
那么Hystrix的作用是什么呢?具体要保护什么呢?
Hystrix是Netflflix开源的一个延迟(latency)和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败。
雪崩问题:一个服务不可用导致所有服务都不可用
微服务中,服务间调用关系错综复杂,一个请求,可能需要调用多个微服务接口才能实现,会形成非常复杂的调用链路:
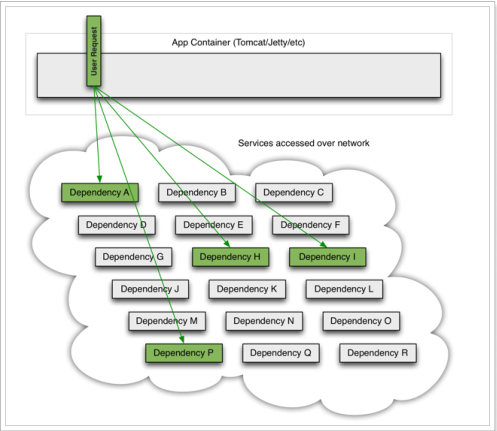
如图,一次业务请求,需要调用A、P、H、I四个服务,这四个服务又可能调用其它服务。这四个服务在正常情况下,请求被顺利的处理完,后面的请求也一样进入并被处理;如果这些请求在调用这些服务的过程中,有一个服务出现了异常的话,那么这个请求就不能顺利结束,从而进行等待,但是Tomcat不会释放这个请求的线程。
如果此时,某个服务出现异常:
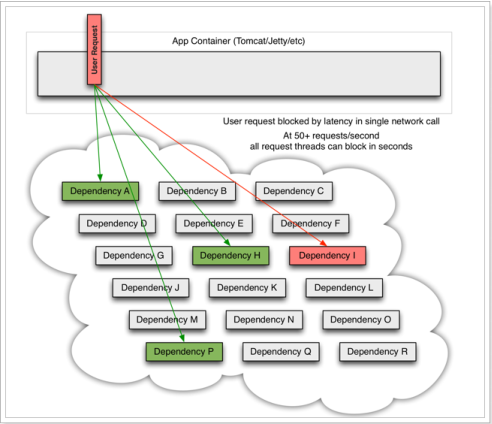
例如: 微服务I 发生异常,请求阻塞,用户请求就不会得到响应,则tomcat的这个线程不会释放,于是越来越多的用户请求到来,越来越多的线程会阻塞:
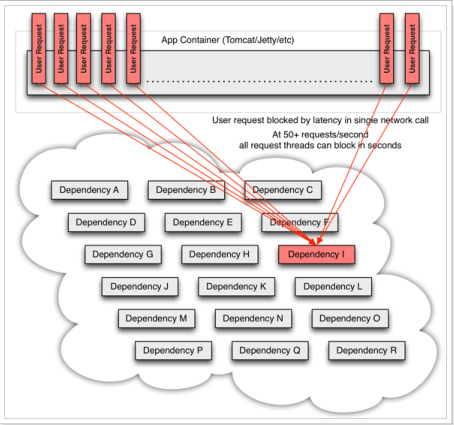
服务器支持的线程和并发数有限,请求一直阻塞,会导致服务器资源耗尽,从而导致所有其它服务都不可用,形成雪崩效应。
Hystrix解决雪崩问题的手段主要是服务降级,包括:线程隔离和服务熔断
线程隔离:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,加速失败判断时间
原理
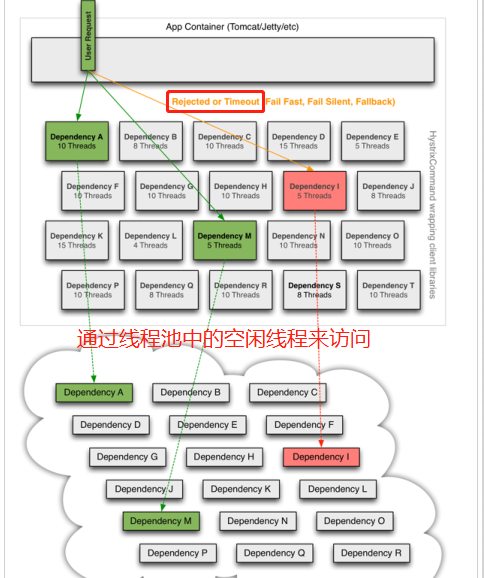
解读:
1、Hystrix为每个依赖服务调用分配一个小的线程池,如果线程池已满调用将被立即拒绝(rejected),默认不采用排队,加速失败判定时间。
2、用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,或者请求超时(timeout),则会进行降级处理,什么是服务降级?
服务降级:及时返回服务调用失败的结果,让线程不因为等待服务而阻塞。优先保证核心服务,而非核心服务不可用或弱可用。
触发Hystrix服务降级的情况:线程池已满或请求超时
用户的请求故障时,不会被阻塞,更不会无休止的等待或者看到系统崩溃,至少可以看到一个执行结果(例如返回友好的提示信息) 。
服务降级虽然会导致请求失败,但是不会导致阻塞,而且最多会影响这个依赖服务对应的线程池中的资源,对其它服务没有响应。
快速入门
1、在服务消费方引入依赖spring-cloud-starter-netflix-hystrix,为什么在服务消费方?因为服务消费方要调用服务提供方,而我们让服务提供方停机,且在服务消费方编写降级逻辑,从而及时返回结果,这样才能模拟隔离访问远程服务。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
2、开启熔断,在服务消费方的启动类 ConsumerApplication 上添加注解:@EnableCircuitBreaker(开启断路器)
@SpringBootApplication @EnableDiscoveryClient @EnableCircuitBreaker public class ConsumerApplication { public static void main(String[] args) { SpringApplication.run(ConsumerApplication.class,args); }
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
可以看到,我们类上的注解越来越多,在微服务中,经常会引入上面的三个注解,于是Spring就提供了一个组合注解:@SpringCloudApplication(不是SpringBootApplication)因此,我们可以使用这个组合注解来代替之前的3个注解。
@Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Inherited @SpringBootApplication @EnableDiscoveryClient @EnableCircuitBreaker public @interface SpringCloudApplication { }
@SpringCloudApplication public class ConsumerApplication { public static void main(String[] args) { SpringApplication.run(ConsumerApplication.class,args); }
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
3、编写降级逻辑,当目标服务的调用出现故障,我们希望快速失败,给用户一个友好提示。因此需要提前编写好失败时的降级处理逻辑,要使用@HystrixCommand注解来完成。改造ConsumerController
如果想输出日志到控制台,可以用Lombok的@Slf4j注解,这样就不用每次都写private final Logger logger = LoggerFactory.getLogger(当前类名.class),在方法中直接使用log的error方法输出信息控制台,{}是占位符,用后面的变量值代替它。Log还有debug、info、warn方法
@RestController @RequestMapping("/consumer") @Slf4j public class ConsumerController { @Autowired private RestTemplate restTemplate; @GetMapping("/{id}") @HystrixCommand(fallbackMethod = "queryByIdFallBack") public String queryById(@PathVariable Long id){ String url = "http://user-service/user/"+id; return restTemplate.getForObject(url,String.class); } public String queryByIdFallBack(Long id){ log.error("查询用户信息失败。id:{}",id); return "对不起,网络太拥挤了!"; } }
要注意;因为熔断的降级逻辑方法必须跟正常逻辑方法保证相同的参数列表和返回值声明。
失败逻辑中返回User对象没有太大意义,一般会返回友好提示。所以把queryById的方法改造为返回String,反正也是Json数据。这样失败逻辑中返回一个错误说明,会比较方便。
@HystrixCommand(fallbackMethod = "queryByIdFallBack"):用来声明一个降级逻辑的方法
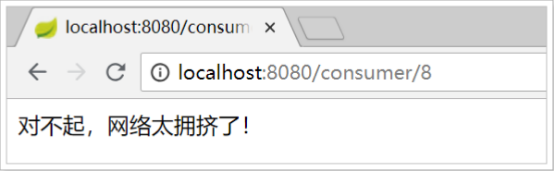
4、测试:访问http://localhost:9092/consumer/8,当 user-service 正常提供服务时,访问与以前一致,第一次访问可能失效,因为超过了超时时间。
但是当将 user-service 停机时,会发现页面返回了降级处理信息:
5、默认的Fallback,刚才把fallback写在了某个业务方法上,如果这样的方法很多,那岂不是要写很多。所以可以把Fallback配置加在Controller类上,实现默认fallback;再次改造ConsumerController,
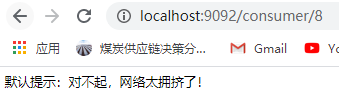
@RestController @RequestMapping("/consumer") @Slf4j @DefaultProperties(defaultFallback = "defaultFallBack") public class ConsumerController { @Autowired private RestTemplate restTemplate; @GetMapping("/{id}") @HystrixCommand public String queryById(@PathVariable Long id){ String url = "http://user-service/user/"+id; return restTemplate.getForObject(url,String.class); } public String defaultFallBack(){ return "默认提示:对不起,网络太拥挤了!"; } }
@DefaultProperties(defaultFallback = "defaultFallBack"):在类上指明统一的失败降级方法;该类中所有方法返回类型要与处理失败的方法的返回类型一致。失败降级方法没有参数。
访问结果如下:
6、超时设置,在之前的案例中,第一次访问时,请求时间超过了1s,请求在超过1秒后都会到降级方法中处理,返回错误信息,这是因为Hystrix的默认超时时长为1s,我们可以通过配置修改这个值;修改服务消费方的application.yml 添加如下配置:
hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 2000
为了方便复制到yml配置文件中,可以复制hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=2000 到yml文件中会自动格式化后再进行修改。
启动user-service,访问http://localhost:9092/consumer/8,能够正常获取结果。如果在user-service设置休眠2s,则会触发超时,从而进行降级处理。
请求超时(timeout),也会进行降级处理。
为了触发超时,可以在UserService的方法中休眠2秒;
@Service public class UserService { @Autowired private UserMapper userMapper; public User queryById(Long id){ try{ Thread.sleep(2000); }catch(InterruptedException e){ e.printStackTrace(); } User user = userMapper.selectByPrimaryKey(id); System.out.println(user); return user; } }
可以发现,请求的时长已经到了2s+,证明配置生效了。访问结果如下:
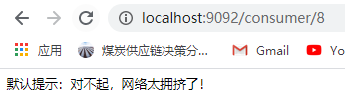
如果把修改时间修改到2秒以下,又可以正常访问。
服务熔断(断开):自己进行判断是否断开,不需要我们处理
熔断原理
在服务熔断中,使用的熔断器,也叫断路器,其英文单词为:Circuit Breaker
熔断机制与家里使用的电路熔断原理类似;当如果电路发生短路的时候能立刻熔断电路,避免发生灾难。在分布式系统中应用服务熔断后;服务调用方可以自己进行判断哪些服务反应慢或存在大量超时,可以针对这些服务进行主动熔断,防止整个系统被拖垮。
Hystrix的服务熔断机制,可以实现弹性容错;当服务请求情况好转之后,可以自动重连。通过断路的方式,将后续请求直接拒绝,一段时间(默认5秒)之后允许部分请求通过,如果调用成功则回到断路器关闭状态,否则继续打开,拒绝请求的服务。
Hystrix的熔断状态机模型:
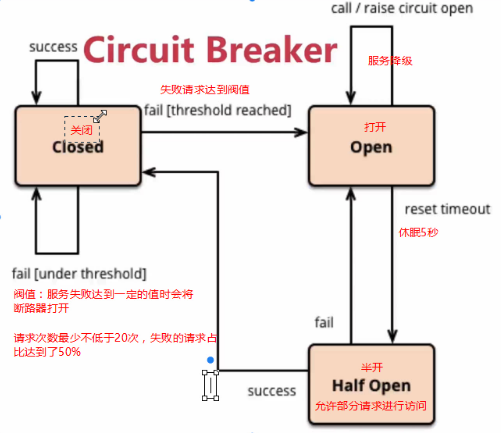
状态机有3个状态:
1、Closed:关闭状态(断路器关闭),所有请求都正常访问。
2、Open:打开状态(断路器打开),所有请求都会被降级。Hystrix会对请求情况计数,当一定时间内失败请求百分比达到阈值threshold,则触发熔断,断路器会完全打开。默认失败比例的阈值是50%,请求次数最少不低于20次。
3、Half Open:半开状态,不是永久的,断路器打开后会进入休眠时间(默认是5S)。随后断路器会自动进入半开状态。此时会释放部分请求通过,若这些请求都是健康的,则会关闭断路器,否则继续保持打开,再次进行休眠计时
为了能够精确控制请求的成功或失败,在 consumer-demo 的处理器业务方法中加入一段逻辑;修改ConsumerController,
@RestController @RequestMapping("/consumer") @Slf4j @DefaultProperties(defaultFallback = "defaultFallBack") public class ConsumerController { @Autowired private RestTemplate restTemplate; @GetMapping("/{id}") @HystrixCommand public String queryById(@PathVariable Long id){ if(id == 1){ throw new RuntimeException("太忙了"); } String url = "http://user-service/user/"+id; return restTemplate.getForObject(url,String.class); } public String defaultFallBack(){ return "默认提示:对不起,网络太拥挤了!"; } }
这样如果参数是id为1,一定失败,其它情况都成功。(不要忘了清空user-service中的休眠逻辑)
我们准备两个请求窗口:
一个请求:http://localhost:9092/consumer/1,注定失败
一个请求:http://localhost:9092/consumer/8,肯定成功
当我们疯狂访问id为1的请求时(超过20次),就会触发熔断。断路器会打开,一切请求都会被降级处理。此时再次访问http://localhost:9092/consumer/8,就会出现如下结果:
不过,默认的熔断触发要求较高,休眠时间窗较短,为了测试方便,我们可以通过配置修改熔断策略:
hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 2000 circuitBreaker: errorThresholdPercentage: 50 # 触发熔断错误比例阈值,默认值50% sleepWindowInMilliseconds: 10000 # 熔断后休眠时长,默认值5秒 requestVolumeThreshold: 10 # 熔断触发最小请求次数,默认值是20
hystrix.command.default.circuitBreaker.requestVolumeThreshold=10 hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=10000 hystrix.command.default.circuitBreaker.errorThresholdPercentage=50 hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=2000