上一篇《Java中的集合框架-Collection(一)》把Java集合框架中的Collection与List及其常用实现类的功能大致记录了一下,本篇接着记录Collection的另一个子接口Set及其实现类。
一,Collection子接口Set
Set接口与List接口同时是Collection接口的子接口,但两者区别还是很大的。
首先,Set里的方法与Collection里的方法完全一样;
其次,Set是无序的,即Set的存储与取出顺序可能不一致;演示如下:
1 private static void function_demo9() {
2 Set set = new HashSet();
3 set.add(7);
4 set.add(4);
5 set.add(3);
6 Iterator it = set.iterator();
7 while (it.hasNext()) {
8 System.out.println(it.next());
9 }
10 }

1 private static void function_demo9() {
2 Set set = new HashSet();
3 set.add(7);
4 set.add(4);
5 set.add(3);
6 set.add(3);
7 Iterator it = set.iterator();
8 while (it.hasNext()) {
9 System.out.println(it.next());
10 }
11 }
程序运行结果:
可见Set里存储相同的元素时不能被放到容器里。
二,Set常用实现类
Set接口也有很多的实现类,比较常用的也有三个:HashSet,TreeSet,LinkedHashSet,我们再次完善一下Collection接口的类图,如下:
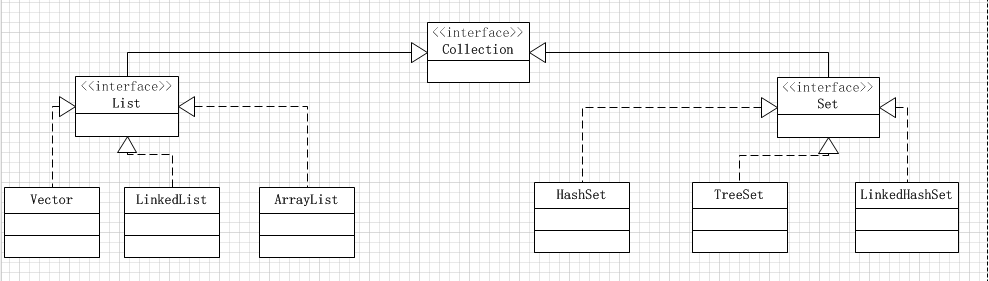
1,Set常用实现类-HashSet
HashSet实现了Set接口,它是非同步,不保证顺序的一个集合,查看源码可知,其实HashSet内部维护的是一个HashMap,只是value值的是一个Object对象而已。
HashSet使用hash算法存储数据,在存储的时候,先去判断hashcode是否相同,若相同的情况下再去判断对象的内容是否相同;
在判断hashcode是否相同的时候用的是hashcode方法,在判断内容是否相同的时候用的是equals方法;
若hashcode不同则不必再去判断对象内容即不会再调用equals方法;
看下面一个例子,HashSet里存储自定义的对象类型
1 public class Person {
2 public Person(String name, int age) {
3 super();
4 this.name = name;
5 this.age = age;
6 }
7
8 private String name;
9
10 public String getName() {
11 return name;
12 }
13
14 public void setName(String name) {
15 this.name = name;
16 }
17
18 public int getAge() {
19 return age;
20 }
21
22 public void setAge(int age) {
23 this.age = age;
24 }
25
26 private int age;
27 }
1 private static void function_demo10() {
2 HashSet hs = new HashSet();
3 hs.add(new Person("张三", 32));
4 hs.add(new Person("李四", 12));
5 hs.add(new Person("赵五", 12));
6 hs.add(new Person("马七", 56));
7 hs.add(new Person("马七", 56));
8 for (Iterator iterator = hs.iterator(); iterator.hasNext();) {
9 System.out.println(((Person)iterator.next()).getName());
10 }
11 }
程序运行结果:

我们知道,Set里是不可以存储重复的元素的,但为何上面可以存储两个“马七”?
分析一下,我们存储对象的时候用的是new Person()的方式,前面说过,HashSet在存储的时候先会去判断每个对象的hashcode是否相同,那么每次new出来的Person对象的hashcode值肯定是不相同的,所以HashSet直接就判断这两个对象不是同一个对象但存储进去了,若想完成这个去除重复的存储,可以先让Person类重写hashcode方法,修改如下:
1 public class Person {
2 public Person(String name, int age) {
3 super();
4 this.name = name;
5 this.age = age;
6 }
7
8 private String name;
9
10 public String getName() {
11 return name;
12 }
13
14 public void setName(String name) {
15 this.name = name;
16 }
17
18 public int getAge() {
19 return age;
20 }
21
22 public void setAge(int age) {
23 this.age = age;
24 }
25
26 private int age;
27
28 @Override
29 public int hashCode() {
30 return this.name.hashCode();
31 }
32 }
此时再运行程序便会发现,”马七“还是两个了。其实HashSet在存储元素的时候,会拿两个元素的hashcode去做比较,此时若hashcode相同便去比较两个元素的内容,调用的是该元素的equals方法;若hashcode不同则存储该元素。因为Person重写了hashcode方法,但hashcode方法里我们返回的是当前对象的name的hashcode值;当往HashSet存储Person对象时,存储第二个”马七“时hashcode值还是一样的,便会去调用对象的equals方法,但是equals方法比较的是堆里的地址,两个对象在堆里的地址是不一样的,所以判定还是两个不同的对象,所以还是出来了两个”马七“。为了解决这个问题,我们再把Person类的equals方法重写一下,代码如下:
1 public class Person {
2 public Person(String name, int age) {
3 super();
4 this.name = name;
5 this.age = age;
6 }
7
8 private String name;
9
10 public String getName() {
11 return name;
12 }
13
14 public void setName(String name) {
15 this.name = name;
16 }
17
18 public int getAge() {
19 return age;
20 }
21
22 public void setAge(int age) {
23 this.age = age;
24 }
25
26 private int age;
27
28 @Override
29 public int hashCode() {
30 return this.name.hashCode();
31 }
32
33 @Override
34 public boolean equals(Object obj) {
35 if (this == obj)
36 return true;
37 if (obj == null)
38 return false;
39 if (getClass() != obj.getClass())
40 return false;
41 Person other = (Person) obj;
42 if (age != other.age)
43 return false;
44 if (name == null) {
45 if (other.name != null)
46 return false;
47 } else if (!name.equals(other.name))
48 return false;
49 return true;
50 }
51
52 }
此时再运行程序,发现只有一个”马七“了。
2,Set常用类-LinkedHashSet
LinkedHashSet继承自HashSet,不同步;
LinkedHashSet与HashSet的区别是它内部数据结构是双向链表的形式,它能保证存储的顺序与取出的顺序是一致的;
LinkedHashSet里面所有的方法都是从HashSet继承而来的,这里演示一下它有HashSet的区别,如下:
1 private static void function_demo12() {
2 HashSet hs = new HashSet();
3 hs.add(1);
4 hs.add(6);
5 hs.add(2);
6 hs.add(4);
7 hs.add(3);
8 System.out.println("HashSet存取不一致:"+hs);
9 LinkedHashSet lhs = new LinkedHashSet();
10 lhs.add(1);
11 lhs.add(6);
12 lhs.add(2);
13 lhs.add(4);
14 lhs.add(3);
15 System.out.println("LinkedHashSet存取一致:"+lhs);
16 }
3,Set常用类-TreeSet
TreeSet内部其实是TreeMap的形式, 是二叉树的数据结构,它是非同步的;
TreeSet可对存储的元素按照自然顺序进行排序;
1 private static void function_demo13() {
2 TreeSet ts = new TreeSet();
3 ts.add("1");
4 ts.add("4");
5 ts.add("2");
6 ts.add("3");
7 ts.add("abc");
8 ts.add("zzd");
9 ts.add("adef");
10 ts.add("mnjuk");
11 ts.add("aaac");
12 System.out.println(ts);
13 }

1 private static void function_demo14() {
2 TreeSet ts = new TreeSet();
3 ts.add(new Person("张三", 32));
4 ts.add(new Person("李四", 12));
5 ts.add(new Person("赵五", 12));
6 ts.add(new Person("马七", 56));
7 ts.add(new Person("马七", 56));
8 }
程序运行x结果:

报错说Person类不能转成Comparable。原因就是当往TreeSet存储元素的时候,因为TreeSet会使用二叉树算法对元素进行排序,它会找比较的依据进行存储,那么这个被存储的对象就要具备比较的功能,这个具备比较功能的接口就是Comoparable;那么存储字符串的时候为什么没报错呢?原因是String已经实现了Comparable接口,具备了比较的功能,下面我们让Person类实现这个接口,代码如下:
1 public class Person implements Comparable {
2 public Person(String name, int age) {
3 super();
4 this.name = name;
5 this.age = age;
6 }
7
8 private String name;
9
10 public String getName() {
11 return name;
12 }
13
14 public void setName(String name) {
15 this.name = name;
16 }
17
18 public int getAge() {
19 return age;
20 }
21
22 public void setAge(int age) {
23 this.age = age;
24 }
25
26 private int age;
27
28 @Override
29 public int compareTo(Object o) {
30 return 0;
31 }
32
33 }
Comparable接口强行对实现它的类的对象的元素进行整体的排序,它里面只有一个compareTo方法,此方法返回0表示相等,负数表示小于,正数表示大于,此时程序运行结果如下:
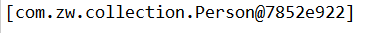
可以看到,我们往TreeSet里添加了五个元素,但是此时只添加了一个Person对象进去,出现这样问题的原因就是我们在重写了Comparable里的compareTo方法后直接返回了0,它说明添加的所有的元素都是同一个元素,所以只添加一个元素到了容器中,我们再次修改Person对象里的coompareTo方法,代码如下:
1 public class Person implements Comparable {
2 public Person(String name, int age) {
3 super();
4 this.name = name;
5 this.age = age;
6 }
7
8 private String name;
9
10 public String getName() {
11 return name;
12 }
13
14 public void setName(String name) {
15 this.name = name;
16 }
17
18 public int getAge() {
19 return age;
20 }
21
22 public void setAge(int age) {
23 this.age = age;
24 }
25
26 private int age;
27
28 @Override
29 public int compareTo(Object o) {
30 Person person = null;
31 if (o instanceof Person) {
32 person = (Person) o;
33 }
34 return this.getName().hashCode() - person.getName().hashCode();
35 }
36
37 }
此时程序运行结果是: 
四个元素添加成功了,并且没有重复的元素。
TreeSet在存储自定义对象的时候,还有另外一种不去让对象实现Comparable接口而可以进行排序的方法,那就是在实例化TreeSet的时候,调用带比较器Comparator的构造函数;
Comparator接口有两个方法,一个compare,另一个是equals方法;操作如下:
实现了Comparator接口的自定义比较器对象代码:
1 public class MyComparator implements Comparator {
2
3 @Override
4 public int compare(Object o1, Object o2) {
5 Person p1 = (Person) o1;
6 Person p2 = (Person) o2;
7 return p1.getName().hashCode() - p2.getName().hashCode();
8 }
9
10 }
主程序代码如下:
1 private static void function_demo15() {
2 TreeSet ts = new TreeSet(new MyComparator());
3 ts.add(new Person("张三", 32));
4 ts.add(new Person("李四", 12));
5 ts.add(new Person("赵五", 12));
6 ts.add(new Person("马七", 56));
7 ts.add(new Person("马七", 56));
8 System.out.println(ts);
9 }
程序运结果和让Person类实现Comparable接口的结果是一样的