•单词查找树
【问题输入】
输入文件名为word.in,该文件为一个单词列表,每一行仅包含一个单词和一个换行/回车符。每个单词仅由大写的英文字母组成,长度不超过63个字母 。文件总长度不超过32K,至少有一行数据。
【问题输出】
输出文件名为word.out,该文件中仅包含一个整数,该整数为单词列表对应的单词查找树的结点数。
【样例输入】
A
AN
ASP
AS
ASC
ASCII
BAS
BASIC
【样例输出】
13
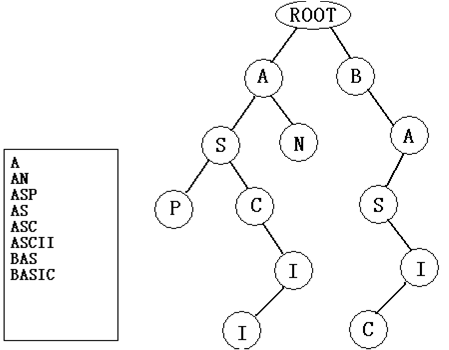
【算法分析】
首先要对建树的过程有一个了解。对于当前被处理的单词和当前树:在根结点的子结点中找单词的第一位字母,若存在则进而在该结点的子结点中寻找第二位……如此下去直到单词结束,即不需要在该树中添加结点;或单词的第n位不能被找到,即将单词的第n位及其后的字母依次加入单词查找树中去。但,本问题只是问你结点总数,而非建树方案,且有32K文件,所以应该考虑能不能不通过建树就直接算出结点数?为了说明问题的本质,我们给出一个定义:一个单词相对于另一个单词的差:设单词1的长度为L,且与单词2从第N位开始不一致,则说单词1相对于单词2的差为L-N+1,这是描述单词相似程度的量。可见,将一个单词加入单词树的时候,须加入的结点数等于该单词树中已有单词的差的最小值。
单词的字典顺序排列后的序列则具有类似的特性,即在一个字典顺序序列中,第m个单词相对于第m-1个单词的差必定是它对于前m-1个单词的差中最小的。于是,得出建树的等效算法:
① 读入文件;
② 对单词列表进行字典顺序排序;
③ 依次计算每个单词对前一单词的差,并把差累加起来。注意:第 一个单词相对于“空”的差为该单词的长度;
④ 累加和再加上1(根结点),输出结果。
就给定的样例,按照这个算法求结点数的过程如下表:
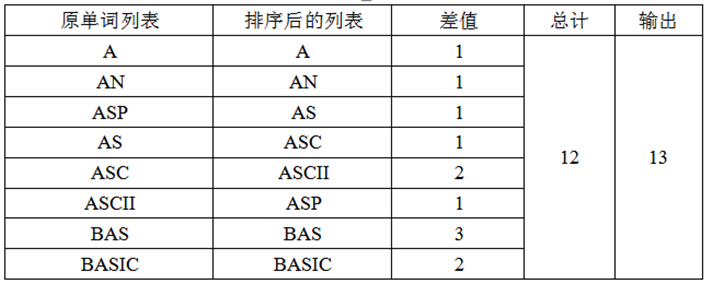
【数据结构】
先确定32K(32*1024=32768字节)的文件最多有多少单词和字母。当然应该尽可能地存放较短的单词。因为单词不重复,所以长度为1的单词(单个字母)最多26个;长度为2的单词最多为26*26=676个;因为每个单词后都要一个换行符(换行符在计算机中占2个字节),所以总共已经占用的空间为:(1+2)*26+(2+2)*676=2782字节;剩余字节(32768-2782=29986字节)分配给长度为3的单词(长度为3的单词最多有 26*26*26=17576个)有29986/(3+2)≈5997。所以单词数量最多为26+676+5997=6699。
定义一个数组:string a[32768];把所有单词连续存放起来,用选择排序或快排对单词进行排序。
代码如下:
1 #include<cstdio> 2 #include<string> 3 #include<iostream> 4 #include<algorithm> 5 6 /* 7 A 8 AN 9 ASP 10 AS 11 ASC 12 ASCII 13 BAS 14 BASIC 15 */ 16 17 using namespace std; 18 19 string dc[8008];//通过计算单词数量最多为6699个 20 21 int main() { 22 int n=0; 23 while(cin>>dc[++n])//从1开始输入,需要换行 24 sort(dc+1,dc+1+n); //快排x 25 int t=dc[1].length();//先累加第1个单词的长度,因为至少有第一个单词,接下来的是从i=2开始,即为第2个词 26 for(int i=2; i<=n; i++) { 27 int j=0; 28 while(dc[i][j]==dc[i-1][j]&&j<dc[i-1].length()) j++;//求两个单词相同部分的长度 29 t+=dc[i].length()-j;//累加两个单词的差length(a[i])-j 30 } 31 printf("%d",t+1);//最后要加上树的根,即为加一 32 return 0; 33 }