MySQL多索引查询选择
MySQL选择索引-引入
我们知道我们一个表里面可以有多个索引的,那么我们查询数据的时候不指定索引,MySQL就会帮我们自动选择。既然是MySQL程序帮我们自动选择的那么会不会有问题的呢?答案是会的,MySQL的优化器也有bug,有时候选择的索引并不是最优的。
案例1
假如一张表有10w的数据,有id主键和a,b普通索引,执行以下SQL
select * from t where a between 10000 and 20000;
select * from t force index(a) where a between 10000 and 20000;
在一定的前提下
执行第一句代码走的是全表查询,扫描了10w行
执行第二句,强制使用a索引,只扫描了10001行
为啥会出现这种情况呢?我们就从优化器的逻辑开始研究
优化器的逻辑
优化器优化判断的指标
有需要扫描的行数,是否使用临时表,是否排序等因素
扫描行数判断
上面的案例明显就是扫描行数的问题
那么优化器是怎么获取扫描的总行数的,其实就和抽样检查类似,因为索引是有序的,就可以使用采样统计这种算法算出大概的扫描行数,可以通过show index查看索引的Cardinality预估值。
案例分析
我们通过explain来查看案例的扫描行数的预估值
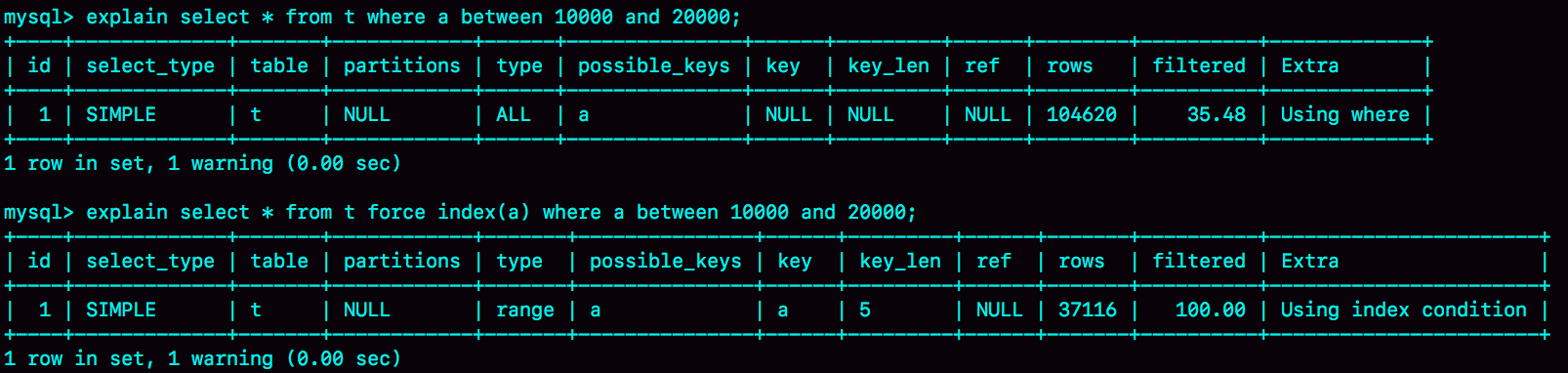
rows字段就是预计的扫描行数,可见第二个选择a索引查询的预估扫描行数存在比较大的偏差
问题?
根据结果我们发现走a索引就算是扫描3w7行,也还是比10w快啊,为啥还是选择了全表扫描,因为我们只考虑了扫描行数却没有考虑到回表这个操作,如果加上回表的一些操作那么优化器就会认为还不如走全表查询来的快,所以优化器选择了全表查询。
解决
我们知道问题出在了扫描行的预估不正确,要是出现预估和现实差别比较大的情况的就可以使用analyze table zx的命令来重新预估来改变。
案例2
还是上面的表数据的格式是(1,1,1),10w条
select * from (select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 100)alias limit 1;
explain

又又又选择错了
原因
为啥会选错呢,其实主要就是时排序的问题,优化器认为按索引a查询出来的数据b不是有序的,还要排序(其实是有序的),所以它选择了b索引,查询出来的数据直接就是有序的,效率会更高
怎么避免这些错误选择索引呢
1.直接force index直接强制指定查询使用的索引
2.analyze table zx重新计算预估的扫描行
3.引导sql的索引选择,比如order by
4.合理设置索引
5......................