首先,一致性哈希是对经典哈希的一个改造
经典的哈希方法使用哈希函数来生成伪随机数,然后除以内存空间的大小,将随机标识符转变成可用空间内的一个位置
location = hash(key)mod size
在经典哈希方法中,我们总是假设:内存位置的数量是已知的,而且这个数永远不变
但是这种哈希处理模型有个问题,size发生变更后,很多key对应的location都要发生变化,这对于海量数据存储来说是灾难
size变化后如何能尽量降低或减少location的变更呢?
那么一致性哈希出场
什么是一致性哈希
表示某种虚拟环结构(名为哈希环,HashRing),无论节点(硬件)或者请求(数据)都通过哈希算法后通过2的32次方进行hash取模0到2的32次方-1来确定哈希环的位置
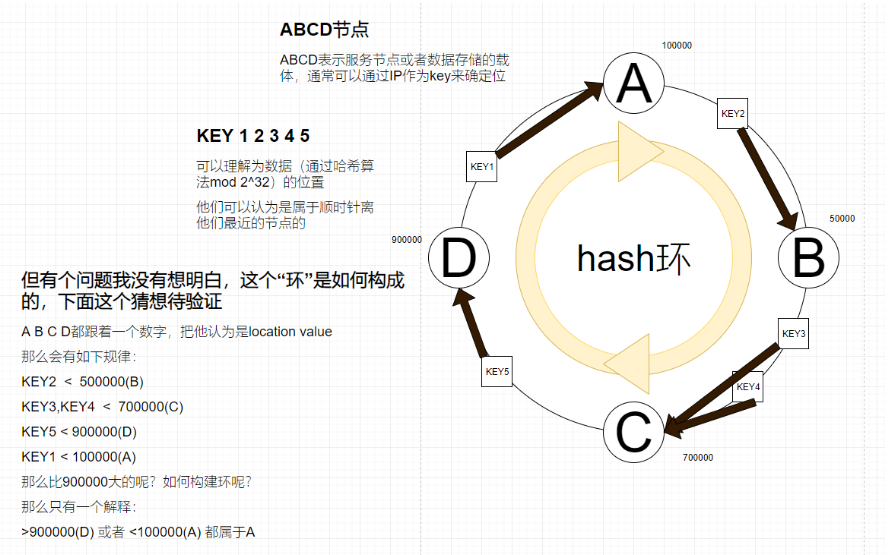
这里我们和经典哈希做一个对比
classicHash = hash(key)mod size
ConsistentHash = hash(key)mod 2^32
变化1、不难看出变量size换成一个常量2^32(这个常量足够大)
变化2、由经典的结果确定位置,变成了顺时针范围取值,经典哈希表大小的变更实际上干扰了所有映射,但一致性哈希并不会,这也就是一致性的原因
这样做最大的好处就是当增、减节点(ABCD),只需要局部变动数据归属
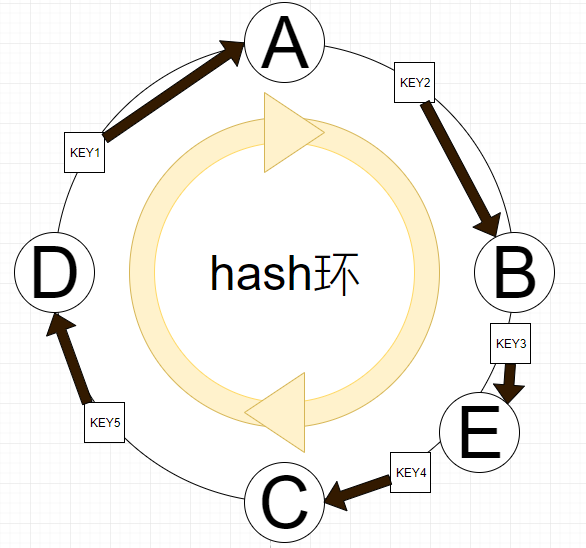
比如BC间添加节点E,如果E的location在KEY3 4之间,那么只需要变动KEY3的归属即可
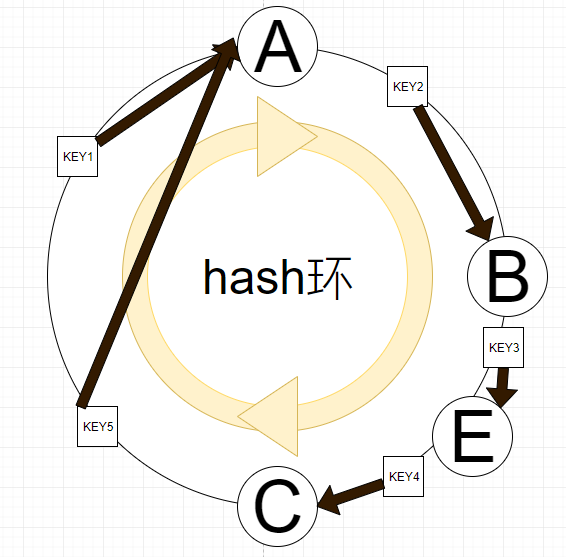
比如删除D节点,也只需要KEY5的归属变更到A上
一致性哈希的特点
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
我的理解,所有的请求都能进入的哈希环中
2、单调性(Monotonicity):单调性是指如果已经有一些数据通过哈希分配到了相应的机器上,又有新的机器加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的机器中去,而不会被映射到旧的机器集合中的其他机器上。这里再解释一下:就是原有的数据要么还是呆在它所在的机器上不动,要么被迁移到新的机器上,而不会迁移到旧的其他机器上。
我的理解,在BC间新增节点E,BC之间的数据要么保留归属C,要么变更为新增的节点E,不能归属给其他的原有节点(比如不能归属给ABD)
一致性哈希倾斜解决:虚拟节点

一致性哈希算法中上图的情况是有可能出现的,即数据分部不均匀,发生了哈希倾斜,如何解决这个问题?
通过增设虚拟节点,即上图中 A B C D4个节点,变更 A1 A2 B1 B2 C1 C2 D1 D2这些虚拟节点,他们并不是真正的物理节点
比如你归属于B2或B1都算归属于B,这样会降低发生哈希倾斜的严重程度,但仍无法完全避免,下图是上图通过增设虚拟节点后哈希倾斜解决的比较好的一种情况

一致性哈希的应用
redis客户端jedis实现的sharding方式,就是通过一致性哈希的方式对数据进行客户端分片
rpc请求的负载均衡算法
所有分布式存储分片
总结:请求->硬件的分配 存储->硬件的分配
主要用他的意义通常要被分配者要支持变动对全局影响小(前提是被分配者变动影响全局,导致工作量很大)
应用一致性哈希
guava封装了一致性哈希的操作
传入多少桶,均匀的把桶分配到哈希环,传入hash值后,算出key属于哪个桶,加减桶后再算key属于哪个桶
/** * 测试一致性哈希 */ @Test public void testConsistentHash(){ List<String> servers = Lists.newArrayList("server1", "server2", "server3", "server4", "server5" ,"server11", "server21", "server31", "server41", "server51" ,"server31", "server32", "server33", "server34", "server35" ,"server51", "server52", "server53", "server54", "server55"); List<String> userIds = Arrays.asList("zxp123549440","zxp","2222","asdhaksdhsakjdsa","!@#$%^"); System.out.println("=============目前有"+servers.size()+"个服务器"); userIds.forEach(userId -> { int bucket = Hashing.consistentHash(Hashing.murmur3_128().hashString(userId, Charset.forName("utf8")), servers.size()); System.out.println("userId:"+userId+" bucket:"+bucket); }); //去掉下标为17的server servers.remove(17); servers.remove(11); servers.remove(10); System.out.println("=============下线3台后还有"+servers.size()+"个服务器"); userIds.forEach(userId -> { int bucket = Hashing.consistentHash(Hashing.murmur3_128().hashString(userId, Charset.forName("utf8")), servers.size()); System.out.println("userId:"+userId+" bucket:"+bucket); }); } /** * 测试经典哈希 */ @Test public void testClassicHash(){ List<String> servers = Lists.newArrayList("server1", "server2", "server3", "server4", "server5" ,"server11", "server21", "server31", "server41", "server51" ,"server31", "server32", "server33", "server34", "server35" ,"server51", "server52", "server53", "server54", "server55"); List<String> userIds = Arrays.asList("zxp123549440","zxp","2222","asdhaksdhsakjdsa","!@#$%^"); System.out.println("=============目前有"+servers.size()+"个服务器"); userIds.forEach(userId -> { long bucket = Math.abs(Hashing.murmur3_128().hashString(userId, Charset.forName("utf8")).padToLong()) % servers.size(); System.out.println("userId:"+userId+" bucket:"+bucket); }); //去掉下标为17的server servers.remove(17); servers.remove(11); servers.remove(10); System.out.println("=============下线3台后还有"+servers.size()+"个服务器"); userIds.forEach(userId -> { long bucket = Math.abs(Hashing.murmur3_128().hashString(userId, Charset.forName("utf8")).padToLong()) % servers.size(); System.out.println("userId:"+userId+" bucket:"+bucket); }); }
ConsistentHash输出结果 5个id,桶位置3个没变 =============目前有20个服务器 userId:zxp123549440 bucket:3 userId:zxp bucket:3 userId:2222 bucket:10 userId:asdhaksdhsakjdsa bucket:18 userId:!@#$%^ bucket:0 =============下线3台后还有17个服务器 userId:zxp123549440 bucket:3 userId:zxp bucket:3 userId:2222 bucket:10 userId:asdhaksdhsakjdsa bucket:0 userId:!@#$%^ bucket:0 ClassicHash输出结果 5个id,桶位置全变 =============目前有20个服务器 userId:zxp123549440 bucket:17 userId:zxp bucket:9 userId:2222 bucket:2 userId:asdhaksdhsakjdsa bucket:14 userId:!@#$%^ bucket:18 =============下线3台后还有17个服务器 userId:zxp123549440 bucket:2 userId:zxp bucket:4 userId:2222 bucket:10 userId:asdhaksdhsakjdsa bucket:9 userId:!@#$%^ bucket:1
如果场景切换到jedis的sharding方式,对比通过一致性哈希实现分片、经典哈希分片:
sharding接到set操作后,拿到key,通过murmur算法算出hash值,并从redis获取目前可用的“集群”节点数,然后通过Hashing.consistentHash就能计算出key应该放入哪个桶,那么sharding用一致性哈希的优势再哪里,假如掉线一个redis实例那么可能大部分key还能再原来的桶中查到,但是如果用的经典的哈希,那么绝大部分的key都变换了redis实例的位置,还是不如一致性哈希结果好