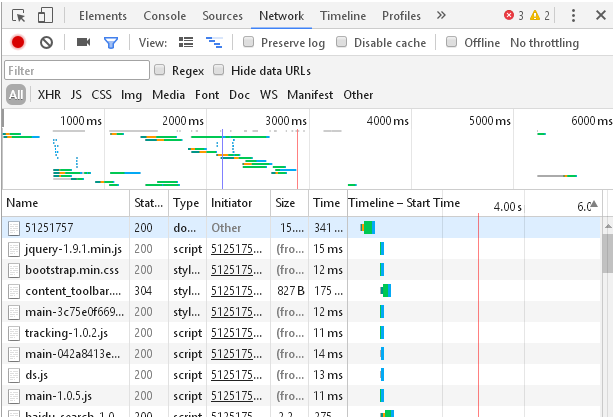
点击第一个5151757后右边会显示Headers选项,我们所需要的就在这个选项卡里面:
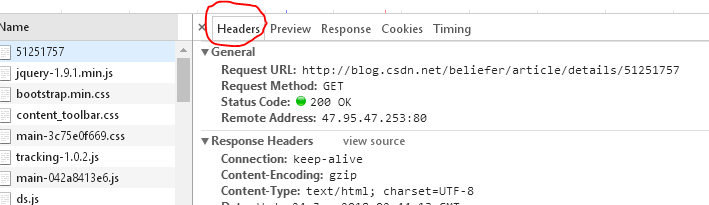
在最后面就有 这样的一个信息,这就是我们所需要的。
这样的一个信息,这就是我们所需要的。
1 from urllib import request 2 3 url = "http://blog.csdn.net/beliefer/article/details/51251757" 4 header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} 5 req = request.Request(url, headers = header) 6 text = request.urlopen(req).read().decode() 7 print(text)
这样就能成功的爬取到网页信息了。
