First-rate specialists graduate from Berland State Institute of Peace and Friendship. You are one of the most talented students in this university. The education is not easy because you need to have fundamental knowledge in different areas, which sometimes are not related to each other.
For example, you should know linguistics very well. You learn a structure of Reberland language as foreign language. In this language words are constructed according to the following rules. First you need to choose the "root" of the word — some string which has more than 4 letters. Then several strings with the length 2 or 3 symbols are appended to this word. The only restriction — it is not allowed to append the same string twice in a row. All these strings are considered to be suffixes of the word (this time we use word "suffix" to describe a morpheme but not the few last characters of the string as you may used to).
Here is one exercise that you have found in your task list. You are given the word s. Find all distinct strings with the length 2 or 3, which can be suffixes of this word according to the word constructing rules in Reberland language.
Two strings are considered distinct if they have different length or there is a position in which corresponding characters do not match.
Let's look at the example: the word abacabaca is given. This word can be obtained in the following ways: 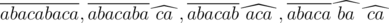 , where the root of the word is overlined, and suffixes are marked by "corners". Thus, the set of possible suffixes for this word is {aca, ba, ca}.
, where the root of the word is overlined, and suffixes are marked by "corners". Thus, the set of possible suffixes for this word is {aca, ba, ca}.
The only line contains a string s (5 ≤ |s| ≤ 104) consisting of lowercase English letters.
On the first line print integer k — a number of distinct possible suffixes. On the next k lines print suffixes.
Print suffixes in lexicographical (alphabetical) order.
abacabaca
3
aca
ba
ca
The first test was analysed in the problem statement.
In the second example the length of the string equals 5. The length of the root equals 5, so no string can be used as a suffix.
题意:
给你一串字符串,将后长与5的(只要在5后面)后半段分为只含三个或者两个的字母的连续后缀
后缀:满足不连续相同可以间隔相同;
将所有满足条件的分法的所有后缀放入集合,按字典序输出
题解:

#include<bits/stdc++.h> using namespace std; const int N = 1e4+20, M = 1e6+10, mod = 1e9+7, inf = 1e9+1000; typedef long long ll; char a[N]; set<string > s; int f[N][5];//i开始到l是否可行 int main() { scanf("%s",a); int n = strlen(a); a[n] = '0'; a[n+1] ='0'; a[n+2] = '0'; if(n<=6) { cout<<0<<endl; return 0; } if(n-2>=5) { string tmp; tmp = tmp + a[n-2]+ a[n-1]; s.insert(tmp); f[n-2][2] = 1; } if(n-3>=5) { string tmp; tmp = tmp + a[n-3]+ a[n-2]+ a[n-1]; s.insert(tmp); f[n-3][3] = 1; } for(int i=n-4;i>=5;i--) { string s1 = "",s2 = ""; s1 = s1 + a[i] + a[i+1]; s2 = s2 + a[i+2] + a[i+3]; if((s1!=s2&&f[i+2][2])||f[i+2][3]) { f[i][2] = 1; s.insert(s1);//cout<<s1<<endl; } if(i+2<n) { s1 = "",s2 = ""; s1 = s1 + a[i] + a[i+1] + a[i+2]; s2 = s2 + a[i+3] + a[i+4] + a[i+5]; if((s1!=s2&&f[i+3][3])||f[i+3][2]) { f[i][3] = 1; s.insert(s1); //cout<<s1<<endl; } } } cout<<s.size()<<endl; for(set<string > ::iterator it=s.begin();it!=s.end();it++) cout<<(*it)<<endl; return 0; }