首先点题,在经历了三周的代码训(cui)练(can)之后,本弱很感谢能有这样一次写博客的机会来总结收获(短暂摸鱼)。本篇博客将分为以下几个模块来讲,因为水平有限所以没有什么特别高深的内容,阅读体验极佳。
一、从初识面向对象到抽象思维的建立
OO届有一句名言,“Everything is object”,万物皆对象。第一次看到这句话的时候,笔者内心的OS:这课还教人脱单?
过去一年半的时间里,我们接受的训练,例如C语言,数据结构,其训练主题都是以面向过程为核心,在看到题目的第一反应之后就是开全局数组,写函数,调用函数,整个程序的内容基本就是一个个函数累加起来的结果,所以在寒假里用Java写a+b一二三四的时候,果不其然地写了一堆面向过程的程序,读入+处理+输出,多么漂亮的面向过程的程序呀!甚至在做第一次求导作业的时候,笔者还觉得这东西根本就不需要面向对象:用一个C语言的struct把每个项都分割开来,存储到数组中,写个函数遍历数组对每个元素都求导,再输出,好像没有什么问题,但细细想来,我怎么已经走上了面向对象的路?
刚开始写Java的时候,相信大部分同学都会觉得,这东西和C语言的结构体好像呀,就像是自己声明了一种变量类型,里面包含了要描述事物的诸多属性,笔者认为其实C语言的结构体也是面向对象一种抽象思维的体现,但不同点是,我们的原生C语言没办法给这些结构体加方法,比如说,我需要对某一个幂函数项求导,C语言说,你需要为这个项写一个求导函数,然而Java说,你需要为这个项内置一个方法;这二者在需要管理的数据类型不多的时候(比如第一次的简单幂函数求导)是没有很大区别的,我大可以写一个面向过程的程序来搞定这个问题,但是换了第二次第三次,事情好像就复杂了起来。如果还用面向过程的写法,我有两个选择,一是建立一堆不同类型的结构体,然后写一堆不同的求导函数,二是在一个大函数里面采用if-else大法,但这样导致的直接后果就是,我的程序不仅很难看,而且很容易出问题,如果将来加了更多类型的项,程序的可扩展性缺陷就会暴露的十分明显。在这点上面向对象就会很有优势,我从设计的时候就把类抽象出来,类作为属性和方法的集合,其中的元素具有很大的共性,例如幂函数因子、三角函数因子,他们都有指数,都有求导的功能,把这些元素统一剥离起来建立类,对我们程序的扩展是很有利的。
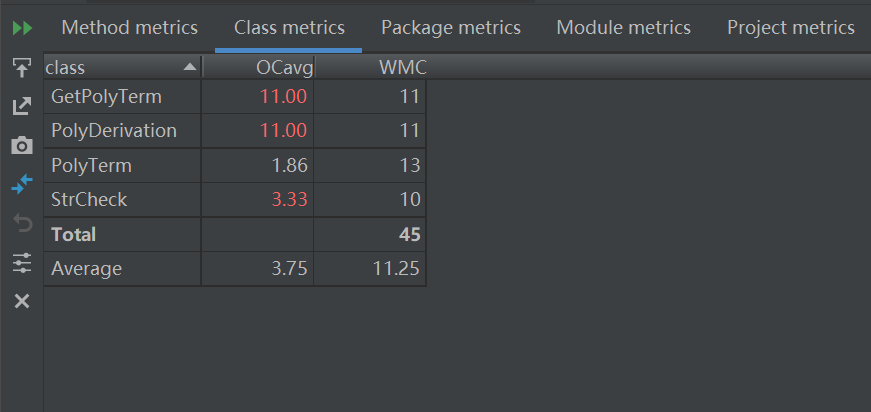
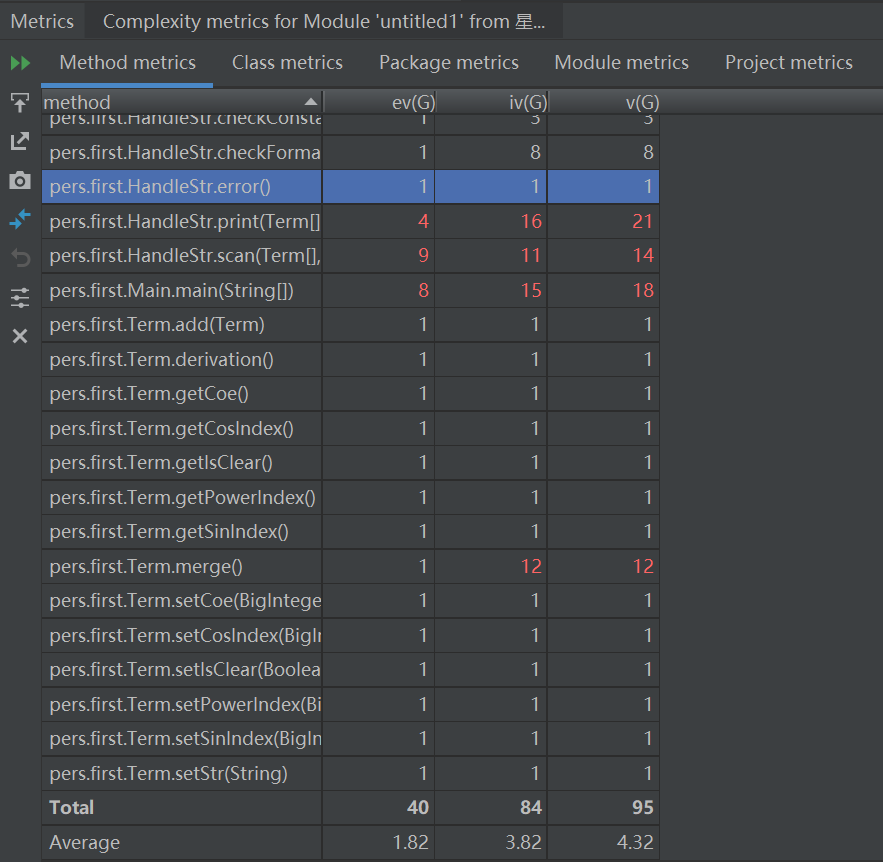
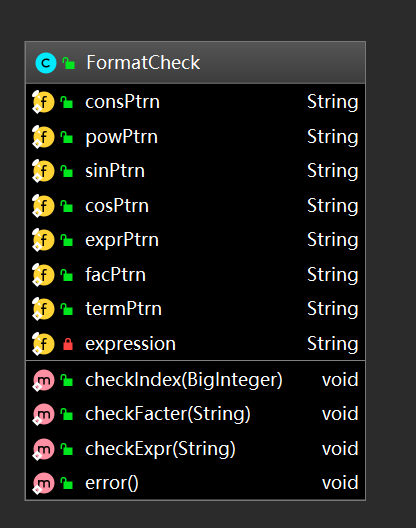
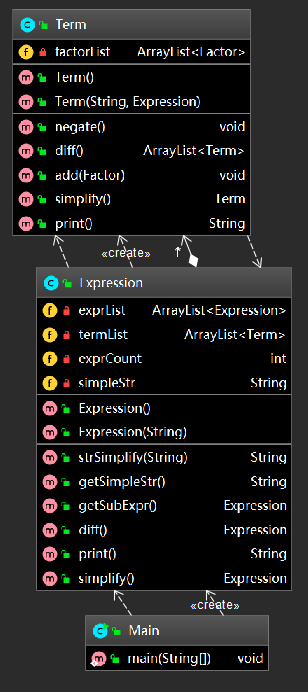
老师在第一节课就提过面向对象的三个核心,”封装、继承、多态“,三次作业下来,我已然成为了面向对象的忠实粉丝。下面放了几张图,依次是我第一次、第二次和第三次程序内部的类构造。 homeworkI和homeworkII我采用的类基本一致,但是从OO的角度来看,提取出的类并不是十分合适,诸如”因子“这样的抽象层次并没有得到体现,所以在homeworkIII的时候我选择(被迫)重构代码。前两次类的复杂度有点不忍直视,第3次作业明显进步了很多。
(1)第一次作业
a.类图

b.方法复杂度分析

c.类复杂度分析
(2)第二次作业
a.类图

b.方法复杂度分析
c.类复杂度分析

(3)第三次作业
a.类图

b.方法复杂度分析

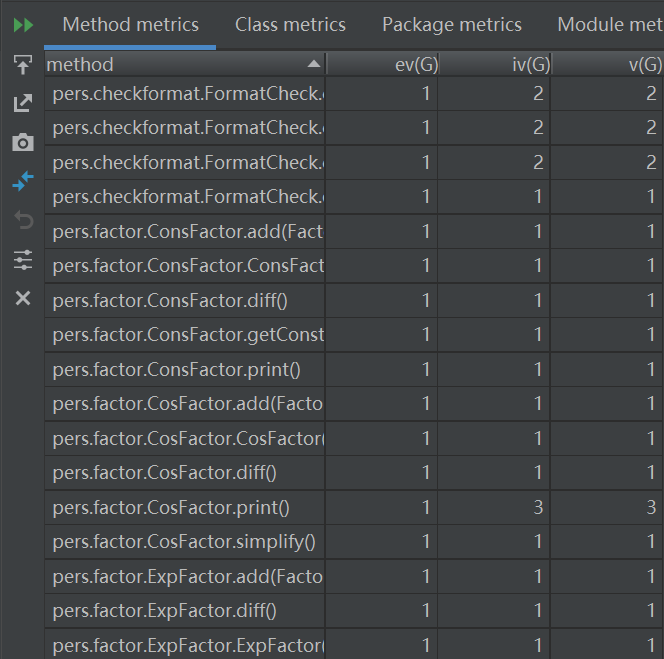
c.类复杂度分析

从中可以看到,虽然第一次我已经有意识地去提取类,但似乎我更像是把类当成函数在用(从名字来看已经很明显了),这其实和面向对象的要求是不相符的;第二次作业已经有了明显的进步,我从作业要求中提取出了输入类、字符串处理类、项类和因子类,虽然在抽象程度上还不算最佳,但已经有了功能分区和封装的概念;第三次作业终于应用到了传说中的继承,单独写一个抽象因子类(Factor),内含求导方法和打印方法,然后在子类中实现对这些方法的个性化重写;这样做最方便的地方就是,我可以用Factor去引用各个类型的因子 (诸如Pow、Sin、Cos甚至Expression型的因子),这样我只需要一堆Factor类型的容器就可以管理所有因子即可,而不需要再去单独判断这个因子是什么类型,应该调用哪种因子的求导或者打印方法。
这里借用助教大大在讨论区的帖子总结一下继承和接口的区别。Java的特性是单继承多接口,将继承和接口搭配应用可以让我们的代码变得更加优雅。我个人的理解是,继承不仅保留了共同的方法,更保留了一些数据属性,接口相对来说则更加注重方法(行为)的共性。我从Head First Java中看到过一个很形象的例子,例如,我建立了一个Animal类型的类,其中有年龄、体重等数据属性,还有吃饭、睡觉等行为方法,从Animal类中衍生出来的有dog、cat、duck类,这些类从Animal中继承了上述的数据属性和方法,但是此时,如果用户需要为cat和dog加一些“宠物”属性,例如和主人一起玩,窝在主人的腿上睡觉这种行为要怎么办呢?如果加在Animal里面,那怕是一场灾难了(反正我脑补一下鸭子和主人一起玩,觉得画面很美),此时就要用到接口了,我们可以通过创建一个Pet类型的接口,在里面放一堆宠物才会有的行为,再把cat和dog类接上这个接口就大功告成了。
二、分析bug和找bug的方法
这三次作业很幸运的是,我没有被别人hack过,强测的数据点也都全部通过了(虽然性能真的很弱),所以我也不知道自己的程序还有什么潜在的问题。但我在第一次作业的时候还是非常naive的,讨论区里的提到的坑我踩了一个遍,主要三个问题,大正则爆栈、空文件输入、非法字符判断,在距离ddl的最后两小时里,我commit了三次,每次改完之后交上去长舒一口气然后继续踩雷。在互测中遇到的别人的bug其实也都非常玄学,除了上述的这些问题,还有复杂正则笔误(输入2*输出0)、题意理解错误(输入x^1001-x^1001输出WRONG FORMAT)等bug,大多都是一些细节没有处理好或者没有测试到产生的问题,另外还有比较大佬的同学可能对性能分的要求比较高,在优化的时候出现了一些意想不到的错误。
那么如何有效避免这些bug呢?我觉得最好的回答就是设计+模块测试,八字真言:测试、测试、疯狂测试,用随机数据大批量轰炸检查程序基本功能,用特殊数据(超长输入、非法数据)检验程序鲁棒性,读代码检查逻辑定点爆破,代码分段分区检测。测试的时候心态真的很重要,要坚信在交作业之前找出来bug是一件很幸运的事,最起码,失分的概率又小了一点不是......?当然,高手们写代码当然不是只靠测试打补丁来提升程序鲁棒性的,更重要的是设计。作为一名比较合格的程序员,不能拿到题目之后就直接开始莽,起码要把题目理顺,设计层次,把自己的思路弄明白之后才开始敲键盘,否则一边写一边打补丁,最后连自己都看不懂写的是什么了(不要问我为什么知道,毕竟我是重构了n次的人)。当然,理解好需求(题意)是第一步,第一次作业就因为对指导书的理解出现了问题写了一个上午的无效代码。
三、思考重构的方法
之前在讨论区看到一个非常好的帖子,里面有提到,面向对象要求我们把容易变化的内容和不易变化的内容区分开来,然后把容易变化的东西装在黑盒子里封装,这样有什么新的需求就直接往里添加,再添加必要的接口即可,不需一次次地重构代码。再回去思考这几次作业的过程,这位同学真的说的太对了(手动捂脸)。如果重新设计代码架构,我会直接采用第三次的做法,采用树的结构去一层层地管理表达式、项和因子,通过上一级去层层调用下一级的方法完成求导的功能,而不是在表达式层面直接去操作因子。
这里贴一篇关于工厂模式的帖子:http://www.cnblogs.com/homg/p/3548110.html