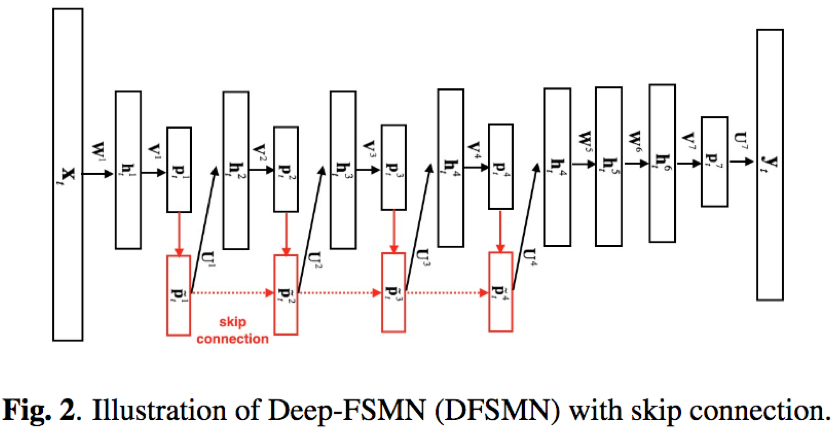
- 隐藏层:全连接结构,激活函数ReLU
- 线性映射层:低秩的线性映射矩阵,相当于无激活的全连接
- 序列记忆模块:包含三部分,一部分来源于上一层序列记忆模块的输出;第二部分来源于线性映射层的输出;第三部分即本层的FSMN结构,对历史和未来的时序信息进行建模,整合成固定维度的编码;三部分相加之后经过线性映射输入到下一层隐藏层
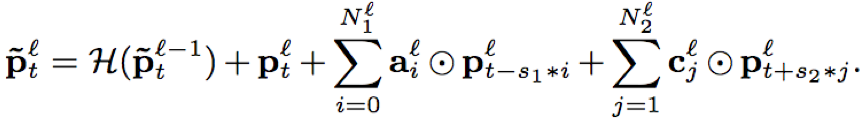
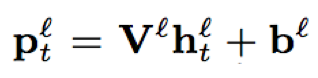

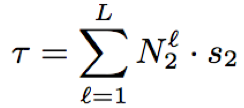
- 数据集:
- 英文:Switchboard (SWB) and Fisher (FSH) 2000h;测试集:Hub5e00 1831utts;采样率8k;输入特征72维fbank(24fbank+1阶差分+2阶差分)
- 中文:20000h,采样率16k,输入特征80维log fbank
- 英文基线系统:
- 输入特征:72fbank
- DNN-HMM
输入特征的上下文窗(7+1+7)
6*hidden layer(2048,ReLU)
- BLSTM-HMM
3*BLSTMP(1024forward,1024backward,512线性映射)
- cFSMN
3*72-4×[2048-512(20,20)]-3×2048-512-9004;4层cFSMN(2048全连接(ReLU)+512线性映射+历史和未来时间片长度20),3层全连接(2048,ReLU),1层线性映射层,输出单元9004
- DFSMN
3*72-Nf×[2048-512(N1;N2;s1;s2)]-Nd×2048-512-9004;Nf和Nd分别表示cFSMN和全连接层数,N1,N2,s1,s2分别代表历史时间片个数、未来时间片个数、历史跨帧步长、未来跨帧步长;其中N1=N2=20,Nd=3固定
- 训练策略:学习率0.00001,momentum0.9;DNN,DFSMN mini-batch 4096;BLSTM mini-batch 16
- 中文基线系统(5000h)
- 输入特征:80维fbank
- 低帧率:30ms/帧
- LFR-CD-LCBLSTM-HMM
3*BLSTM(500forward+500backward)+2全连接(2048,ReLU)+softmax
建模单元:CD-state
Nc= 80、Nr= 40
输入特征的上下文窗(0+1+0)
建模单元:CD-phone
Nc= 27、Nr= 13
输入特征的上下文窗(8+1+8)
- LFR-cFSMN:
3*80-Nf×[2048-512(20,20)]-2×2048-512;Nf=6或8或10
建模单元:CD-state
输入特征的上下文窗(1+1+1)
建模单元:CD-phone
输入特征的上下文窗(5+1+5)
- LFR-DFSMN:
11∗80-Nf×[2048-512(N1;N2;s1;s2)]-Nd×2048-512-9841;N1= 10,N2=5,s1= 2,s2= 2,Nd= 2;Nf=8或10
- 建模单元:上下文状态(14359)/上下文音素(9841)
- 中文基线系统(20000h)
- LFR-DFSMN
11*80−10×[2048−512(5;N2; 2; 1)]-2×2048-512-9841;
- LFR-LCBLSTM
Nc= 27、Nr= 13
3*BLSTM(500forward+500backward)+2全连接(2048,ReLU)+softmax
- DFSMN结构能够较好的利用深度结构,当网络层数增加时,模型的识别效果能够进一步提升;此外,当模型深度达到一定程度时(cFSMN=8),继续增加模型深度,效果提升不明显,但并没有出现下降的情况,也间接证明了skip-connection能够在深度结构中缓解剃度消失和爆炸问题

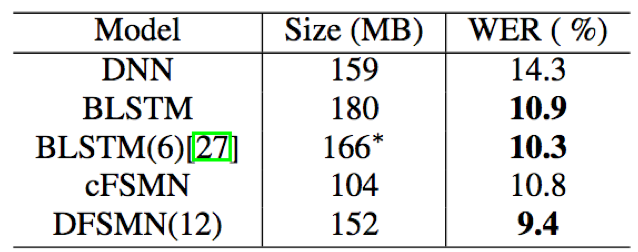
- 在Switchboard英文数据集上,模型参数类似情况下,DFSMN取得了最好的识别结果
- 在5000小时低帧率(30ms/帧)中文识别任务中,当DFSMN采样上下文音素作为建模单元时取得了最好的识别结果,相比于以上下文状态作为建模单元的基线系统LCBLSTM带来了20%的效果提升;另外,从实验结果看,以上下文音素作为建模单元要优于上下文状态
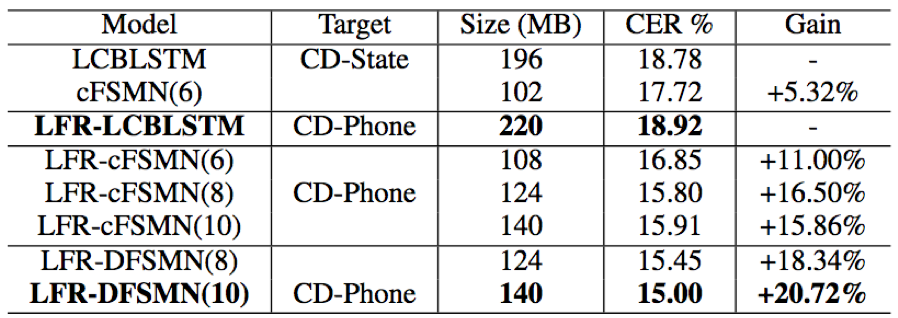
- 在模型训练速度方面,LFR-DFSMN相比于LRF-LCBLSTM可以实现3倍以上的训练加速;同时拥有更好的识别结果

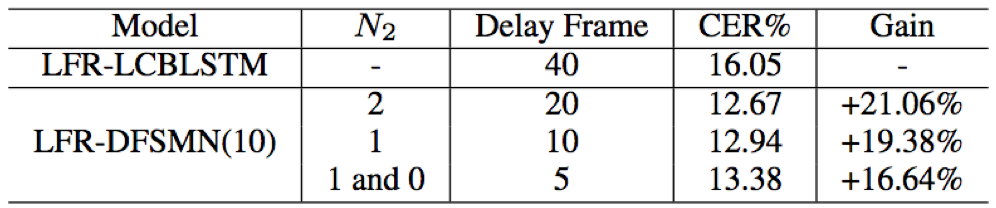
- 对于LFR-DFSMN,减少序列记忆模块中未来时间片的个数和跨帧步长,能够降低输出延迟时间,当输出延迟降低时会造成字错率的轻微上升;当输出延迟为5帧(5*30=150ms)时,相比于LRF-LCBLSTM依然拥有16.64%的绝对识别效果提升;以上表明,LFR-DFSMN系统能够在较低延迟的情况下,取得了较好的识别结果,能够较好的满足流式语音识别的要求
总结: