GraphSAGE
之前所接触的都是直推式学习,也就是仅仅考虑了当前数据,直接计算出节点的embedding,一旦数据变更后,则需要重新训练。
而GraphSAGE则是一种归纳式学习,也就是说它的目标是训练得到权重矩阵的参数。

计算节点 (v) 第 (k) 层的 embedding 流程为:
1、首先聚合 (v) 的邻居节点的第 (k-1) 层的 embedding,得到 ( extbf{h}_{mathcal{N} (v)}^k)。
2、将 (v) 节点第 (k-1) 层的 embedding 和 ( extbf{h}_{mathcal{N} (v)}^k) 做CONCAT 操作。
该模型采用固定采样,规定了每一层采样邻居的个数。在具体实现中,可以采用不同的聚合函数,如 Mean aggregator,LSTM aggregator,Pooling aggregator 等。
该模型的优势是计算的时候不需要全图的信息,只需要采样节点的信息,而不像GCN每次计算都需要全图的矩阵,在大规模图上更有优势。
最终的损失函数定义为:
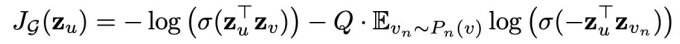
其中 (v_nsim P_n(v)) 表示负采样,节点 (v_n) 是从节点 (u) 的负采样分布 (P_n(v)) 采样的,(Q) 为采样样本数。