make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。
make_blobs(n_samples=100, n_features=2,centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None)
n_samples是待生成的样本数量,n_features是每个样本的特征数,centers是簇数量,也可以直接指定每个簇的中心点centers=[[-1,1],[1,2],[3,3]],cluster_std是每个簇的方差,赋给cluter_std一个参数代表所有簇方差都一样,也可制定各个簇的方差cluster_std=[10,6,25],shuffle数据洗牌,默认不用设置,random_state是随机种子,默认随机种子,也可以自己指定。
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
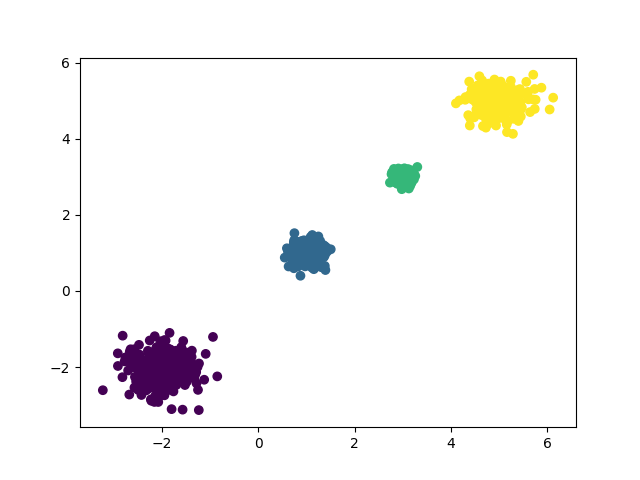
# data为样本特征,target为样本簇类别, 共1000个样本,每个样本2个特征, 共4个簇, 簇中心在[-2,-2],[1,1],[3,3],[5,5], 簇方差分别为[0.4,0.2,0.1,0.3]
data, target = make_blobs(n_samples=1000, n_features=2, centers=[[-2,-2],[1,1],[3,3],[5,5]], cluster_std=[0.4,0.2,0.1,0.3], random_state=7)
#画图 c=target代表不同簇不同颜色,marker='o'是用来指定数据的显示形状
plt.scatter(data[:, 0], data[: ,1], c=target, marker='o')
plt.show()