P1140 相似基因
题目背景
大家都知道,基因可以看作一个碱基对序列。它包含了4种核苷酸,简记作A,C,G,T。生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物。
在一个人类基因工作组的任务中,生物学家研究的是:两个基因的相似程度。因为这个研究对疾病的治疗有着非同寻常的作用。
题目描述
两个基因的相似度的计算方法如下:
对于两个已知基因,例如AGTGATG和GTTAG,将它们的碱基互相对应。当然,中间可以加入一些空碱基-,例如:
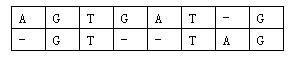
这样,两个基因之间的相似度就可以用碱基之间相似度的总和来描述,碱基之间的相似度如下表所示:
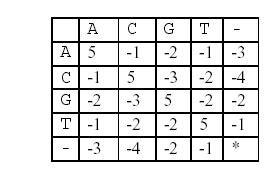
那么相似度就是:(-3)+5+5+(-2)+(-3)+5+(-3)+5=9。因为两个基因的对应方法不唯一,例如又有:
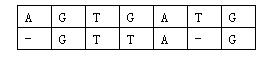
相似度为:(-3)+5+5+(-2)+5+(-1)+5=14。规定两个基因的相似度为所有对应方法中,相似度最大的那个。
输入输出格式
输入格式:
共两行。每行首先是一个整数,表示基因的长度;隔一个空格后是一个基因序列,序列中只含A,C,G,T四个字母。1<=序列的长度<=100。
输出格式:
仅一行,即输入基因的相似度。
输入输出样例
输入样例#1:
7 AGTGATG 5 GTTAG
输出样例#1:
14
第一眼看到题,这不是最长公共子序列,然而我并没有写过,gg......
然后开始乱造,我觉得没人会和我一样用这么蠢的写法了......
1 #include<iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<algorithm> 5 using namespace std; 6 int val[300][300]; 7 int len1,len2; 8 char s1[110],s2[110]; 9 int f[110][110]; 10 int main(){ 11 ios::sync_with_stdio(false); 12 val['A']['A']=val['C']['C']=val['G']['G']=val['T']['T']=5; 13 val['A']['C']=val['C']['A']=val['A']['T']=val['T']['A']=val['T']['-']=val['-']['T']=-1; 14 val['A']['G']=val['G']['A']=val['G']['T']=val['T']['G']=val['C']['T']=val['T']['C']=val['G']['-']=val['-']['G']=-2; 15 val['C']['G']=val['G']['C']=val['A']['-']=val['-']['A']=-3; 16 val['C']['-']=val['-']['C']=-4; 17 cin>>len1>>s1>>len2>>s2; 18 for(int i=1;i<=len1;i++) f[i][0]=f[i-1][0]+val[s1[i-1]]['-']; 19 for(int i=1;i<=len2;i++) f[0][i]=f[0][i-1]+val[s2[i-1]]['-']; 20 for(int i=0;i<=len1-1;i++) 21 for(int j=0;j<=len2-1;j++) 22 f[i+1][j+1]=max(max(f[i][j]+val[s1[i]][s2[j]],f[i+1][j]+val['-'][s2[j]]),f[i][j+1]+val[s1[i]]['-']); 23 cout<<f[len1][len2]; 24 return 0; 25 }