Kafka提供的所有度量指标都是通过JMX(Java Management Extensions)接口访问
JMX端口查询: zookeeper上获取端口信息 /brokers/ids/<ID>节点包含json格式的broker信息,里面含有JMX对应的主机名和端口
JMX接口提供的是内部度量指标,第三方程序提供的则是外部度量指标
应用程序健康检测:
使用外部进程来报告broker的运行状态(健康检测)
在broker停止发送度量指标时发出告警(stale度量指标)
broker度量指标
非同步分区数量: 作为首领的broker有多少个分区处于非同步状态

该值大于0就要采取措施,首先建议重新选举首领,看看能否解决问题
问题排查步骤:

集群级别的问题:
不均衡的负载 资源过度消耗
问题定位: 用到以下度量指标
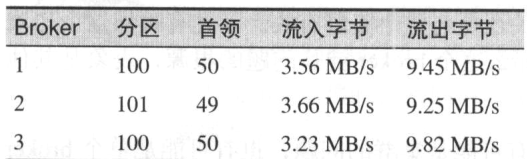
分区数量 首领分区数量 主题流入字节速率 主题流入消息速率
在一个均衡集群里,度量指标的数值在整个集群范围内均等的
以下资源出现过度消耗会导致分区不同步

主机级别问题:
硬件问题
磁盘问题是常见的故障,导致分区不同步,拖慢整个集群broker请求
进程冲突
本地配置的不一致
活跃控制器数量:
表示broker是否就是当前的集群控制器,1代表是,任何时候集群应该只有一个集群控制器

请求处理器空闲率

空闲率低于20%说明存在潜在问题,低于10%说明存在性能问题
主题流入字节

主题流出字节

主题流入消息

分区数量:

首领数量:
该度量指标表示broker拥有的首领分区数量,与其他度量一样,该度量指标也应该在整个集群的broker上保持均等

一个均衡集群如果复制系数是N,则该百分比应该为1/N
离线分区: 显示集群里没有首领的分区数量
分区离线的主要原因: 包含分区副本的broker都关闭了; 消息不匹配,没有同步副本可以拿到首领身份(并且禁用了不完全的首领选举)

请求度量指标:


主题和分区的度量指标:(指定某个主题)
主题实例的度量指标: 取决于集群主题数量

分区实例的度量指标

![]()
JAVA虚拟机监控
垃圾回收:

Java操作系统监控

日志:
Kafka.controller 记录集群控制器的消息
kafka.server.ClientQuotaManager 记录与生产和消费配额活动相关的信息
启用kafka.log.LogCleaner kafka.log.Cleaner kafka.log.LogCleanerManager这些日志,并设置为DEBUG级别,就可以输出日志压缩线程的运行状态
客户端监控
生产者度量指标

record-error-rate 是一个完全有必要对其设置告警的属性,一般情况下是0,大于0,说明生产者正在丢弃无法发送的消息
record-retry-rate 重试次数
request-latency-avg 设置告警,表示发送一个生产者请求到broker所需的平均时间
3种不同视图: outgoing-byte-rate 每秒钟消息的字节数 record-send-rate 每秒消息的数量 request-rate 每秒钟生产者发送给broker的请求数
Per-broker和Per-topic 度量指标
消费者度量指标:

Fetchmanager度量指标
fetch-latency-avg 表示消费者向Broker发送请求所需要的时间


Coordinator度量指标

配额

延迟监控
端到端监控
: