四大函数式接口
必须掌握的知识点
以前的程序员(知道jdk1.5的特性):
泛型、枚举、反射和注解
新时代的程序员(因为jdk的版本都已经到13了):
所以要在这个三个基础上,必须掌握4个:lambda表达式、链式编程、函数式接口、Stream流式计算
介绍
-
-
接口上面有
@FunctionalInterface(功能接口)的注解标注-
比如Runnable接口
-
@FunctionalInterface public interface Runnable { public abstract void run(); }
-
-
简化编程模型,在新版本的框架底层大量应用!
-
foreach(消费者类的函数式接口)
-
四大函数式接口

Consumer函数式接口

使用代码
package com.zxh.pool; import java.util.function.Consumer; // consumer:消费型接口:只有输入,没有输出 public class FunctionInterfaceDemo { public static void main(String[] args) { // Consumer consumer = new Consumer<String>(){ // @Override // public void accept(String str){ // System.out.println(str); // } // }; // consumer.accept("123"); // 使用lambda表达式 Consumer<String> consumer = (str)->{System.out.println(str);}; consumer.accept("123"); } }
-
提供型接口:没有输入,只有输出
-

使用代码
package com.zxh.pool; import java.util.function.Supplier; /** * 1、Consumer:消费型接口:只有输入,没有输出 * 2、Supplier:提供型接口:只有输出,没有输入 */ public class FunctionInterfaceDemo { public static void main(String[] args) { // Supplier<Integer> supplier = new Supplier<Integer>() { // @Override // public Integer get() { // return 1024; // } // }; // 使用lambda表达式 Supplier<Integer> supplier = ()->{return 1024;}; System.out.println(supplier.get()); } }

Function函数式接口
-
可以有输入,可以有输出
-
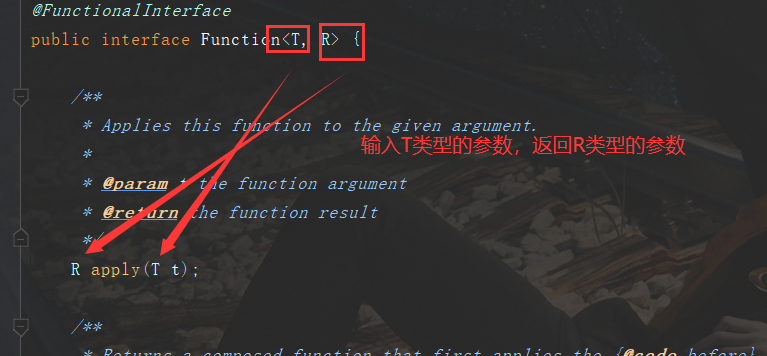
使用代码
package com.zxh.function; import java.util.function.Function; /** * 1、Consumer:消费型接口:只有输入,没有输出 * 2、Supplier:提供型接口:只有输出,没有输入 * 3、Function:有输入,也有输出 */ public class Demo03 { public static void main(String[] args) { // Function<String, String> function = new Function<String, String>() { // @Override // public String apply(String s) { // return s; // } // }; // lambda表达式 Function function = (str)->{return str;}; System.out.println(function.apply("123")); } }
Predicate函数式接口
-
断定型接口
-
可以输入,输出boolean类型参数
-

使用测试
package com.zxh.function; import java.util.function.Predicate; /** * 1、Consumer:消费型接口:只有输入,没有输出 * 2、Supplier:提供型接口:只有输出,没有输入 * 3、Function:有输入,也有输出 * 4、Predicate:断定型接口:有输入,返回布尔型 */ public class Demo04 { public static void main(String[] args) { // Predicate<String> predicate = new Predicate<String>() { // @Override // public boolean test(String str) { // return str.isEmpty(); // } // }; // 使用lambda表达式 Predicate<String> predicate = (str)->{return str.isEmpty();}; System.out.println(predicate.test("123")); System.out.println(predicate.test("")); } }

在大数据中:会有存储 + 计算
而储存的过程就交给流操作!
jdk1.8文档中有Stream接口
例题:包含所有新特性
1、有一个实体类User
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @NoArgsConstructor @AllArgsConstructor public class User { private int id; private String name; private int age; }
2、题目要求
/** * 题目要求:一分钟内完成此题,只能用一行代码实现! * 现在有5个用户!筛选: * 1、ID 必须是偶数 * 2、年龄必须大于23岁 * 3、用户名转为大写字母 * 4、用户名字母倒着排序 * 5、只输出一个用户! */ public class Test { public static void main(String[] args) { User u1 = new User(1,"a",21); User u2 = new User(2,"b",22); User u3 = new User(3,"c",23); User u4 = new User(4,"d",24); User u5 = new User(6,"e",25); // 集合就是存储 List<User> users = Arrays.asList(u1, u2, u3, u4, u5); } }
Stream接口,涉及到的方法
-
filter():参数Predicate,就是段定型的函数式接口
-
该接口的参数可以进行判断,并返回布尔型
-
就可以做到过滤、筛选
-

-
-
map():参数Function,就是只可以指定输入输出类型的函数式接口
-
输入小写字母:转为大写字母并返回。
-

-
-
sorted():参数Comparator,就是可以比较大小的函数式接口
-
该接口的参数可以传入两个相同的类型的参数,进行比较,并且返回int类型的值。
-
如果返回
-

-
Comparator函数式接口测试:
-
public class MyTest { public static void main(String[] args) { Comparator<Integer> comparator = (u1, u2)->{return u1 - u2;}; /* u1 - u2:u1和比u2是升序排列, 当 u1 - u2 < 0:也就是u1 < u2,不动 当 u1 - u2 > 0:也就是u1 > u2,换一下顺序 u2 - u1:u2和比u1是降序排列, 当 u1 - u2 < 0:也就是u1 < u2,换一下顺序 当 u1 - u2 > 0:也就是u1 > u2,不动 */ Arrays.asList(3, 1, 2).stream() .sorted((u1, u2) -> {return u1 - u2;}) .forEach(System.out::println); } }
-
-
limit():从上往下截取截取多少个参数
-
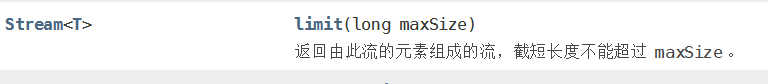
过滤:ID 必须是偶数
// stream流式计算,管理数据 // 应用的到了:lambda表达式、函数式接口、链式编程、Stream流式计算 users.stream() .filter((u)->{return u.getId()%2==0;}) // 过滤 ID 必须是偶数 .forEach(System.out::println);
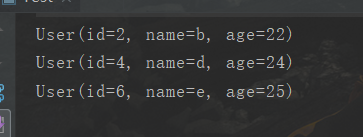
过滤:年龄必须大于23岁
// stream流式计算,管理数据 // 应用的到了:lambda表达式、函数式接口、链式编程、Stream流式计算 users.stream() .filter((u)->{return u.getId()%2==0;}) // 过滤方法: ID 必须是偶数 .filter((u)->{return u.getAge() > 23;}) // 过滤方法: 年龄必须大于23岁 .forEach(System.out::println);
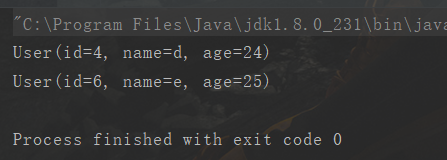
转换:用户名转为大写字母
users.stream() // lambda表达式:如果参数只有一个可以省略括号 .filter((u) -> {return u.getId()%2==0;}) // 过滤方法: ID 必须是偶数 .filter(u ->{return u.getAge() > 23;}) // 过滤方法: 年龄必须大于23岁 .map(u->{u.setName(u.getName().toUpperCase()); return u;}) // 转换方法:用户名转为大写字母 .forEach(System.out::println);
排序: 用户名字母倒着排序
users.stream() // lambda表达式:如果参数只有一个可以省略括号 .filter((u) -> {return u.getId()%2==0;}) // 过滤方法: ID 必须是偶数 .filter(u ->{return u.getAge() > 23;}) // 过滤方法: 年龄必须大于23岁 .map(u->{u.setName(u.getName().toUpperCase()); return u;}) // 转换方法:用户名转为大写字母 .sorted((uu1, uu2)->{return uu2.getName().compareTo(uu1.getName());}) // 排序方法: 用户名字母倒着排序 .forEach(System.out::println);
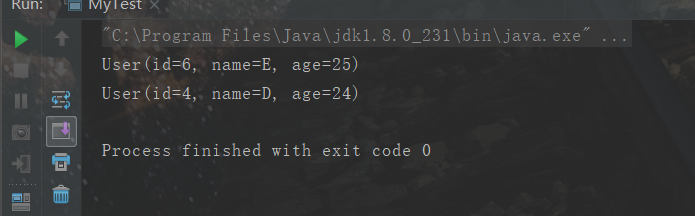
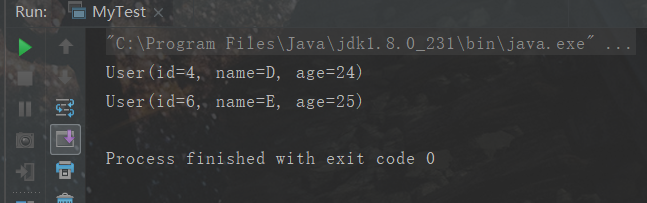
取指定个数:输出一个用户
users.stream() // lambda表达式:如果参数只有一个可以省略括号 .filter((u) -> {return u.getId()%2==0;}) // 过滤方法: ID 必须是偶数 .filter(u ->{return u.getAge() > 23;}) // 过滤方法: 年龄必须大于23岁 .map(u->{u.setName(u.getName().toUpperCase()); return u;}) // 转换方法:用户名转为大写字母 .sorted((uu1, uu2)->{return uu2.getName().compareTo(uu1.getName());}) // 排序方法: 用户名字母倒着排序 .limit(1) // 取指定个数:输出一个用户 .forEach(System.out::println);

完成代码
package com.zxh.Stream; import java.util.Arrays; import java.util.List; /** * 题目要求:一分钟内完成此题,只能用一行代码实现! * 现在有5个用户!筛选: * 1、ID 必须是偶数 * 2、年龄必须大于23岁 * 3、用户名转为大写字母 * 4、用户名字母倒着排序 * 5、只输出一个用户! */ public class Test { public static void main(String[] args) { User u1 = new User(1,"a",21); User u2 = new User(2,"b",22); User u3 = new User(3,"c",23); User u4 = new User(4,"d",24); User u5 = new User(6,"e",25); // 集合就是存储 List<User> users = Arrays.asList(u1, u2, u3, u4, u5); // stream流式计算,管理数据 // 应用的到了:lambda表达式、函数式接口、链式编程、Stream流式计算 users.stream() // lambda表达式:如果参数只有一个可以省略括号 .filter((u) -> {return u.getId()%2==0;}) // 过滤方法: ID 必须是偶数 .filter(u ->{return u.getAge() > 23;}) // 过滤方法: 年龄必须大于23岁 .map(u->{u.setName(u.getName().toUpperCase()); return u;}) // 转换方法:用户名转为大写字母 .sorted((uu1, uu2)->{return uu2.getName().compareTo(uu1.getName());}) // 排序方法: 用户名字母倒着排序 .limit(1) // 取指定个数:输出一个用户 .forEach(System.out::println); } }
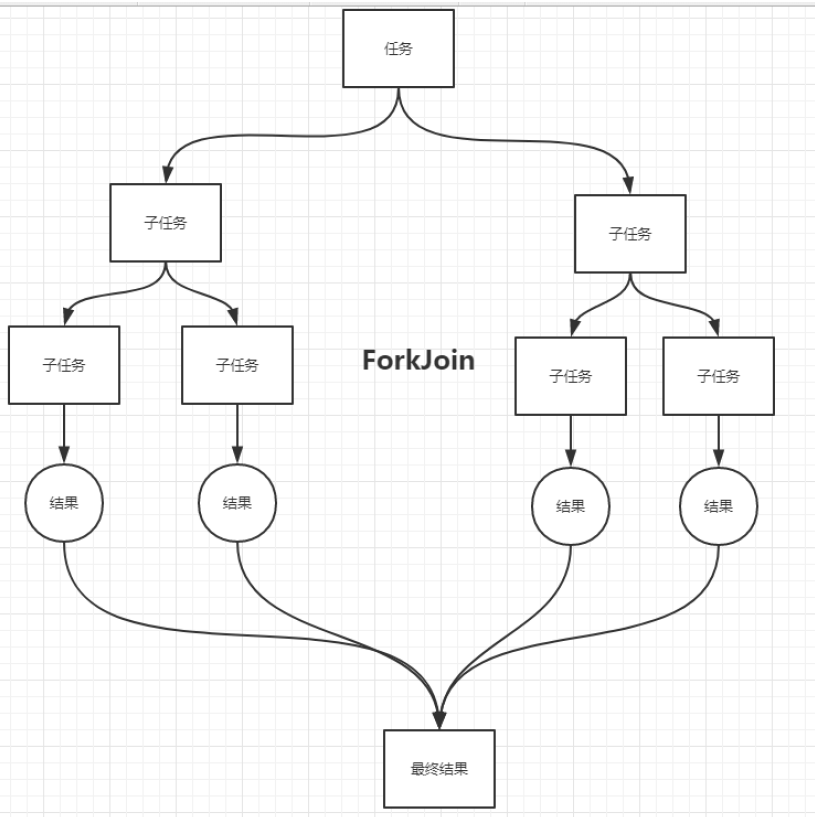
ForkJoin任务拆分
ForkJoin是什么
ForkJoin在JDK1.7的时候就已经出来了,用于并行执行任务!提高效率
具体比如大数据的Map Reduce:将一个大任务拆分成多个小任务执行
概念图
ForkJoin特点
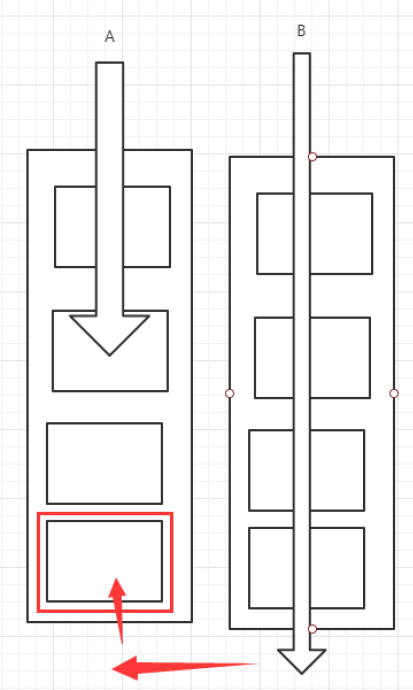
特点:工作窃取
这个里面维护的都是双端队列
概念图
-
AB两个线程,B线程执行完了会把A线程没有执行完的任务偷过来了执行,增加效率
-
但是会产生A和B线程争夺这个任务的情况,但还是利大于弊的
ForkJoin如何使用
肯定需要知道ForkJoin是怎么创建运行的?
1、点开JUC工具包
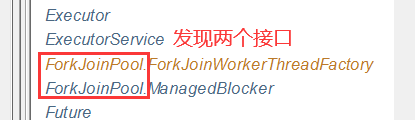
2、可以发现关于ForkJoinPool的两个接口
-
它和线程池一样,线程通过线程池创建,而
ForkJoin通过ForkJoinPool创建并执行的。 -
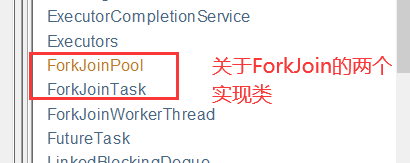
点开可以看到这两个接口,对应只有一个相同的实现类
ForkJoinPool -
3、查看到实现类中有两个关于ForkJoin的类
4、点开ForkJoinPool可以看到有说明
-
首先是实现的两个接口
-

-
随便点开一个可以看到,线程池ThreadPoolExecutor和ForkJoinPool是同一级的。
-
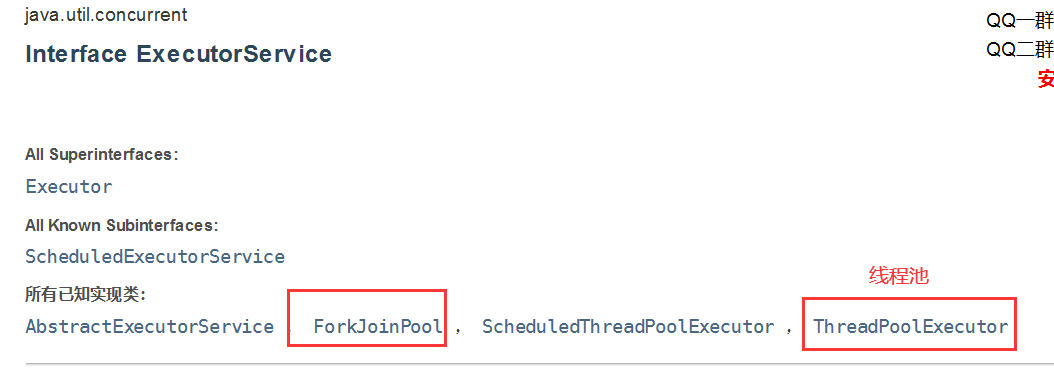
-
-
ForkJoinPool是运行ForkJoinTask的
-

5、怎么运行呢?ForkJoinPool对应提供了3个方法,具体如下:
-
ForkJoinPool有3个主要的执行方法
-
只执行任务,没有返回值
-
-
执行任务,并返回结果
-



6、再查看ForkJoinTask这个类是什么?
-
有两个实现类
-

7、这里我们使用RecursiveTask有返回值的实现类
-
怎么使用呢?文档中有案例,直接继承这个类就可以了
-

-
查看源码,可以发现需要重写一个抽象方法,该方法就是计算的
-
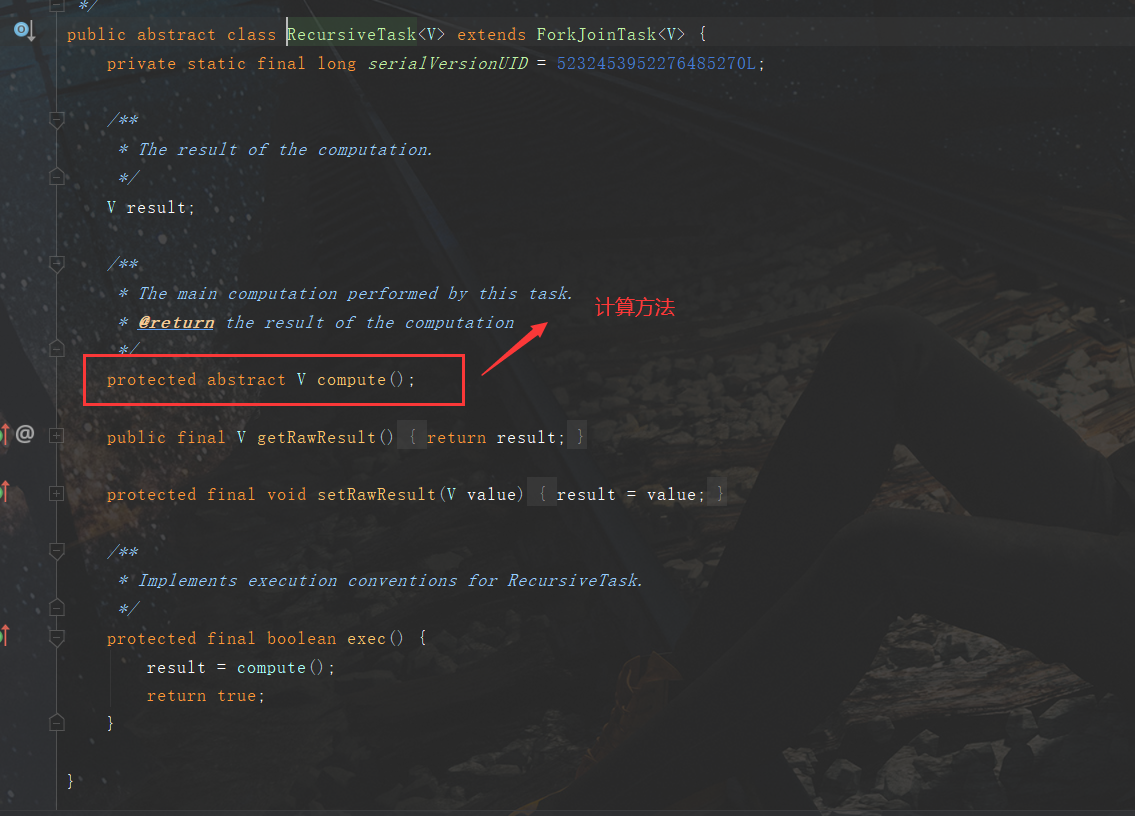
我们了解如何创建并使用ForkJoin,那我们接下来举个例子,从1到10亿进行累加,使用3中方法累加,查看最后的运行效率
举例测试
package com.zxh.forkjoin; public class Test { public static void main(String[] args) { test1(); } // 普通方法 public static void test1(){ Long start = System.currentTimeMillis(); Long sum = 0L; // 使用JDK1.7的分隔符,可以讲10亿写为:10_0000_0000 for (Long i = 1L; i <= 10_0000_0000; i++) { sum += i; } Long end = System.currentTimeMillis(); System.out.println("sum = "+ sum + " 运行时间:" + (end - start)); } }
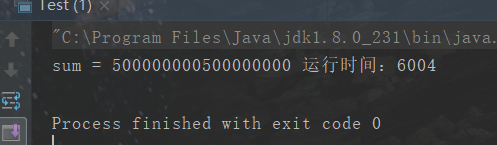
使用ForkJoin优化方法
package com.zxh.forkjoin; import java.util.concurrent.RecursiveTask; /** * 这里模拟求和运算从start开始到end一直累加 * 如何使用ForkJoin? * 1、通过forkJoinPool 执行 * 2、执行计算任务 forkjoinPool.execute(ForkJoinTask task) * 3、计算类要继承 RecursiveTask,因为他有返回值 */ public class ForkJoinDemo extends RecursiveTask<Long> { private Long start; // 初始值 private Long end; // 最终值 // 临界值,用于判断这个任务的大小,如果超出这个数,就对半分割任务执行,提高效率 private Long temp = 10000L; public ForkJoinDemo(Long start, Long end) { this.start = start; this.end = end; } // 计算方法,就相当于递归的操作 @Override protected Long compute() { // 具体任务的执行,并返回执行后的值 if((end - start) < temp){ // 判断要计算的数字个数是否小边界值 Long sum = 0L; // 使用JDK1.7的分隔符,可以讲10亿写为:10_0000_0000 for (Long i = start; i <= end; i++) { sum += i; } return sum; // 返回计算结果 }else{ Long middle = (start + end) / 2; // 取中间数,将任务分割 ForkJoinDemo task1 = new ForkJoinDemo(start, middle); task1.fork(); // 将拆分后的任务,压入线程队列 ForkJoinDemo task2 = new ForkJoinDemo(middle + 1, end); task2.fork(); // 将拆分后的任务,压入线程队列 return task1.join() + task2.join(); // 获取结果,并返回计算结果 } } }
测试类
package com.zxh.forkjoin; import java.util.concurrent.ExecutionException; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.ForkJoinTask; import java.util.stream.LongStream; public class Test { public static void main(String[] args) throws ExecutionException, InterruptedException { test2(); //3993 } // ForkJoin优化方法 public static void test2() throws ExecutionException, InterruptedException { Long start = System.currentTimeMillis(); ForkJoinPool forkJoinPool = new ForkJoinPool(); ForkJoinDemo task = new ForkJoinDemo(0L, 10_0000_0000L); // 计算任务 ForkJoinTask<Long> submit = forkJoinPool.submit(task); // 提交任务 Long sum = submit.get(); Long end = System.currentTimeMillis(); System.out.println("sum = "+ sum + " 运行时间:" + (end - start)); } }

使用Stream并行流

package com.zxh.forkjoin; import java.util.concurrent.ExecutionException; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.ForkJoinTask; import java.util.stream.LongStream; public class Test { public static void main(String[] args) throws ExecutionException, InterruptedException { test3(); //212 } // Stream流并行执行方法 public static void test3(){ Long start = System.currentTimeMillis(); // LongStream,并行流 // rangeClosed():(]最开右闭,设置计算数字从1到10_0000_0000 // parallel():开启并行计算 // reduce():求和方式,并返回结果 long sum = LongStream.rangeClosed(0L, 10_0000_0000L).parallel().reduce(0, Long::sum); Long end = System.currentTimeMillis(); System.out.println("sum = "+ sum + " 运行时间:" + (end - start)); } }

小结
有3 6 9的说法,说是工资3000 6000 9000,上面的方法对应着工资,如果想拿到高工资,使用Stream流是最好的了,至于底层还需要研究,掌握这么一点是不行的。