今天对一些Linux的基础命令进行了复习,并完成了spark实验一。做了一些总结。
1. 切换目录
cd /home/hadoop #把/home/hadoop设置为当前目录
cd .. #返回上一级目录
cd ~ #进入到当前Linux系统登录用户的主目录(或主文件夹)。在 Linux 系统中,~代表的是用户的主文件夹,即“/home/用户名”这个目录,如果当前登录用户名为 hadoop,则~就代表“/home/hadoop/”这个目录
2.列出目录命令ls
-a 显示所有文件及目录 (ls内定将文件名或目录名称开头为"."的视为隐藏档,不会列出)
-l 除文件名称外,亦将文件型态、权限、拥有者、文件大小等资讯详细列出
-r 将文件以相反次序显示(原定依英文字母次序)
-t 将文件依建立时间之先后次序列出
-A 同 -a ,但不列出 "." (目前目录) 及 ".." (父目录)
-F 在列出的文件名称后加一符号;例如可执行档则加 "*", 目录则加 "/"
-R 若目录下有文件,则以下之文件亦皆依序列出
3.创建目录 mkdir
mkdir input #在当前目录下创建input子目录
mkdir -p src/main/scala #在当前目录下,创建多级子目录src/main/scala
4.移动文件或改名 mv

5.查看文件内容,创建文件,文件合并。cat
cat f1.txt,查看f1.txt文件的内容。
cat -n f1.txt,查看f1.txt文件的内容,并且由1开始对所有输出行进行编号。
cat -b f1.txt,查看f1.txt文件的内容,用法与-n相似,只不过对于空白行不编号。
cat -s f1.txt,当遇到有连续两行或两行以上的空白行,就代换为一行的空白行。
cat -e f1.txt,在输出内容的每一行后面加一个$符号。
cat f1.txt f2.txt,同时显示f1.txt和f2.txt文件内容,注意文件名之间以空格分隔,而不是逗号。
cat -n f1.txt>f2.txt,对f1.txt文件中每一行加上行号后然后写入到f2.txt中,会覆盖原来的内容,文件不存在则创建它。
cat -n f1.txt>>f2.txt,对f1.txt文件中每一行加上行号后然后追加到f2.txt中去,不会覆盖原来的内容,文件不存在则创建它。
来源:https://blog.csdn.net/gzpgood/article/details/81001880
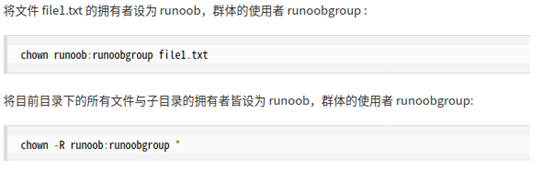
6.修改文件和目录的所有者和所属组 chown
7.删除目录或文件 rm
rm ./word.txt #删除当前目录下的word.txt文件
rm –r ./test #删除当前目录下的test目录及其下面的所有文件
rm –r test* #删除当面目录下所有以test开头的目录和文件
8.tar命令
压缩文件命令格式:tar -zcvf 【目录】/ 【压缩包文件名.tar.gz】【源文件】
解压到指定文件夹下命令格式为:tar -zxvf 【压缩包文件名.tar.gz】 -C 【路径】/
tar -zxf ~/下载/spark-2.1.0.tgz -C /usr/local/ #把spark-2.1.0.tgz这个压缩文件解压到/usr/local目录下