熵 ,KL散度,交叉熵,JS散度,Wasserstein 距离(EarthMover距离)
信息量
香农(Shannon)认为“信息是用来消除随机不确定性的东西”,也就是说衡量一个事件信息量大小就看这个信息消除事件不确定性的程度。
从编码的角度
设信源X可发出的消息符号集合为\(A= { a_i | i = 1,2,…m }\)并设\(X\)发出符号\(a_i\)的概率为\(p(a_i)\),则定义符号\(a_i\)出现的自信息量为:
通常,式中的对数取2位底,这是定义的信息量单位为比特(bit)。
从信息的角度
信息论的基本想法是,一个不太可能的事件发生了的话,要比一个非常可能发生的事件提供更多的信息。如果想通过这种想法来量化信息,需要满足以下性质:
- 非常可能发生的事件信息量比较少,并且极端情况下,确定能够发生的事件没有信息量。
- 较不可能发生的事件具有更高的信息量。
- 独立事件应具有增量的信息。例如,投掷的硬币两次正面朝上传递的信息量,应该是投掷一次硬币正面朝上的信息量的两倍。
根据以上三点,定义自信息(self-information):
其中\(x\)表示事件,\(p(x)\)表示事件发生的概率。事件发生的概率越小,其信息量越大。
熵
从信息编码说起
信息论中熵的概念首次被香农提出,目的是寻找一种高效/无损地编码信息的方法:以编码后数据的平均长度来衡量高效性,平均长度越小越高效;同时还需满足“无损”的条件,即编码后不能有原始信息的丢失。这样,香农提出了熵的定义:无损编码事件信息的最小平均编码长度。(熵是所有压缩算法的极限。选择等可能的情况下,我们做不了任何压缩)
对于具有N种等可能性状态的信息,每种状态的可能性P = 1/N,编码该信息所需的最小编码长度为:
\[log_2 N = -log_2 \frac{1}{N} =-log_2 P \]计算平均最小长度,也就是熵的公式
\[Entropy = -\sum_i P(i) log_2 P(i) \]同样的,对于任一个离散的分布\(P(i)\),我们有
\[Entropy = -\sum_i P(i) log_2 P(i) \]对于连续变量的分布\(P(x)\),同样有
\[Entropy = -\int P(x) log_2 P(x) dx \]
熵编码是一种无损编码方式。最常见熵编码有霍夫曼(Huffman)编码,算术编码,还有行程编码 (RLE)、基于上下文的自适应变长编码(CAVLC)、基于上下文的自适应二进制算术编码(CABAC)。如霍夫曼编码便将将高频次(低熵)的编码用较短的编码表示,低频次(高熵)的用较长的编码表示
如果熵比较大(即平均编码长度较长),意味着这一信息有较多的可能状态,相应的每个状态的可能性比较低;因此每当来了一个新的信息,我们很难对其作出准确预测,即有着比较大的混乱程度/不确定性/不可预测性。并且当一个罕见的信息到达时,比一个常见的信息有着更多的信息量,因为它排除了别的很多的可能性,告诉了我们一个确切的信息。
熵是服从某一特定概率分布事件的理论最小平均编码长度,只要我们知道了任何事件的概率分布,我们就可以计算它的熵。
信息量的期望
信息熵为信源信息量的期望,即该信源所有可能发生事件的信息量的期望。可以表示为,
信息熵具有以下性质:
-
单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。
-
非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。
-
累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。
信息熵是用来衡量信源不确定性的。信息熵越大,信源越具不确定性,信源越复杂。熵越高,则包含的信息越多。
0-1分布问题(二项分布的特例),熵的计算方法可以简化为如下算式:
\[H(X) = - \sum_{i=1}^n p(x_i)log p(x_i) = -p(x)log(p(x)) - (1-p(x))log(1-p(x)) \]
相对熵 (KL散度)
相对熵,又被称为Kullback-Leibler散度或信息散度,是两个概率分布间差异的非对称性度量 。在信息理论中,相对熵等价于两个概率分布的信息熵的差值 ,也就是表示在知道p的情况下,至少要多少bit把q给描述出来。
相对熵是一些优化算法,例如最大期望算法(Expectation-Maximization algorithm, EM)的损失函数 。此时参与计算的一个概率分布为真实分布\(P\),另一个为拟合分布或者说模型预测出来的分布\(Q\),相对熵表示拟合真实分布时产生的信息损耗。
在机器学习中,一般p表示真实分布,而q表示预测分布,则相对熵定义为,
通过公式可以看出,q分布与p分布越接近,KL散度越小,相对熵越小。
- 因为对数函数是凸函数,所以KL散度的值为非负数。
有时会将KL散度称为KL距离,但它并不满足距离的性质:
- KL散度不是对称的;
- KL散度不满足三角不等式。
存在的问题
1 \(p>0,q \rightarrow 0\) , KL 中被积分部分趋近于无穷
2 \(p\rightarrow0,q >0\) .KL 中被积分部分趋近于0
交叉熵
我们将KL散度公式进行变形 :
等式的前一部分恰巧就是真实分布\(P\)的信息熵,为恒定值。等式的后一部分,就是交叉熵
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即 $KL(y||\hat{y}) $ ,由于KL散度中的前一部分\(−H(y)\)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
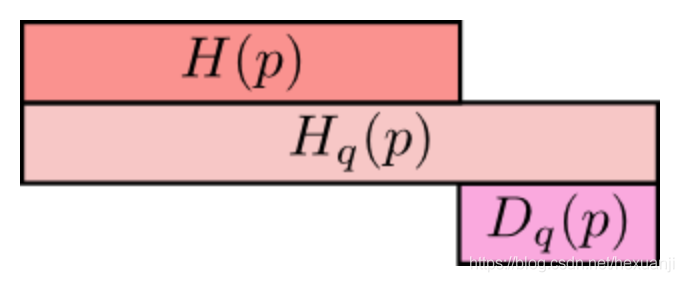
最上方\(H(p)\)为信息熵,表示分布\(p\)的平均编码长度/信息量;
中间的\(Hq(p)\)表示用分布q表编码分布p所含的信息量或编码长度,简称为交叉熵,其中\(Hq(p)>=H(p)\)
最小方的\(Dq(p)\)表示的是q对p的KL距离,衡量了分布q和分布p之间的差异性,其中\(Dq(p)>=0\);
从上图可知,\(Hq(p) = H(p) + Dq(p)\)
JS散度
JS散度度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度非对称的问题。一般地,JS散度是对称的,其取值是0到1之间。定义如下:
- 值域范围. JS散度的值域范围是[0,1],相同则是0,相反为1。相较于KL,对相似度的判别更确切了
- 对称性.即 \(JS(P||Q)=JS(Q||P)\)。
Wasserstein distance ( Kantorovich metric)
KL散度和JS散度度量的问题:
如果两个分布P,Q离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。这在学习算法中是比较致命的,这就意味这这一点的梯度为0。梯度消失了。
Wasserstein距离度量两个概率分布之间的距离,定义如下
式中\(\Pi(P_1,P_2)\)是 \(P_1\)和\(P_2\) 分布组合起来的所有可能的联合分布的集合。
对于每一个可能的联合分布γ,可以从中采样$(x,y)∼γ $得到一个样本x和y,并计算出这对样本的距离 \(||x−y||\),所以可以计算该联合分布γ下,样本对距离的期望值\(E(x,y)∼γ||x−y||\)。在所有可能的联合分布中能够对这个期望值取到的下界\(inf_{γ∼Π(P1,P2)}E_{(x,y)∼γ}||x−y||\)就是Wasserstein距离。
理解
Wasserstein metric - Wikipedia
Lecture 6 对抗生成网络GAN(2018) Wasserstein GAN(WGAN) 和 Energy-based GAN(EBGAN)_哔哩哔哩_bilibili 18:12
这里描述的是两个概率分布之间的距离。这个距离不是直观的几何上的距离,距离在数学上的定义是一个宽泛的概念,只要满足非负、自反、三角不等式就可以称之为距离。
我们想将一个分布移动到另一个分布,可以把分布想象称为土堆,我们每次取样,进行移动。这个过程像是推土机或者说挖掘机移动土堆,我们每次移动一点,最终把整个土堆移动完成,或者说是把土堆填到沟里。如果是离散的分布,那就是每次移动一个有质量的点。(实际上Wasserstein距离就是在最优路径下搬运过程的最小消耗,又被称作Earth-Mover Distance)

在一维分布时,很形象
但在二维上面,事实上有很多种方法,推土机距离就是定义为穷举所有的方案,距离最小的那个
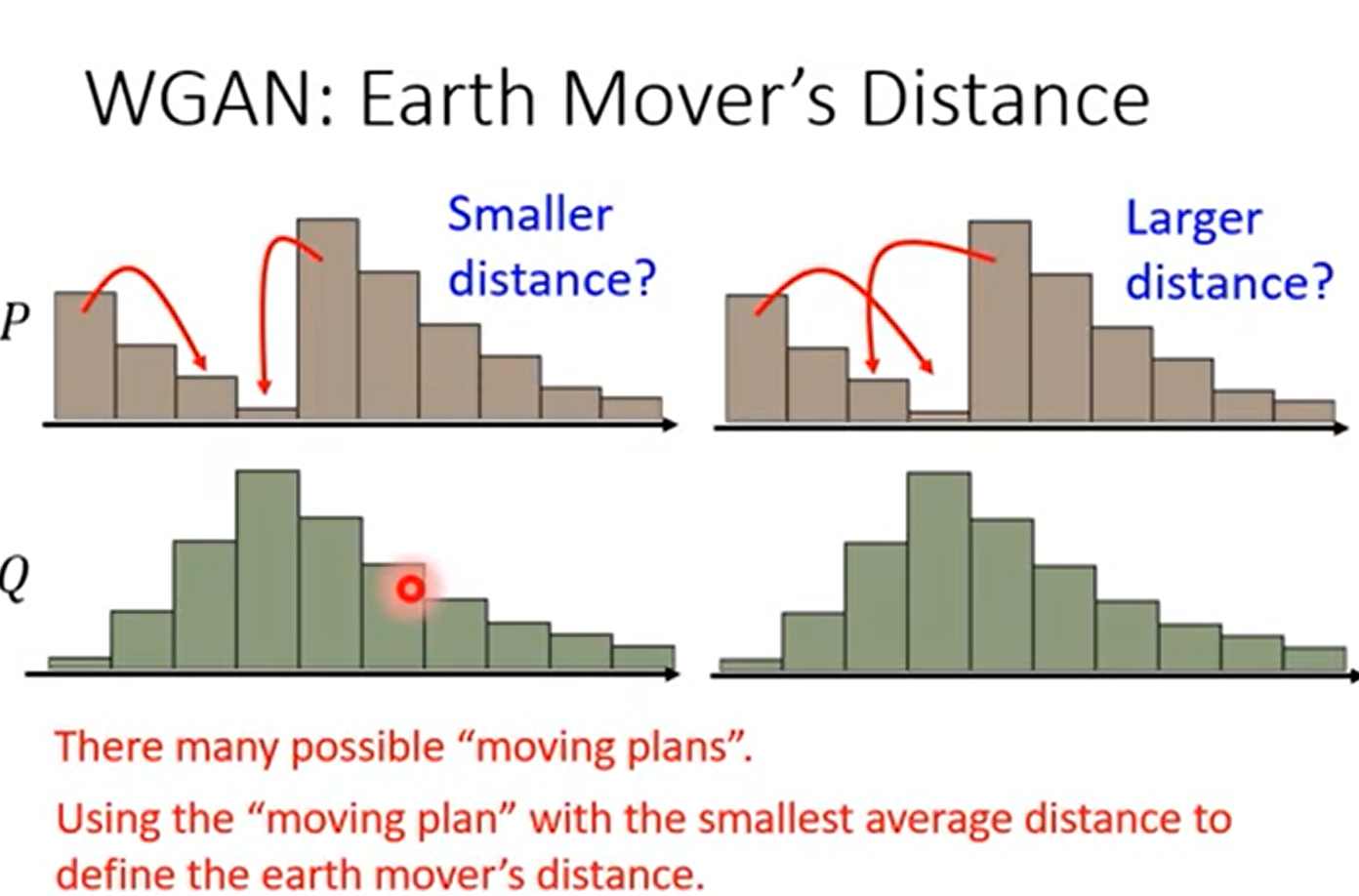
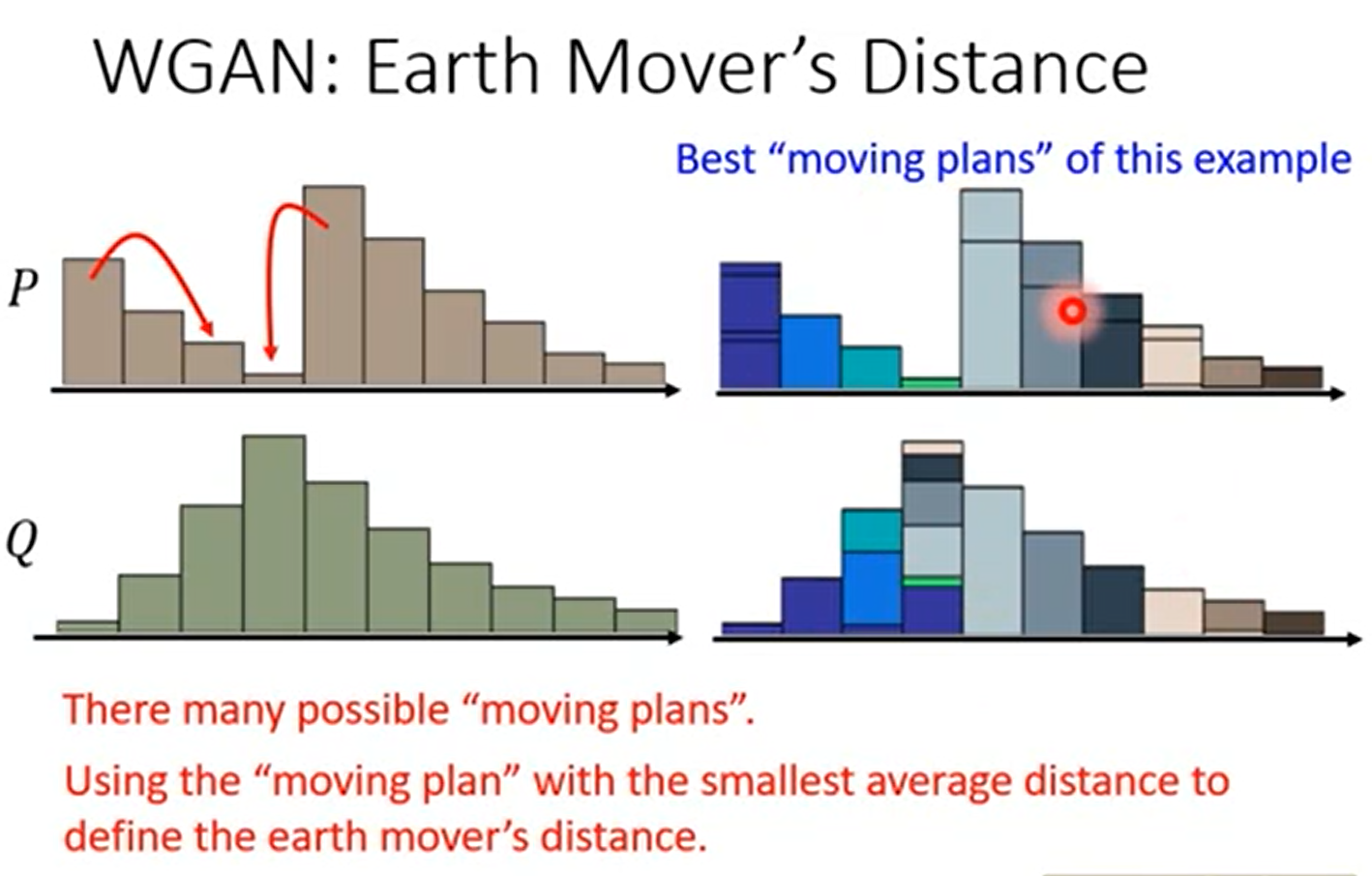
正式定义
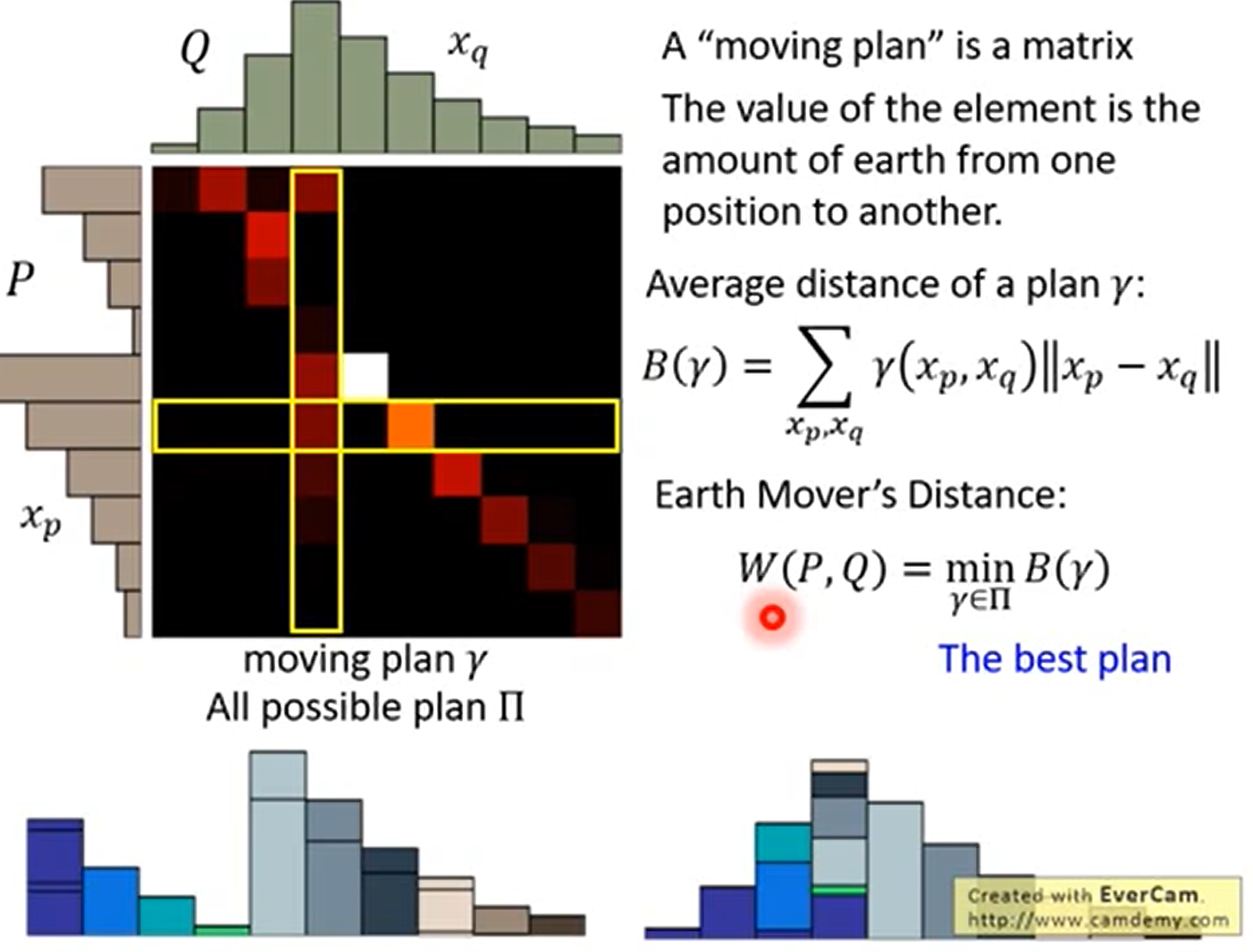
这里实际上是在所有的方案中,选择最小的那个方案得到的距离。
Earth Mover’s Distance 的优点
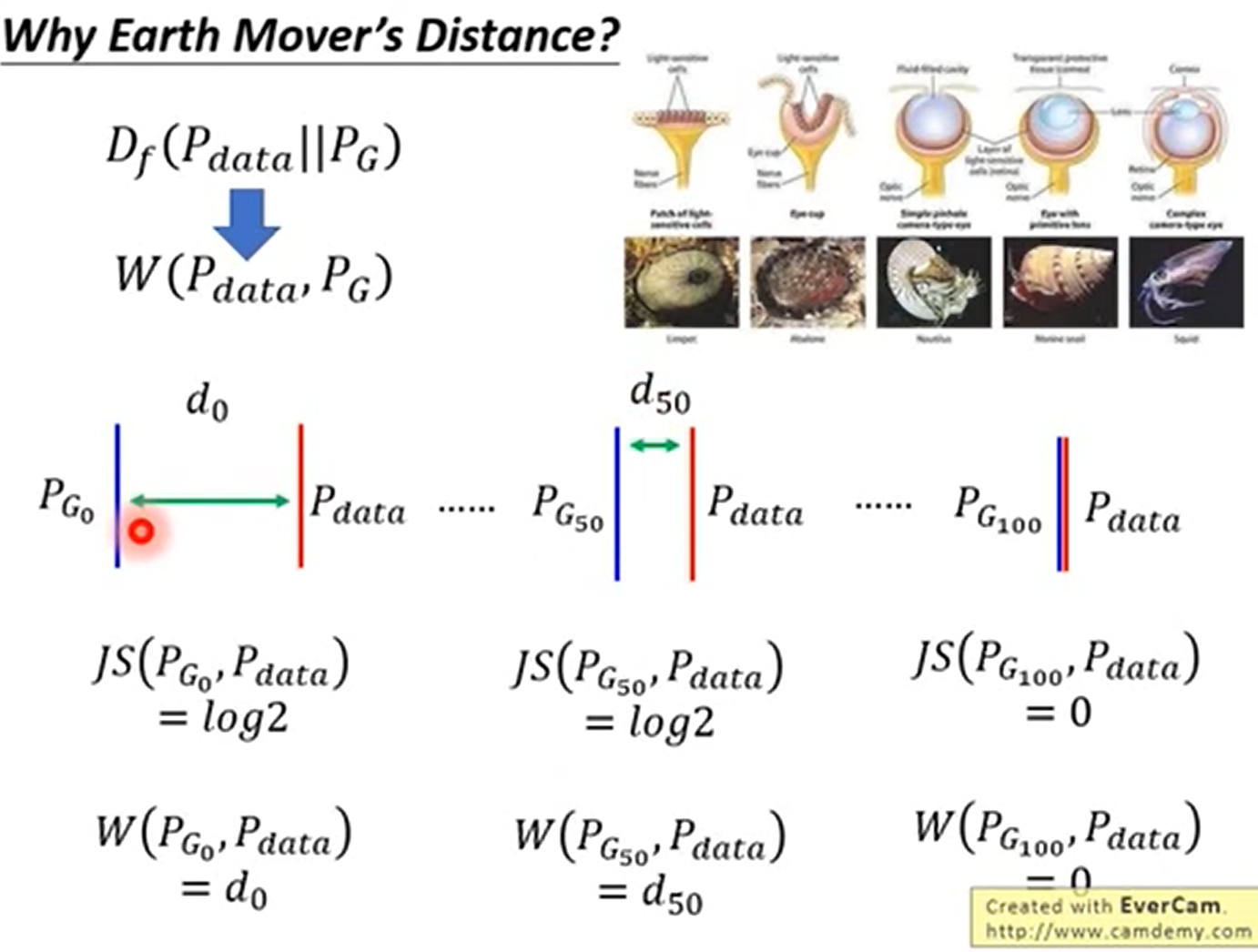
能够衡量不相交的时候的距离,并且距离越近效果越好
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近;而JS散度在此情况下是常量,KL散度可能无意义
考虑如下二维空间中的两个分布\(P_1\)和\(P_2\),\(P_1\)在线段AB上均匀分布,\(P_2\)在线段CD上均匀分布,通过控制参数\(\theta\)可以控制着两个分布的距离远近。
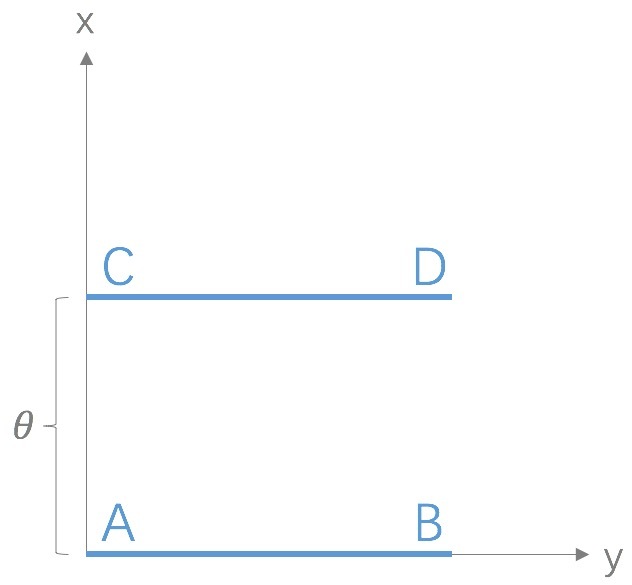
此时容易得到
(突变)
(突变)
(平滑)
KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
感谢
作者:lgdhang
链接:https://www.jianshu.com/p/5d9407376c7c
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处
交叉熵(Cross Entropy) - 简书 (jianshu.com)
一文搞懂熵(Entropy),交叉熵(Cross-Entropy) - 知乎 (zhihu.com)
【损失函数】交叉熵损失函数简介 - 知乎 (zhihu.com)
(12条消息) 数字视频编码概述(熵编码/Huffman编码)_Chen Yuanshen的专栏-CSDN博客
[交叉熵、相对熵(KL散度)、JS散度和Wasserstein距离(推土机距离) - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/74075915#:~:text=JS散度 度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度非对称的问题。,一般地,JS散度是对称的,其取值是0到1之间。 定义如下: 如果两个分配P%2CQ离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。)