第一次编程作业
代码在这里:我的github:https://github.com/cath-cell/031804139_zxh/tree/master/031804139
一、算法(其实算不上算法,勉强是个思路叭)
这一题最开始的思路是用 余弦相似度的算法。
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
它的原理就是先分词,再汇总所有出现过的词,然后计算两个文章的词频,完成文章向向量的转换,最后计算余弦相似度
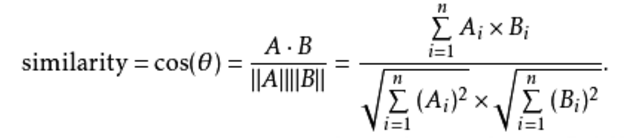
然后我编写了一个小小的测试程序,可以看出结果是十分不准确的

于是我接入了哈工大的停词表
代码如下:
`def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
stopwords = stopwordslist("hit_stopwords.txt")`
再测试一次,结果如下:
悲伤的发现结果并无大变化
所以应该要从算法角度重新入手,再次考虑合适的算法
所以在算法上进行优化,增加了利文斯顿相似度的算法以及jaccard的算法。
简单介绍一下利文斯顿相似度以及jaccard的算法:
· 利文斯度相似度是基于编辑距离的,而编辑距离是指文本A变为文本B的处理次数。这些处理包括:1、删除一个字符 2、增加一个字符 3、修改一个字符
举个栗子:
A:我喜欢你
B:我不喜爱它
从定义容易看出编辑距离为3,而利文斯度相似度就是将上述编辑距离数值转换为normalize的分数(一个范围0到1之间的浮点数)
· Jaccard的系数也很容易理解
还是以A和B句为例,求出单词的交集以及单词并集,交集与并集的比例就是Jaccard相似系数
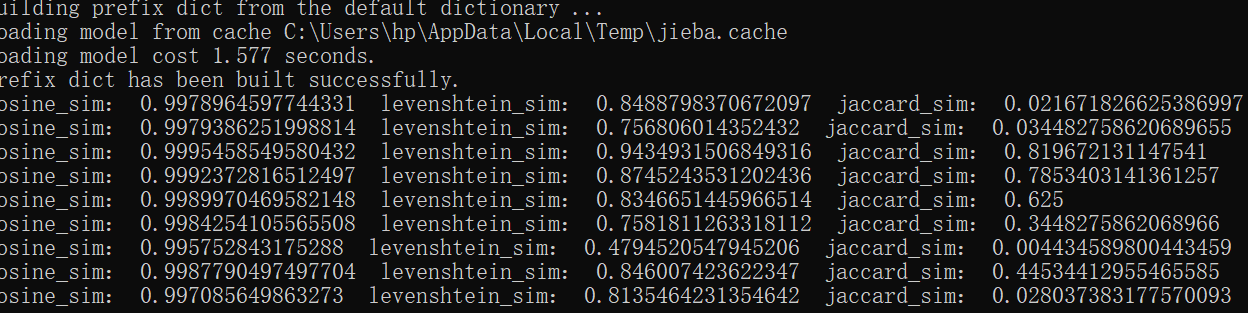
于是我基于这三种小小的算法,各自在测试集上跑了一遍,结果如下:
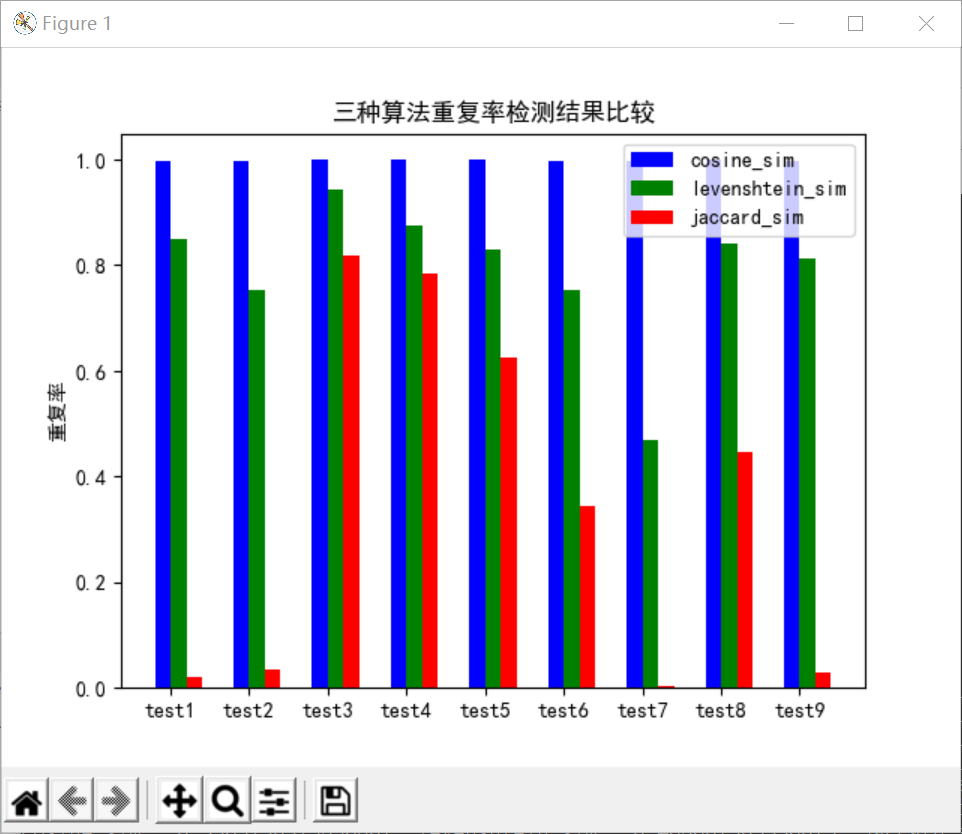
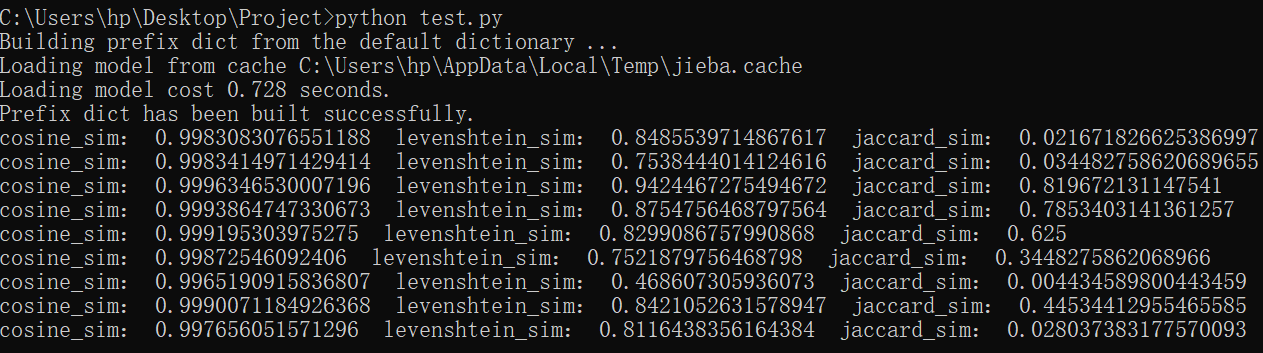
可以看出,cosine的结果有很大问题,Jaccard的结果在中间的数据集上表现的还不错,综合起来,利文斯度的算法表现较优,所以我最后选择了利文斯度的算法。
二、代码的编写思路
准备在这里展开讲一下整个代码是怎么写的。其实遇到了很大困难,对于python不甚熟悉,去各种地方查找才勉强搞懂一些东西要怎么写。
流程图如下:
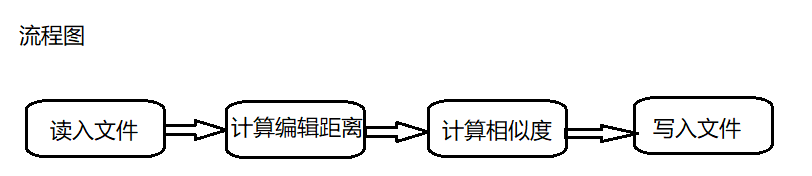
所以第一步就是读入文件
file_origin = open(sys.argv[1], 'r', encoding='utf-8').read() file_copy = open(sys.argv[2], 'r', encoding='utf-8').read()
接着计算编辑距离
`def compute_levenshtein_distance(f1, f2) -> int:
leven_cost = 0
s = difflib.SequenceMatcher(None, f1, f2)
for tag, i1, i2, j1, j2 in s.get_opcodes():
if tag == 'replace':
leven_cost += max(i2 - i1, j2 - j1)
def compute_levenshtein_similarity(f1, f2) -> float:
"""Compute the hamming similarity."""
leven_cost = compute_levenshtein_distance(f1, f2)
return 1 - (leven_cost / len(f2)) elif tag == 'insert':
leven_cost += (j2 - j1)
elif tag == 'delete':
leven_cost += (i2 - i1)
return leven_cost
`
然后将编辑距离转化成相似度
def compute_levenshtein_similarity(f1, f2) -> float: """Compute the hamming similarity.""" leven_cost = compute_levenshtein_distance(f1, f2) return 1 - (leven_cost / len(f2))
最后是一个将结果写进指定地址的文件的方法
`
def write_result(output, file, test):
with open(output, 'a') as file_handle:
file_handle.truncate(0)
file_handle.write('%.4f' %compute_levenshtein_similarity(file,test))
file_handle.close()
`
三、异常处理
我这里就只编写了一个异常类,即判断有没有空文件,如果有空文件,那么就报错
class BlankError(Exception): def __init__(self): print("这个文件没有内容哦")
四、测试函数
测试函数是我自己编写的一个非常憨批的test.py文件
它批量测试了三种不同算法所算出的重复率,并通过一个可视化的方法做出柱状图
也就是我当初选择其中最优算法的依据
具体的代码可以在github上查看
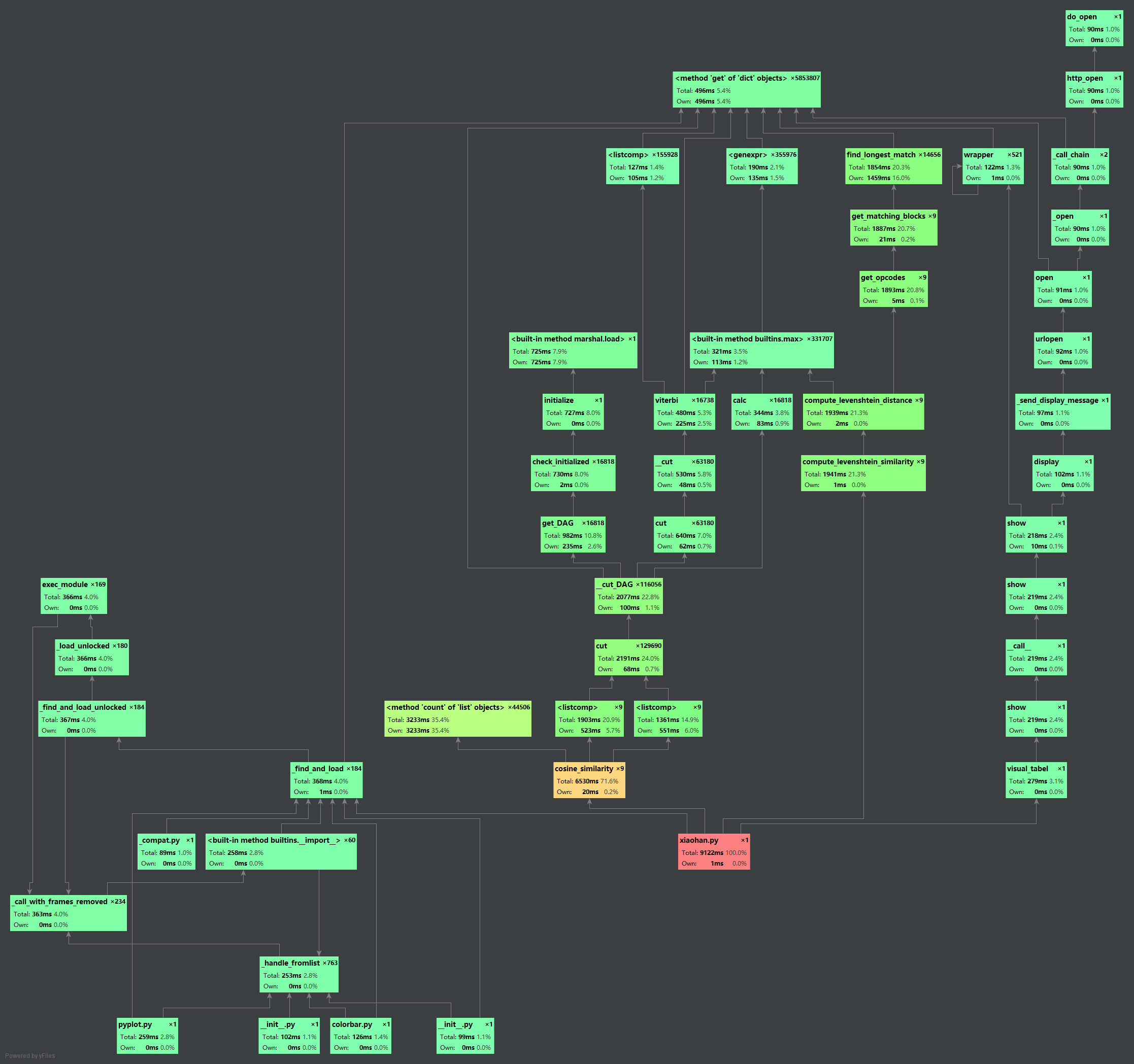
四、性能测试及优化
test程序的性能的测试如下:
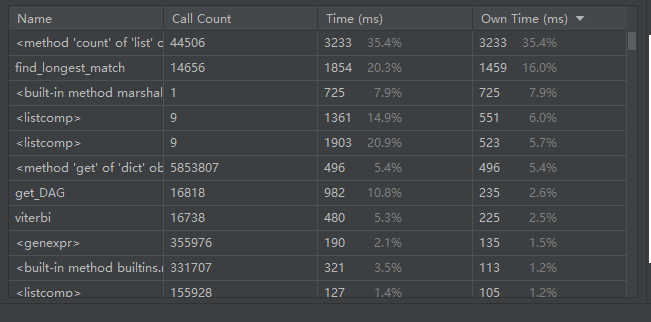
优化这里我就是增加了一个删除标点符号的方法
def delete_char(f): chars = ['
', ' ', ',', '。', ';', ':', "?", '、', '!', '《', '》', '‘', '’', '“', '”', ' ', '1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '.', '*', '-', '—', ',', '——', '……', '(', ')', '…', '%', '#', '@', '$', '¥', '~', '', '~', '·']
for item in chars:
f = f.replace(item, '')
return f`
这是增加前的结果
这是增加后的结果
可以看出前后稍微有一点点点点变化,准确率似乎提高了一小点点点
五、心得体会
做了这些东西之后唯一的想法就是,“啊,真的好难啊”,Python不太会用,写了半天代码,最后好像还没有很合要求,只能说课前准备不足,课中的学习效率又跟不上,希望下次作业能做的尽量合乎要求。心得大概就是软工实践是个综合能力的体现,查找资料的能力,学习新东西的能力等等都有考察到,希望以后的自己一直都能以平和的心态对待,好好学习,夯实自己的基础,提高自己的技术能力。冲冲冲!
附录
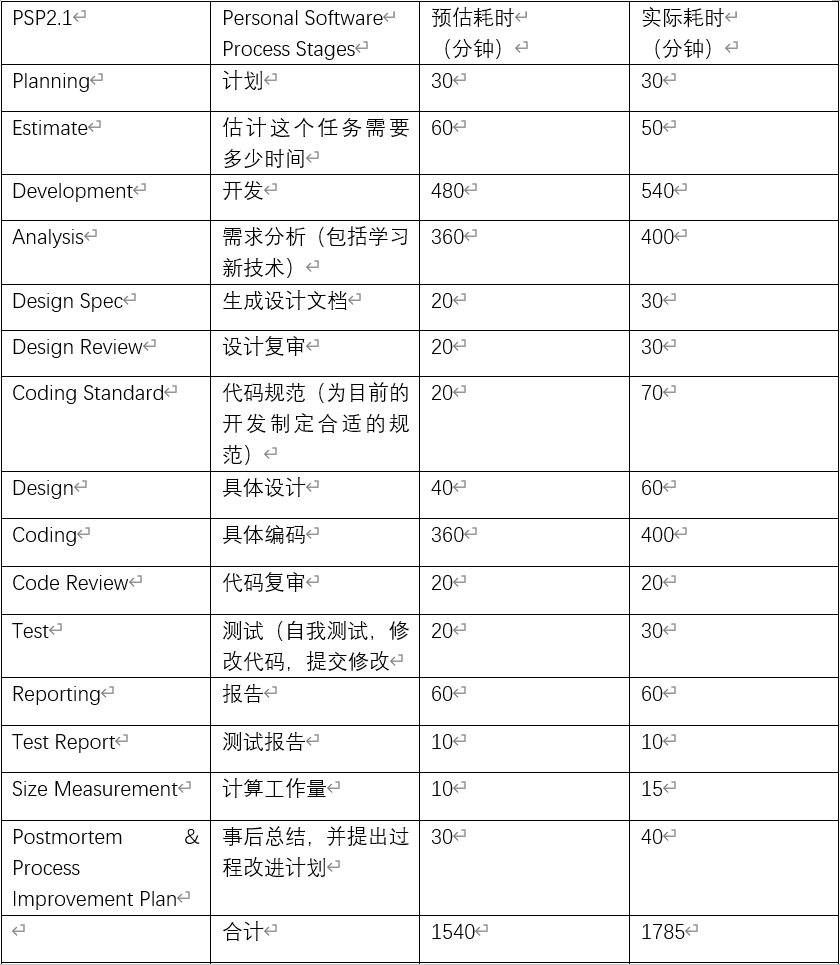
PSP表格