1.Redis 简介
Redis是一个开源的高性能键值对数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求,并借助许多高层级的接口使其可以胜任如缓存、队列系统等不同的角色。本章将分别介绍Redis的历史和特性,以使读者能够快速地对Redis有一个全面的了解。
1.历史与发展
2008年,意大利的一家创业公司Merzia.推出了一款基于MySQL的网站实时统计系统LLOOGG ,然而没过多久该公司的创始人Salvatore Sanfilippo便开始对MySQL的性能感到失望,于是他决定亲自为LLOOGG量身定做一个数据库,并于2009年开发完成,这个数据库就是Redis。不过Salvatore Sanfilippo并不满足只将Redis用于LLOOGG这一款产品,而是希望让更多的人使用它,于是在同一年Salvatore Sanfilippo将Redis开源发布,并开始和Redis的另一名主要的代码贡献者Pieter Noordhuis一起继续着Redis的开发,直到今天。
Salvatore Sanfilippo自己也没有想到,短短的几年时间,Redis就拥有了庞大的用户群体。Hacker News在2012年发布了一份数据库的使用情况调查 ,结果显示有近12%的公司在使用Redis。国内如新浪微博、街旁和知乎,国外如GitHub、Stack Overflow、Flickr、暴雪和Instagram,都是Redis的用户。
VMware公司从2010年开始赞助Redis的开发,Salvatore Sanfilippo和Pieter Noordhuis也分别于同年的3月和5月加入VMware,全职开发Redis。
2.特点
作为一款个人开发的数据库,Redis究竟有什么魅力吸引了如此多的用户呢?
以字典结构存储数据
允许通过TCP协议读取字典的内容
强大的缓存系统, 可以为每个键设置TTL, 以及按照一定规则自动淘汰不需要的键
支持使用列表的形式构造任务队列
数据存储在内存中也可以持久化到硬盘
2.1存储结构
有过脚本语言编程经验的读者对字典(或称映射、关联数组)数据结构一定很熟悉,如代码dict["key"]="value"中dict是一个字典结构变量,字符串"key"是键名,而"value"是键值,在字典中我们可以获取或设置键名对应的键值,也可以删除一个键。Redis是REmote DIctionary Server(远程字典服务器)的缩写,它以字典结构存储数据,并允许其他应用通过TCP协议读写字典中的内容。同大多数脚本语言中的字典一样,Redis字典中的键值除了可以是字符串,还可以是其他数据类型。到目前为止Redis支持的键值数据类型如下:
-
字符串类型
-
散列类型
-
列表类型
-
集合类型
-
有序集合类型
这种字典形式的存储结构与常见的MySQL 等关系数据库的二维表形式的存储结构有很大的差异。举个例子,如下所示,我们在程序中使用post变量存储了一篇文章的数据(包括标题、正文、阅读量和标签):
post["title"]="Hello World!" post["content"]="Blablabla..." post["views"]=0 post["tags"]=["Python","Django","Flask"]
现在我们希望将这篇文章的数据存储在数据库中,并且要求可以通过标签检索出文章。如果使用关系数据库存储,一般会将其中的标题、正文和阅读量存储在一个表中,而将标签存储在另一个表中,然后使用第三个表连接文章和标签表 。需要查询时还得将三个表进行连接,不是很直观。而Redis字典结构的存储方式和对多种键值数据类型的支持使得开发者可以将程序中的数据直接映射到Redis中,数据在Redis中的存储形式和其在程序中的存储方式非常相近。使用Redis的另一个优势是其对不同的数据类型提供了非常方便的操作方式,如使用集合类型存储文章标签,Redis可以对标签进行如交集、并集这样的集合运算操作。后文会专门介绍如何借助集合运算轻易地实现“找出所有同时属于A标签和B标签且不属于C标签”这样关系数据库实现起来性能不高且较为繁琐的操作。
2.2内存存储与持久化
Redis数据库中的所有数据都存储在内存中。由于内存的读写速度远快于硬盘,因此Redis在性能上对比其他基于硬盘存储的数据库有非常明显的优势,在一台普通的笔记本电脑上,Redis可以在一秒内读写超过十万个键值。
将数据存储在内存中也有问题,例如,程序退出后内存中的数据会丢失。不过 Redis提供了对持久化的支持,即将可以内存中的数据异步写入到硬盘中,同时不影响继续提供服务。
2.3功能丰富
Redis虽然是作为数据库开发的,但由于其提供了丰富的功能,越来越多的人将其用作缓存、队列系统等。Redis可谓是名副其实的多面手。
Redis可以为每个键设置生存时间(Time To Live,TTL),生存时间到期后键会自动被删除。这一功能配合出色的性能让Redis可以作为缓存系统来使用,而且由于Redis支持持久化和丰富的数据类型,使其成为了另一个非常流行的缓存系统Memcached的有力竞争者。
讨论 关于Redis和Memcached优劣的讨论一直是一个热门的话题。在性能上Redis是单线程模型,而Memcached支持多线程,所以在多核服务器上后者的性能更高一些。然而,前面已经介绍过,Redis的性能已经足够优异,在绝大部分场合下其性能都不会成为瓶颈。所以在使用时更应该关心的是二者在功能上的区别,如果需要用到高级的数据类型或是持久化等功能,Redis将会是Memcached很好的替代品。
作为缓存系统,Redis还可以限定数据占用的最大内存空间,在数据达到空间限制后可以按照一定的规则自动淘汰不需要的键。
除此之外,Redis的列表类型键可以用来实现队列,并且支持阻塞式读取,可以很容易地实现一个高性能的优先级队列。同时在更高层面上,Redis还支持“发布/订阅”的消息模式,可以基于此构建聊天室等系统。
2.4简单稳定
即使功能再丰富,如果使用起来太复杂也很难吸引人。Redis直观的存储结构使得通过程序与Redis交互十分简单。在Redis中使用命令来读写数据,命令语句之于Redis就相当于SQL语言之于关系数据库。例如在关系数据库中要获取posts表内id为1的记录的title字段的值可以使用如下SQL语句实现:
SELECT title FROM posts WHERE id=1 LIMIT 1
相对应的,在Redis中要读取键名为post:1的散列类型键的title字段的值,可以使用如下命令语句实现:
HGET post:1 title
其中HGET就是一个命令。Redis提供了一百多个命令,听起来很多,但是常用的却只有十几个,并且每个命令都很容易记忆。读完第3章你就会发现Redis的命令比SQL语言要简单很多。
Redis提供了几十种不同编程语言的客户端库,这些库都很好地封装了Redis的命令,使得在程序中与Redis进行交互变得更容易。有些库还提供了可以将编程语言中的数据类型直接以相应的形式存储到Redis中(如将数组直接以列表类型存入Redis)的简单方法,使用起来非常方便。
读者可以在http://redis.io/commands上查看到所有的redis命令和使用方法
Redis使用C语言开发,代码量只有3万多行。这降低了用户通过修改Redis源代码来使之更适合自己项目需要的门槛。对于希望“榨干”数据库性能的开发者而言,这无疑是一个很大的吸引力。
Redis 是开源的,所以事实上Redis的开发者并不止Salvatore Sanfilippo和Pieter Noordhuis。截至目前,有将近100名开发者为Redis贡献了代码。良好的开发氛围和严谨的版本发布机制使得Redis的稳定版本非常可靠,如此多的公司在项目中使用了Redis也可以印证这一点。
小结
本章是redis简介,有如下核心知识点
- 了解redis存储结构
- 了解redis特性
- Redis安装
学习Redis最好的办法就是动手尝试它。在介绍Redis最核心的内容之前,本章先来介绍一下如何安装和运行Redis,以及Redis的基础知识,使读者可以在之后的章节中一边学习一边实践。
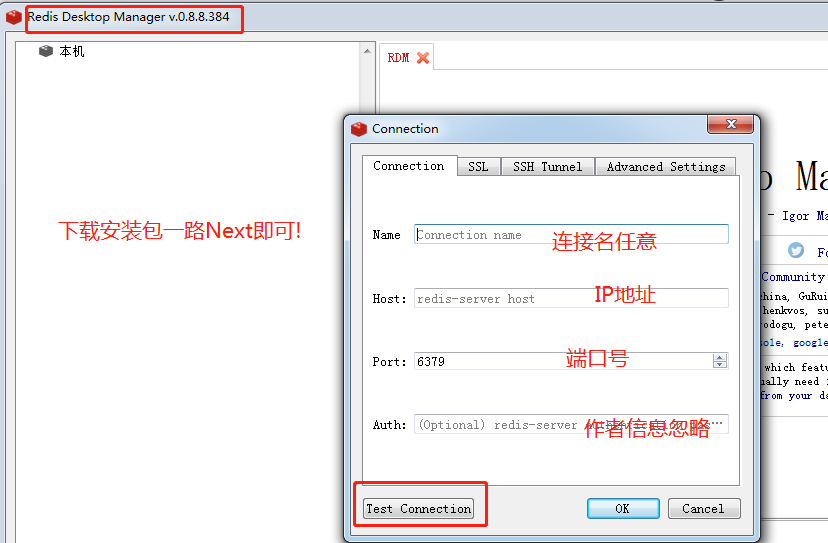
window安装Redis
安装Redis是开始Redis学习之旅的第一步。在安装Redis前需要了解Redis的版本规则以选择最适合自己的版本,Redis约定次版本号(即第一个小数点后的数字)为偶数的版本是稳定版(如2.4版、2.6版),奇数版本是非稳定版(如2.5版、2.7版),推荐使用稳定版本进行开发和在生产环境使用。
-
下载
-
window安装
(网盘链接:https://pan.baidu.com/s/1ymxRgUX_mja_fmvqeBH3GA 提取码:love
-
Centos安装
-
安装
-
直接解压即可
img
- 双击打开redis-server.exe启动服务端
- 双击打开redis-cli.exe启动客户端工具
-
文件说明
image-20201215165832969 -
redis-benchmark.exe 测redis性能的程序,可以同时模拟N多客户端查询和赋值
-
redis-check-aof.exe 更新日志检查–修复日志
-
redis-check-dump.exe 本地数据库检查
-
redis.conf redis配置文件redis-cli.exe 客户端连接 redis服务器工具
-
redis-server.exe redis服务器启动程序
-
可把redis添加为系统服务,设置为开机启动步骤如下
-
打开cmd指令窗口
-
输入你刚才解压的文件路径
-
然后输入redis-server redis.windows.conf 命令
img
接下来部署Redis为windows下的服务 首先关掉上一个窗口再打开一个新的cmd命令窗口
然后输入指令redis-server --service-install redis.windows.conf
随后,进入右击此电脑–管理–服务和应用程序–服务 启动服务
img
Redis常用的指令 卸载服务:redis-server --service-uninstall 开启服务:redis-server --service-start 停止服务:redis-server --service-stop 测试redis,通过cd到我们解压的目录,输入指令通过Set get指令查看是否成功
image-20201215164430963
图形客户端
百度链接:https://pan.baidu.com/s/10LQ9tvj8bIUECe4E3f4xpw 提取码:love
Linux安装
redis源码 http://download.redis.io/redis-stable.tar.gz下载。
下载安装包后解压即可使用make 命令完成编译,完整的命令如下:
1.升级GCC
Linux一般默认GCC版本是4.8.5,Redis新版本使用了更高版本的GC
`$ gcc -v # 查看gcc版本
$ yum -y install centos-release-scl # 升级到9.1版本
$ yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
$ scl enable devtoolset-9 bash
以上为临时启用,如果要长期使用gcc 9.1的话:
$ echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile`
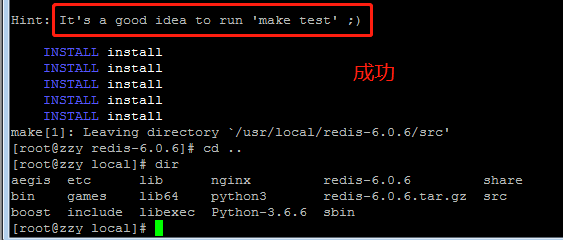
2.源码安装
`wget http://download.redis.io/redis-stable.tar.gz
tar xzf redis-stable.tar.gz
cd redis-stable
make
make install # 默认会安装到/usr/local/bin 目录下
make && make PREFIX=/usr/local/redis install #(不想安装到认目录,可用 PREFIX 指定了安装目录)`
redis安装在/usr/local/bin/目录

# redis可执行文件(因为配置了redis的环境变量,redis/bin中的所有命令都可被识别) redis-server #Redis服务器 redis-cli #Redis命令行客户端 redis-benchmark #Redis性能测试工具 redis-check-aof #AOF文件修复工具 redis-check-dump #RDB文件检测工具 redis-sentinel #Sentinel 服务器
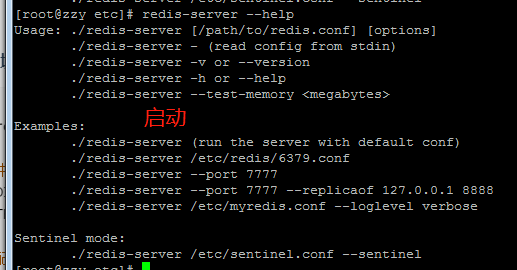
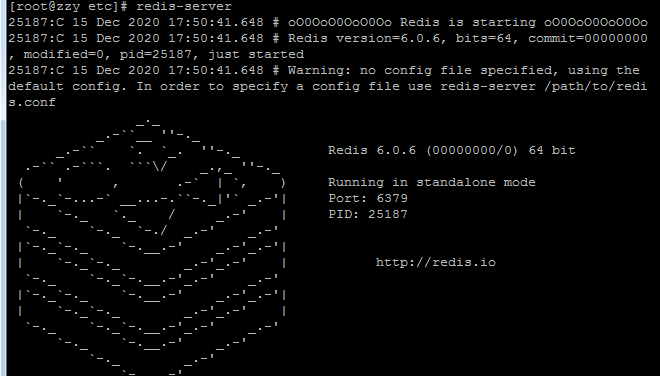
3.启动
#三种启动方式 cd /usr/local/bin ./redis-server 默认端口6379 ./redis-server --port 端口号 ./redis-server /path/to/redis.conf 启动时的配置文件将覆盖系统同名配置项
4.更改配置
复制安装目录中的redis.conf作为配置文件,将其拷贝到/usr/local/etc目录,以后运行redis服务,就指定该配置文件。
`mkdir -p /usr/local/etc # 创建配置文件夹
cd /usr/local/redis-stable
cp redis.conf /usr/local/etc/ #拷贝
更改配置
cd /usr/local/etc/
vi redis.conf
开启守护进程(表明reids启动后在后台运行)
daemonize yes
启动
cd /usr/local/bin
./redis-server /usr/local/etc/redis.conf # 后台启动`
5.配置redis环境变量
`# 编辑 /etc/profile
vi /etc/profile
在配置文件中添加环境变量
export REDIS_HOME=/usr/local # redis安装目录
export PATH=$PATH:$REDIS_HOME/bin
重新编译配置文件
. /etc/profile
现在可以直接识别redis指令了
redis-server /usr/local/etc/redis.conf # 启动
redis-cli # 连接
redis-cli shutdown # 关闭`
- 常见命令
`# 检查服务是否正常启动
ps -ef | grep redis
ping命令检查连接是否正常,正常就会收到PONG
redis-cli ping
正常关闭服务
redis-cli shutdown
手启服务时指定配置文件,(前面默认配置在/usr/local/etc/redis.conf)
redis-server /usr/local/etc/redis.conf
通过-h和-p参数指定IP和端口信息
redis-cli -h 127.0.0.1 -p 6380`
8.redis中指令
`redis 127.0.0.1:6379> info #查看server版本内存使用连接等信息
redis 127.0.0.1:6379> client list #获取客户连接列表
redis 127.0.0.1:6379> client kill 127.0.0.1:33441 #终止某个客户端连接
redis 127.0.0.1:6379> dbsize #当前保存key的数量
redis 127.0.0.1:6379> save #立即保存数据到硬盘
redis 127.0.0.1:6379> bgsave #异步保存数据到硬盘
redis 127.0.0.1:6379> flushdb #当前库中移除所有key
redis 127.0.0.1:6379> flushall #移除所有key从所有库中
redis 127.0.0.1:6379> lastsave #获取上次成功保存到硬盘的unix时间戳
redis 127.0.0.1:6379> monitor #实时监测服务器接收到的请求
redis 127.0.0.1:6379> slowlog len #查询慢查询日志条数
(integer) 3
redis 127.0.0.1:6379> slowlog get #返回所有的慢查询日志,最大值取决于slowlog-max-len配置
redis 127.0.0.1:6379> slowlog get 2 #打印两条慢查询日志
redis 127.0.0.1:6379> slowlog reset #清空慢查询日志信息`
注意:不能强制关闭redis服务器,会丢失数据,正常关闭指令是shutdow
参考文档:
http://blog.csdn.net/love__coder/article/details/8271832
常用配置
以上redis的配置文件在/usr/local/etc/redis.conf中
`# 1. 端口号 默认为6379
prot 6379
bind 127.0.0.1 # 绑定IP地址,只允许来自指定网卡的Redis请求,如果想允许任意地址访问将 bind 注释掉就行
设置Redis连接密码,默认无,如果配置了连接密码,客户端在连接Redis时需要通过【AUTH 】命令提供密码
requirepass 123456
设置最大客户端连接数。 默认为10000,最大值为当前'file limit - 32'
如果连接数用完了,新客户端连接时会报 'max number of clients reached'
maxclients 10000
指定Redis最大内存限制, Redis在启动时会把数据加载到内存中,
达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,
当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。
maxmemory
在内存达到上限后的处理策略
1. volatile-lru -> 回收 最久 没有使用的键(近似 LRU),但仅限于在过期集合的键。
2. allkeys-lru -> 所有键中回收 最久 使用的键(近似 LRU)。
3. volatile-lfu -> 回收使用 频率最少 的键(近似 LFU),但仅限于在过期集合的键。
4. allkeys-lfu -> 所有键中回收使用 频率最少 的键(近似 LFU)。
5. volatile-random -> 回收 随机 的键,但仅限于在过期集合的键。
6. allkeys-random -> 所有键中回收 随机 的键。
7. volatile-ttl ->回收在过期集合的键,并且 优先回收存活时间(TTL)较短 的键。
8. noeviction -> 直接返回错误,当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)。
默认是没有开启AOF(append only file)方式持久化,可以通过appendonly参数启用
appendonly true
目录和RDB文件目录一样,默认文件名是appendonly.aof,可通过append filename参数修改:
appendfilename "appendonly.aof"
由于操作系统的缓存机制,数据并没有立即写入硬盘,而是进入了硬盘的缓存,默认系统每30秒会执行一次同步操作,以将缓存中的数据真正地写入硬盘,在这30的过程中如果异常退出则会导制硬盘缓存中的数据丢失,设置同步的时机:
appendfsync always #每次修改同步一次
appendfsync everysec #每秒同步一次
appendfsync no #no表示交同操作系统来做即30秒一次。
设置AOF文件的重写
BGREWRITEAOF命令手动执行AOF重写
当目前的AOF文件大小超过上一次重写时的大少的百分之多少时会进行重写,如果之前没有重写,则以启动进的大小为依据
auto-aof-rewrite-percentage 100
限制允许重写的最小AOF文件大小
auto-oaf-rewrite-min-size 60mb
aof-load-truncated的默认值为 yes。当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。
如果是no,用户必须手动redis-check-aof修复AOF文件才可以重启Redis服务器。
aof-load-truncated yes
对于 persistence 持久化存储,Redis 有两种持久化方案,RDB(Redis DataBase)和 AOF(Append-Only File)。其中RDB是一份内存快照,AOF则为可回放的命令日志,他们各有特点也相互独立。4.0开始允许使用RDB-AOF混合持久化的方式,结合了两者的优点,通过 aof-use-rdb-preamble 配置项可以打开混合开关。
表示是否开启混合存储,默认是开启的。
开启后Redis保证RDB转储跟AOF重写不会同时进行。
当Redis启动时,即便RDB和AOF持久化同时启用且AOF,RDB文件都存在,则Redis总是会先加载AOF文件,这是因为AOF文件被认为能够更好的保证数据一致性。
aof-use-rdb-preamble yes`
命令行设置密码(重启后失效):
redis 127.0.0.1:6379> config set requirepass 123456
密码验证:
127.0.0.1:6379> auth 123456
查询密码:
redis 127.0.0.1:6379> config get requirepass
登录有密码的Redis,在登录的时候加上密码参数
redis-cli -p 6379 -a 123456
AUTH命令跟其他redis命令一样,是没有加密的;阻止不了攻击者在网络上窃取你的密码;
小结
本章主要介绍redis如何安装
- 掌握window和linux安装步骤
- 会启动和连接redis
- Redis命令行客户端
redis-cli(Redis Command Line Interface)是Redis自带的基于命令行的Redis客户端,也是我们学习和测试Redis的重要工具,本书后面会使用它来讲解Redis各种命令的用法。
本节将会介绍如何通过redis-cli向Redis发送命令,并且对Redis命令返回值的不同类型进行简单介绍。
发送命令
通过 redis-cli向Redis发送命令有两种方式,第一种方式是将命令作为redis-cli的参数执行,比如在2.2.2节中用过的redis-cli SHUTDOWN。redis-cli执行时会自动按照默认配置(服务器地址为127.0.0.1,端口号为6379)连接Redis,通过-h和-p参数可以自定义地址和端口号:
redis-cli -h 127.0.0.1 -p 6379
Redis提供了PING命令来测试客户端与Redis的连接是否正常,如果连接正常会收到回复PONG。如:
redis-cli PING PONG
第二种方式是不附带参数运行redis-cli,这样会进入交互模式,可以自由输入命令,例如:
redis-cli redis 127.0.0.1:6379> PING PONG redis 127.0.0.1:6379> ECHO hi "hi"
这种方式在要输入多条命令时比较方便,也是本书中主要采用的方式。为了简便起见,后文中我们将用redis>表示redis 127.0.0.1:6379>。
命令返回值
命令的返回值有5种类型,对于每种类型redis-cli的展现结果都不同,下面分别说明。
1.状态回复
状态回复(status reply)是最简单的一种回复,比如向Redis发送SET命令设置某个键的值时,Redis会回复状态OK表示设置成功。另外之前演示的对PING命令的回复PONG也是状态回复。状态回复直接显示状态信息,例如:
redis>PING PONG
2.错误回复
当出现命令不存在或命令格式有错误等情况时Redis会返回错误回复(error reply)。错误回复以(error)开头,并在后面跟上错误信息。如执行一个不存在的命令:
redis>ERRORCOMMEND (error) ERR unknown command 'ERRORCOMMEND'
3.整数回复
Redis虽然没有整数类型,但是却提供了一些用于整数操作的命令,如递增键值的INCR命令会以整数形式返回递增后的键值。除此之外,一些其他命令也会返回整数,如可以获取当前数据库中键的数量的DBSIZE命令等。整数回复(integer reply)以(integer)开头,并在后面跟上整数数据:
redis>INCR foo (integer) 1
4.字符串回复
字符串回复(bulk reply)是最常见的一种回复类型,当请求一个字符串类型键的键值或一个其他类型键中的某个元素时就会得到一个字符串回复。字符串回复以双引号包裹:
redis>GET foo "1"
特殊情况是当请求的键值不存在时会得到一个空结果,显示为(nil)。如:
redis>GET noexists (nil)
5.多行字符串回复
多行字符串回复(multi-bulk reply)同样很常见,如当请求一个非字符串类型键的元素列表时就会收到多行字符串回复。多行字符串回复中的每行字符串都以一个序号开头,如:
`redis> KEYS *
- "bar"
- "foo"`
提示 KEYS命令的作用是获取数据库中符合指定规则的键名,如果你的Redis中还没有存储数据,将得到的返回值应该是(empty list or set)。
- Redis配置
一、通过配置文件设置配置项参数
前面我们通过redis-server的启动参数port设置了Redis的端口号,除此之外Redis还支持其他配置选项,如是否开启持久化、日志级别等。由于可以配置的选项较多,通过启动参数设置这些选项并不方便,所以Redis支持通过配置文件来设置这些选项。启用配置文件的方法是在启动时将配置文件的路径作为启动参数传递给redis-server,如:
redis-server /path/to/redis.conf
通过启动参数传递同名的配置选项会覆盖配置文件中相应的参数,就像这样:
redis-server /path/to/redis.conf --loglevel warning
Redis提供了一个配置文件的模板redis.conf,位于源代码目录的根目录中。如果你一步一步按照操作来进行的话,目前我们使用的是:/usr/local/etc/redis..conf。
参数说明
redis.conf 配置项说明如下:
Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
绑定的主机地址
bind 127.0.0.1
当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
设置数据库的数量,默认数据库为0,可以使用SELECT 命令在连接上指定数据库id
databases 16
指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save <seconds> <changes>
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
指定本地数据库存放目录
dir ./
设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH 命令提供密码,默认关闭
requirepass 密码
设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128
指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(折衷,默认值)
appendfsync everysec
指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
二、通过CONFIG命令动态设置/获取参数
除此之外还可以在Redis运行时通过CONFIG SET 命令在不重新启动Redis的情况下动态修改部分Redis配置。而通过CONFIG GET命令则是获取配置项的值。
查看配置项的值
语法:
CONFIG GET CONFIG_SETTING_NAME
案例
`127.0.0.1:6379> CONFIG GET loglevel
- "loglevel"
- "notice"
使用CONFIG GET *`可以获取所有的配置项
修改配置项的值
语法:
SET CONFIG_SETTING_NAME NEW_CONFIG_VALUE
案例
redis>CONFIG SET loglevel warning OK
并不是所有的配置都可以使用CONFIG SET命令修改,附录B列出了哪些配置能够使用该命令修改。同样在运行的时候也可以使用CONFIG GET命令获得Redis当前的配置情况,例如:
`redis>CONFIG GET loglevel
- "loglevel"
- "warning"`
其中第一行字符串回复表示的是选项名,第二行即是选项值。
参考文档:
http://www.runoob.com/redis/redis-conf.html
- 多数据库
Redis是一个字典结构的存储服务器,而实际上一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中。这与我们熟知的在一个关系数据库实例中可以创建多个数据库类似,所以可以将其中的每个字典都理解成一个独立的数据库。
每个数据库对外都是以一个从0开始的递增数字命名,Redis默认支持16个数据库,可以通过配置参数databases来修改这一数字。客户端与Redis建立连接后会自动选择0号数据库,不过可以随时使用SELECT命令更换数据库,如要选择1号数据库:
redis>SELECT 1 OK redis [1]>GET foo (nil)
然而这些以数字命名的数据库又与我们理解的数据库有所区别。首先Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。另外Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么连一个数据库也没有权限访问。最重要的一点是多个数据库之间并不是完全隔离,比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。综上所述,这些数据库更像是一种命名空间,而不适宜存储不同应用程序的数据。比如可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库存储B应用的数据,不同的应用应该使用不同的Redis实例存储数据。由于Redis非常轻量级,一个空Redis实例占用的内存只有1MB左右,所以不用担心多个Redis实例会额外占用很多内存。
6.命令热身
在介绍 Redis的数据类型之前,我们先来了解几个比较基础的命令作为热身,赶快打开redis-cli,跟着样例亲自输入命令来体验一下吧!。
1.获得符合规则的键名列表
KEYS pattern
pattern支持glob风格通配符格式,具体规则如表3-1所示。
使用SET命令(会在3.2节介绍)建立一个名为bar的键:
redis>SET bar 1 OK
然后使用KEYS *就能获得Redis中所有的键了(当然由于数据库中只有一个bar键,所以KEYS ba*或者KEYS bar 等命令都能获得同样的结果):
`redis> KEYS *
- "bar"`
注意 KEYS命令需要遍历Redis中的所有键,当键的数量较多时会影响性能,不建议在生产环境中使用。
提示 Redis不区分命令大小写,但在本书中均会使用大写字母表示Redis命令。
2.判断一个键是否存在
EXISTS key
如果键存在则返回整数类型1,否则返回0。如:
redis>EXISTS bar (integer) 1 redis>EXISTS noexists (integer)0
3.删除键
DEL key [key …]
可以删除一个或多个键,返回值是删除的键的个数。如:
redis>DEL bar (integer) 1 redis>DEL bar (integer) 0
第二次执行DEL命令时因为bar键已经被删除了,实际上并没有删除任何键,所以返回0。
技巧 DEL 命令的参数不支持通配符,但我们可以结合Linux 的管道和xargs 命令自己实现删除所有符合规则的键。比如要删除所有以“user:”开头的键,就可以执行redis-cli KEYS "user:" | xargs redis-cli DEL。另外由于DEL 命令支持多个键作为参数, 所以还可以执行redis-cli DEL 'redis-cli KEYS "user:"'来达到同样的效果,但是性能更好。
4.获得键值的数据类型
TYPE key
TYPET命令用来获得键值的数据类型,返回值可能是string(字符串类型)、hash(散列类型)、list(列表类型)、set(集合类型)、zset(有序集合类型)。例如:
redis>SET foo 1 OK redis>TYPE foo string redis>LPUSH bar 1 (integer) 1 redis>TYPE bar list
7. 字符串类型
作为一个爱造轮子的资深极客,小白每次看到自己博客最下面的“Powered byWordPress”都觉得有些不舒服,终于有一天他下定决心要开发一个属于自己的博客。但是用腻了MySQL数据库的小白总想尝试一下新技术,恰好上次参加Node Party时听人介绍过Redis数据库,便想着趁机试一试。可小白只知道Redis是一个键值对数据库,其他的一概不知。抱着试一试的态度,小白找到了自己大学时教计算机的宋老师,一问之下欣喜地发现宋老师竟然对Redis颇有研究。宋老师有感于小白的好学,决定给小白开个小灶。
小白:
宋老师您好,我最近听别人介绍过Redis,当时就对它很感兴趣。恰好最近想开发一个博客,准备尝试一下它。有什么能快速学会Redis的方法吗?
宋老师笑着说:
心急吃不了热豆腐,要学会Redis就要先掌握Redis的键值数据类型和相关的命令。Redis不仅支持多种数据类型,而且还为每种数据类型提供了丰富实用的命令。作为开始,我先来讲讲Redis中最基本的数据类型——字符串类型。
介绍
字符串类型是Redis中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据。你可以用其存储用户的邮箱、JSON化的对象甚至是一张图片。一个字符串类型键允许存储的数据的最大容量是512MB。
字符串类型是其他4种数据类型的基础,其他数据类型和字符串类型的差别从某种角度来说只是组织字符串的形式不同。例如,列表类型是以列表的形式组织字符串,而集合类型是以集合的形式组织字符串。学习过本章后面几节后相信读者对此会有更深的理解。
命令
1.赋值与取值
SET key value GET key
SETS和GET是Redis中最简单的两个命令,它们实现的功能和编程语言中的读写变量相似,如key="hello"在Redis中是这样表示的:
redis>SET key helloOK
想要读取键值则更简单:
redis>GET key"hello"
当键不存在时会返回空结果。
为了节约篇幅,同时避免读者过早地被编程语言的细节困扰,本书大部分章节将只使用redis-cli进行命令演示(必要的时候会配合伪代码),第5章会专门介绍在编程语言Java中使用Redis的方法。
2.递增数字
INCR key
前面说过字符串类型可以存储任何形式的字符串,当存储的字符串是整数形式时,Redis提供了一个实用的命令INCR,其作用是让当前键值递增,并返回递增后的值,用法为:
redis>INCR num(integer) 1redis>INCR num(integer) 2
当要操作的键不存在时会默认键值为0,所以第一次递增后的结果是1。当键值不是整数时Redis会提示错误:
redis>SET foo loremOKredis>INCR foo(error) ERR value is not an integer or out of range
7.3 实践
1.文章访问量统计
博客的一个常见的功能是统计文章的访问量,我们可以为每篇文章使用一个名为post:文章ID:page.view的键来记录文章的访问量,每次访问文章的时候使用INCR命令使相应的键值递增。
提示 Redis对于键的命名并没有强制的要求,但比较好的实践是用“对象类型:对象ID:对象属性”来命名一个键,如使用键user:1:friends来存储ID为1的用户的好友列表。对于多个单词则推荐使用“.”分隔,一方面是沿用以前的习惯(Redis以前版本的键名不能包含空格等特殊字符),另一方面是在redis-cli中容易输入,无需使用双引号包裹。另外为了日后维护方便,键的命名一定要有意义,如u:1:f的可读性显然不如user:1:friends好(虽然采用较短的名称可以节省存储空间,但由于键值的长度往往远远大于键名的长度,所以这部分的节省大部分情况下并不如可读性来得重要)。
2.生成自增ID
那么怎么为每篇文章生成一个唯一ID呢?在关系数据库中我们通过设置字段属性为AUTO_INCREMENT来实现每增加一条记录自动为其生成一个唯一的递增ID的目的,而在Redis中可以通过另一种模式来实现:对于每一类对象使用名为对象类型(复数形式):count①的键(如users:count)来存储当前类型对象的数量,每增加一个新对象时都使用INCR命令递增该键的值。由于使用INCR命令建立的键的初始键值是1,所以可以很容易得知,INCR命令的返回值既是加入该对象后的当前类型的对象总数,又是该新增对象的ID。 注释:这个键名只是参考命名,实际使用中可以使用任何容易理解的名称。
3.存储文章数据
由于每个字符串类型键只能存储一个字符串,而一篇博客文章是由标题、正文、作者与发布时间等多个元素构成的。为了存储这些元素,我们需要使用序列化函数(如PHP中的serialize和JavaScript中的JSON.stringify)将它们转换成一个字符串。
7.4 命令拾遗
1.增加指定的整数** **
INCRBY key increment
INCRBY命令与INCR命令基本一样,只不过前者可以通过increment参数指定一次增加的数值,如:
redis>INCRBY bar 2(integer) 2redis>INCRBY bar 3(integer) 5
2.减少指定的整数
DECR keyDECRBY key decrement
DECR命令与INCR命令用法相同,只不过是让键值递减,例如:
redis>DECR bar(integer)4
而DECRBY命令的作用不用介绍想必读者就可以猜到,DECRBY key 5 相当于INCRBY key -5。
3.增加指定浮点数
INCRBYFLOAT key increment
INCRBYFLOAT 命令类似INCRBY命令,差别是前者可以递增一个双精度浮点数,如:
redis>INCRBYFLOAT bar 2.7"6.7"redis>INCRBYFLOAT bar 5E+4"50006.69999999999999929"
4.向尾部追加值
APPEND key value
APPEND作用是向键值的末尾追加value。如果键不存在则将该键的值设置为value,即相当于SET key value。返回值是追加后字符串的总长度。例如:
redis>SET key helloOKredis>APPEND key " world!"(integer) 12
此时key的值是"hello world!"。APPEND命令的第二个参数加了双引号,原因是该参数包含空格,在redis-cli中输入需要双引号以示区分。
5.获取字符串长度
STRLEN key STRLENST命令返回键值的长度,如果键不存在则返回0。例如:
redis>STRLEN key(integer)12redis>SET key 你好OKredis>STRLEN key(integer)6
前面提到了字符串类型可以存储二进制数据,所以它可以存储任何编码的字符串。例子中Redis接收到的是使用UTF-8编码的中文,由于“你”和“好”两个字的UTF-8编码的长度都是3,所以此例中会返回6。
6.同时获得/设置多个键值
MGET key [key …]MSET key value [key value …]
MGETM/MSET与GET/SET相似,不过MGET/MSET可以同时获得/设置多个键的键值。例如:
redis>MSET key1 v1 key2 v2 key3 v3OKredis>GET key2"v2"redis>MGET key1 key31) "v1"2) "v3"
7.位操作
GETBIT key offsetSETBIT key offset valueBITCOUNT key [start] [end]BITOP operation destkey key [key …]
一个字节由8个二进制位组成,Redis提供了4个命令可以直接对二进制位进行操作。为了演示,我们首先将foo键赋值为bar:
redis>SET foo barOK
bar的3个字母对应的ASCII码分别为98、97和114,转换成二进制后分别为1100010、1100001和1110010,所以foo键中的二进制位结构如图3-3所示。
GETBIT命令可以获得一个字符串类型键指定位置的二进制位的值(0或1),索引从0开始:
redis>GETBIT foo 0(integer) 0redis>GETBIT foo 6(integer) 1
如果需要获取的二进制位的索引超出了键值的二进制位的实际长度则默认位值是0:
redis>GETBIT foo 100000(integer) 0
SETBIT 命令可以设置字符串类型键指定位置的二进制位的值,返回值是该位置的旧值。如我们要将foo键值设置为aar,可以通过位操作将foo键的二进制位的索引第6位设为0,第7位设为1:
redis>SETBIT foo 6 0(integer) 1redis>SETBIT foo 7 1(integer) 0redis>GET foo"aar"
如果要设置的位置超过了键值的二进制位的长度,SETBIT命令会自动将中间的二进制位设置为0,同理设置一个不存在的键的指定二进制位的值会自动将其前面的位赋值为0:
redis>SETBIT nofoo 10 1(integer) 0redis>GETBIT nofoo 5(integer) 0
BITCOUNTB命令可以获得字符串类型键中值是1的二进制位个数,例如:
redis>BITCOUNT foo(integer)10
可以通过参数来限制统计的字节范围,如我们只希望统计前两个字节(即"aa"):
redis>BITCOUNT foo 0 1(integer)6
BITOPB命令可以对多个字符串类型键进行位运算,并将结果存储在destkey参数指定的键中。BITOP命令支持的运算操作有AND、OR、XOR 和NOT。如我们可以对bar和aar进行OR运算:
redis>SET foo1 barOKredis>SET foo2 aarOKredis>BITOP OR res foo1 foo2(integer) 3redis>GET res"car"
运算过程如图3-4所示。
利用位操作命令可以非常紧凑地存储布尔值。比如某网站的每个用户都有一个递增的整数ID,如果使用一个字符串类型键配合位操作来记录每个用户的性别(用户ID作为索引,二进制位值1和0表示男性和女性),那么记录100万个用户的性别只需占用100 KB多的空间,而且由于GETBIT和SETBIT的时间复杂度都是0(1),所以读取二进制位值性能很高。
- 散列类型
小白只用了半个多小时就把访问统计和发表文章两个部分做好了。同时借助Bootstrap框架,老师花了一小会儿时间教会了之前只涉猎过HTML的小白如何做出一个像样的网页界面。
接着小白发问: 接下来我想要做的功能是博客的文章列表页,我设想在列表页中每个文章只显示标题部分,可是使用您刚才介绍的方法,若想取得文章的标题,必须把整个文章数据字符串取出来反序列化,而其中占用空间最大的文章內容部分却是不需要的,这样难道不会在传输和处理时造成资源浪费吗? 老师有些惊喜地看着小白答道:“很对!”同时以一个夸张的幅度点了下头,接着说: 这正是我接下来准备讲的。不仅取数据时会有资源浪费,在修改数据时也会有这个问题,比如当你只想更改文章的标题时也不得不把整个文章数据字符串更新一遍。 没等小白再问,老师就又继续说道: 前面我说过Redis的强大特性之一就是提供了多种实用的数据类型,其中的散列类型可以非常好地解决这个问题。
8.1 介绍
我们现在已经知道Redis是采用字典结构以键值对的形式存储数据的,而散列类型(hash)的键值也是一种字典结构,其存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他数据类型,换句话说,散列类型不能嵌套其他的数据类型。一个散列类型键可以包含至多232-1个字段。
提示 除了散列类型,Redis的其他数据类型同样不支持数据类型嵌套。比如集合类型的每个元素都只能是字符串,不能是另一个集合或散列表等。
散列类型适合存储对象:使用对象类别和ID构成键名,使用字段表示对象的属性,而字段值则存储属性值。例如要存储ID为2的汽车对象,可以分别使用名为color、name和price的3个字段来存储该辆汽车的颜色、名称和价格。存储结构如图3-5所示。

回想在关系数据库中如果要存储汽车对象,存储结构如表3-2所示。

数据是以二维表的形式存储的,这就要求所有的记录都拥有同样的属性,无法单独为某条记录增减属性。如果想为ID为1的汽车增加生产日期属性,就需要把数据表更改为如表3-3所示的结构。

对于ID为2和3的两条记录而言date字段是冗余的。可想而知当不同的记录需要不同的属性时,表的字段数量会越来越多以至于难以维护。
而Redis的散列类型则不存在这个问题。虽然我们在图3-5中描述了汽车对象的存储结构,但是这个结构只是人为的约定,Redis并不要求每个键都依据此结构存储,我们完全可以自由地为任何键增减字段而不影响其他键。
8.2 命令
1.赋值与取值
HSET key field valueHGET key fieldHMSET key field value [field value …]HMGET key field [field …]HGETALL key
HSET命令用来给字段赋值,而HGET命令用来获得字段的值。用法如下:
redis>HSET car price 500(integer) 1redis>HSET car name BMW(integer) 1redis>HGET car name"BMW"
HSET命令的方便之处在于不区分插入和更新操作,这意味着修改数据时不用事先判断字段是否存在来决定要执行的是插入操作(update)还是更新操作(insert)。当执行的是插入操作时(即之前字段不存在)HSET命令会返回1,当执行的是更新操作时(即之前字段已经存在)HSET命令会返回0。更进一步,当键本身不存在时,HSET命令还会自动建立它。
提示 在Redis中每个键都属于一个明确的数据类型,如通过HSET命令建立的键是散列类型,通过SET命令建立的键是字符串类型等。使用一种数据类型的命令操作另一种数据类型的键会提示错误:“ERR Operation against a key holding the wrong kind of value”。
注释:并不是所有命令都是如此,比如SET命令可以覆盖已经存在的键而不论原来键是什么类型。
当需要同时设置多个字段的值时,可以使用HMSET命令。例如,下面两条语句
HSET key field1 value1HSET key field2 value2
可以用HMSET命令改写成
HMSET key field1 value1 field2 value2
相应地,HMGET命令可以同时获得多个字段的值:
redis>HMGET car price name1) "500"2) "BMW"
如果想获取键中所有字段和字段值却不知道键中有哪些字段时(如8.1节介绍的存储汽车对象的例子,每个对象拥有的属性都未必相同)应该使用HGETALL命令。如:
redis>HGETALL car1) "price"2) "500"3) "name"4) "BMW"
返回的结果是字段和字段值组成的列表,不是很直观,好在很多语言的Redis客户端会将HGETALL的返回结果封装成编程语言中的对象,处理起来就非常方便了。
2.判断字段是否存在
HEXISTS key field
HEXISTS命令用来判断一个字段是否存在。如果存在则返回1,否则返回0(如果键不存在也会返回0)。
redis>HEXISTS car model(integer) 0redis>HSET car model C200(integer) 1redis>HEXISTS car model(integer) 1
3.当字段不存在时赋值
HSETNX key field value
HSETNXH 命令与HSET命令类似,区别在于如果字段已经存在,HSETNX命令将不执行任何操作。其实现可以表示为如下伪代码: 注释:HSETNX 中的“NX”表示“if Not eXists”(如果不存在)。
def hsetnx( key, field, value)isExists=HEXISTS key, fieldif isExists is 0HSET key, field, valuereturn 1elsereturn 0
只不过HSETNX命令是原子操作,不用担心竞态条件。
4.增加数字
HINCRBY key field increment
上一节的命令拾遗部分介绍了字符串类型的命令INCRBY,HINCRBY命令与之类似,可以使字段值增加指定的整数。散列类型没有HINCR命令,但是可以通过HINCRBY key field 1来实现。
HINCRBY命令的示例如下:
redis>HINCRBY person score 60(integer) 60
之前person键不存在,HINCRBY命令会自动建立该键并默认score字段在执行命令前的值为“0”。命令的返回值是增值后的字段值。
5.删除字段
HDEL key field [field …]
HDEL命令可以删除一个或多个字段,返回值是被删除的字段个数:
redis>HDEL car price(integer) 1redis>HDEL car price(integer) 0
8.3 实践
1.存储文章数据
3.2.3节介绍了可以将文章对象序列化后使用一个字符串类型键存储,可是这种方法无法提供对单个字段的原子读写操作支持,从而产生竞态条件,如两个客户端同时获得并反序列化某个文章的数据,然后分别修改不同的属性后存入,显然后存入的数据会覆盖之前的数据,最后只会有一个属性被修改。另外如小白所说,即使只需要文章标题,程序也不得不将包括文章内容在内的所有文章数据取出并反序列化,比较消耗资源。除此之外,还有一种方法是组合使用多个字符串类型键来存储一篇文章的数据,如图3-6所示。

使用这种方法的好处在于无论获取还是修改文章数据,都可以只对某一属性进行操作,十分方便。而本章介绍的散列类型则更适合此场景,使用散列类型的存储结构如图3-7所示。

从图3-7可以看出使用散列类型存储文章数据比图3-6所示的方法看起来更加直观也更容易维护(比如可以使用HGETALL命令获得一个对象的所有字段,删除一个对象时只需要删除一个键),另外存储同样的数据散列类型往往比字符串类型更加节约空间,具体的细节会在4.6节中介绍。
2.存储文章缩略名
使用过WordPress的读者可能会知道发布文章时一般需要指定一个缩略名(slug)来构成该篇文章的网址的一部分,缩略名必须符合网址规范且最好可以与文章标题含义相似,如“This Is A Great Post!”的缩略名可以为“this-is-a-great-post”。每个文章的缩略名必须是唯一的,所以在发布文章时程序需要验证用户输入的缩略名是否存在,同时也需要通过缩略名获得文章的ID。
我们可以使用一个散列类型的键slug.to.id来存储文章缩略名和ID之间的映射关系。其中字段用来记录缩略名,字段值用来记录缩略名对应的ID。这样就可以使用HEXISTS命令来判断缩略名是否存在,使用HGET命令来获得缩略名对应的文章ID了。
8.4 命令拾遗
1.只获取字段名或字段值
HKEYS key
HVALS key
有时仅仅需要获取键中所有字段的名字而不需要字段值,那么可以使用HKEYS命令,就像这样:
redis>HKEYS car1) "name"2) "model"
HVALS命令与HKEYS命令相对应,HVALS命令用来获得键中所有字段值,例如:
redis>HVALS car1) "BMW"2) "C200"
2.获得字段数量
HLEN key
例如:
redis>HLEN car(integer) 2
9.列表类型
9.1 介绍
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
列表类型内部是使用双向链表(double linked list)实现的,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的(和从只有20个元素的列表中获取头部或尾部的10条记录的速度是一样的)。
不过使用链表的代价是通过索引访问元素比较慢,设想在iPad mini发售当天有1000个人在三里屯的苹果店排队等候购买,这时苹果公司宣布为了感谢大家的排队支持,决定奖励排在第486位的顾客一部免费的iPad mini。为了找到这第486位顾客,工作人员不得不从队首一个一个地数到第486个人。但同时,无论队伍多长,新来的人想加入队伍的话直接排到队尾就好了,和队伍里有多少人没有任何关系。这种情景与列表类型的特性很相似。
这种特性使列表类型能非常快速地完成关系数据库难以应付的场景:如社交网站的新鲜事,我们关心的只是最新的内容,使用列表类型存储,即使新鲜事的总数达到几千万个,获取其中最新的100条数据也是极快的。同样因为在两端插入记录的时间复杂度是0(1),列表类型也适合用来记录日志,可以保证加入新日志的速度不会受到已有日志数量的影响。
借助列表类型,Redis还可以作为队列使用,4.4节会详细介绍。
与散列类型键最多能容纳的字段数量相同,一个列表类型键最多能容纳232-1个元素。
9.2 命令
1.向列表两端增加元素
LPUSH key value [value …] RPUSH key value [value …]
LPUSH命令用来向列表左边增加元素,返回值表示增加元素后列表的长度。
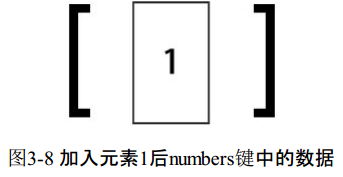
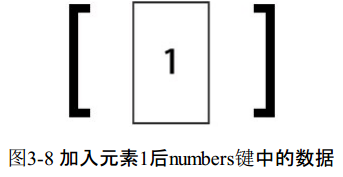
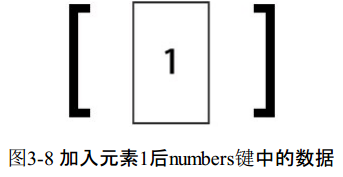
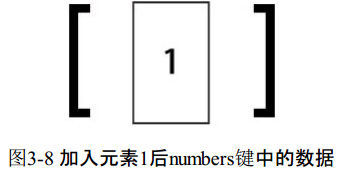
redis>LPUSH numbers 1(integer) 1
这时numbers键中的数据如图3-8所示。LPUSH命令还支持同时增加多个元素,例如:
redis>LPUSH numbers 2 3(integer) 3
LPUSH会先向列表左边加入"2",然后再加入"3",所以此时numbers键中的数据如图3-9所示。
向列表右边增加元素的话则使用RPUSH命令,其用法和LPUSH命令一样:
redis>RPUSH numbers 0 -1(integer) 5
此时numbers 键中的数据如图3-10所示。
2.从列表两端弹出元素
LPOP key RPOP key
有进有出,LPOP命令可以从列表左边弹出一个元素。LPOP命令执行两步操作:第一步是将列表左边的元素从列表中移除,第二步是返回被移除的元素值。例如,从numbers列表左边弹出一个元素(也就是"3"):
redis>LPOP numbers"3"
此时numbers键中的数据如图3-11所示。
同样,RPOP命令可以从列表右边弹出一个元素:
redis>RPOP numbers"-1"
此时numbers键中的数据如图3-12所示。
QQ截图20160317165743.png
结合上面提到的4个命令可以使用列表类型来模拟栈和队列的操作:如果想把列表当做栈,则搭配使用LPUSH和LPOP或RPUSH和RPOP,如果想当成队列,则搭配使用LPUSH和RPOP或RPUSH和LPOP。
3.获取列表中元素的个数
LLEN key
当键不存在时LLEN会返回0:
redis>LLEN numbers(integer) 3
LLEN命令的功能类似SQL语句SELECT COUNT(*) FROM table_name,但是LLEN的时间复杂度为0(1),使用时Redis会直接读取现成的值,而不需要像部分关系数据库(如使用InnoDB存储引擎的MySQL 表)那样需要遍历一遍数据表来统计条目数量。
4.获得列表片段
LRANGE key start stop
LRANGE命令是列表类型最常用的命令之一,它能够获得列表中的某一片段。LRANGE命令将返回索引从start到stop之间的所有元素(包含两端的元素)。与大多数人的直觉相同,Redis的列表起始索引为0:
redis>LRANGE numbers 0 21) "2"2) "1"3) "0"
LRANGE命令在取得列表片段的同时不会像LPOP一样删除该片段,另外LRANGE命令与很多语言中用来截取数组片段的方法slice有一点区别是LRANGE返回的值包含最右边的元素,如在JavaScript中:
var numbers=[2, 1, 0];console.log(numbers.slice(0, 2)); //返回数组:[2, 1]
LRANGE命令也支持负索引,表示从右边开始计算序数,如"-1"表示最右边第一个元素,"-2"表示最右边第二个元素,依次类推:
redis>LRANGE numbers -2 -11) "1"2) "0"
显然,LRANGE numbers 0 -1可以获取列表中的所有元素。另外一些特殊情况如下。
(1)如果start的索引位置比stop的索引位置靠后,则会返回空列表。
(2)如果stop大于实际的索引范围,则会返回到列表最右边的元素:
redis>LRANGE numbers 1 9991) "1"2) "0"
5.删除列表中指定的值
LREM key count value
LREM命令会删除列表中前count个值为value的元素,返回值是实际删除的元素个数。根据count值的不同,LREM命令的执行方式会略有差异:
●当count>0时LREM命令会从列表左边开始删除前count个值为value的元素;
●当count<0时LREM 命令会从列表右边开始删除前|count|个值为value的元素;
●当count=0是LREM命令会删除所有值为value的元素。例如:
redis>RPUSH numbers 2(integer) 4redis>LRANGE numbers 0 -11) "2"2) "1"3) "0"4) "2"
从右边开始删除第一个值为"2"的元素
``redis>LREM numbers -1 2(integer) 1redis>LRANGE numbers 0 -11) "2"2) "1"3) "0"`
9.3 命令拾遗
1.获得/设置指定索引的元素值
LINDEX key index
LSET key index value
如果要将列表类型当作数组来用,LINDEX命令是必不可少的。LINDEX命令用来返回指定索引的元素,索引从0开始。如:
redis>LINDEX numbers 0"2"
如果index是负数则表示从右边开始计算的索引,最右边元素的索引是-1。例如:
redis>LINDEX numbers -1"0"
LSET是另一个通过索引操作列表的命令,它会将索引为index的元素赋值为value。例如:
redis>LSET numbers 1 7OKredis>LINDEX numbers 1"7"
2.只保留列表指定片段
LTRIM key start end
LTRIM命令可以删除指定索引范围之外的所有元素,其指定列表范围的方法和LRANGE命令相同。就像这样:
redis>LRANGE numbers 0 11) "1"2) "2"3) "7"4) "3""0"redis>LTRIM numbers 1 2OKredis>LRANGE numbers 0 11) "2"2) "7"
LTRIM命令常和LPUSH命令一起使用来限制列表中元素的数量,比如记录日志时我们希望只保留最近的100条日志,则每次加入新元素时调用一次LTRIM命令即可:
LPUSH logs newLogLTRIM logs 0 99
3.向列表中插入元素
LINSERT key BEFORE|AFTER pivot value
LINSERT命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是BEFORE还是AFTER来决定将value插入到该元素的前面还是后面。
LINSERT命令的返回值是插入后列表的元素个数。示例如下:
redis>LRANGE numbers 0 -11) "2"2) "7"3) "0"redis>LINSERT numbers AFTER 7 3(integer) 4redis>LRANGE numbers 0 -11) "2"2) "7"3) "3"4) "0"redis>LINSERT numbers BEFORE 2 1(integer) 5redis>LRANGE numbers 0 -11) "1"2) "2"3) "7"4) "3"5) "0"
4.将元素从一个列表转到另一个列表R
POPLPUSH source destination
RPOPLPUSH是个很有意思的命令,从名字就可以看出它的功能:先执行RPOP命令再执行LPUSH 命令。RPOPLPUSH命令会先从source列表类型键的右边弹出一个元素,然后将其加入到destination列表类型键的左边,并返回这个元素的值,整个过程是原子的。其具体实现可以表示为伪代码:
def rpoplpush( source, destination)value=RPOP sourceLPUSH destination, valuereturn value
当把列表类型作为队列使用时,RPOPLPUSH命令可以很直观地在多个队列中传递数据。当source和destination相同时,RPOPLPUSH命令会不断地将队尾的元素移到队首,借助这个特性我们可以实现一个网站监控系统:使用一个队列存储需要监控的网址,然后监控程序不断地使用RPOPLPUSH命令循环取出一个网址来测试可用性。这里使用RPOPLPUSH命令的好处在于在程序执行过程中仍然可以不断地向网址列表中加入新网址,而且整个系统容易扩展,允许多个客户端同时处理队列。
10集合类型
10.1 介绍
集合的概念高中的数学课就学习过。在集合中的每个元素都是不同的,且没有顺序。一个集合类型(set)键可以存储至多232-1个(相信这个数字对大家来说已经很熟悉了)字符串。集合类型和列表类型有相似之处,但很容易将它们区分开来,如表3-4所示。
集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,由于集合类型在Redis内部是使用值为空的散列表(hash table)实现的,所以这些操作的时间复杂度都是0(1)。最方便的是多个集合类型键之间还可以进行并集、交集和差集运算,稍后就会看到灵活
运用这一特性带来的便利。
10.2 命令
1.增加/删除元素
SADD key member [member …] SREM key member [member …]
SADD命令用来向集合中增加一个或多个元素,如果键不存在则会自动创建。因为在一个集合中不能有相同的元素,所以如果要加入的元素已经存在于集合中就会忽略这个元素。本命令的返回值是成功加入的元素数量(忽略的元素不计算在内)。例如:
redis>SADD letters a(integer) 1redis> SADD letters a b c(integer) 2
第二条SADD命令的返回值为2是因为元素“a”已经存在,所以实际上只加入了两个元素。
SREM命令用来从集合中删除一个或多个元素,并返回删除成功的个数,例如:
redis>SREM letters c d(integer) 1
由于元素“d”在集合中不存在,所以只删除了一个元素,返回值为1。
2.获得集合中的所有元素
SMEMBERS key
SMEMBERS命令会返回集合中的所有元素,例如:
redis>SMEMBERS letters1) "b"2) "a"
3.判断元素是否在集合中
SISMEMBER key member
判断一个元素是否在集合中是一个时间复杂度为0(1)的操作,无论集合中有多少个元素,SISMEMBER命令始终可以极快地返回结果。当值存在时SISMEMBER命令返回1,当值不存在或键不存在时返回0,例如:
redis>SISMEMBER letters a(integer) 1redis>SISMEMBER letters d(integer) 0
4.集合间运算
SDIFF key [key …] SINTER key [key …] SUNION key [key …]
接下来要介绍的3个命令都是用来进行多个集合间运算的。
(1)SDIFF命令用来对多个集合执行差集运算。集合A与集合B的差集表示为A-B,代表所有属于A且不属于B的元素构成的集合(如图3-13所示),即A-B={x|x∈A且x∈/B}。例如:
{1, 2, 3}-{2, 3, 4}={1} {2, 3, 4}-{1, 2, 3}={4}
SDIFF命令的使用方法如下:
redis>SADD setA 1 2 3(integer) 3redis>SADD setB 2 3 4(integer) 3redis>SDIFF setA setB1) "1"redis>SDIFF setB setA1 ) "4"
SDIFF 命令支持同时传入多个键,例如:
redis>SADD setC 2 3(integer) 2redis>SDIFF setA setB setC1 ) "1"
计算顺序是先计算setA-setB,再计算结果与setC的差集。
(2)SINTER命令用来对多个集合执行交集运算。集合A与集合B的交集表示为A∩B,代表所有属于A且属于B的元素构成的集合(如图3-14所示),即A∩B={x|x∈A且x∈B}。例如:
{1, 2, 3}∩{2, 3, 4}={2, 3}
SINTER命令的使用方法如下:
redis>SINTER setA setB1) "2"2) "3"
SINTER命令同样支持同时传入多个键,如:
redis>SINTER setA setB setC1) "2"2) "3"
(3)SUNION命令用来对多个集合执行并集运算。集合A与集合B的并集表示为AUB,代表所有属于A或属于B的元素构成的集合(如图3-15所示),即AUB={x|x∈A 或x∈B}。例如:
{1, 2, 3}∪{2, 3, 4}={1, 2, 3, 4} SUNION命令的使用方法如下:
redis>SUNION setA setB1) "1"2) "2"3) "3"4) "4"
SUNION命令同样支持同时传入多个键,例如:
redis>SUNION setA setB setC1) "1"2) "2"3) "3"4) "4"
10.3 命令拾遗
1.获得集合中元素个数 SCARD key SCARD命令用来获得集合中的元素个数,例如:
redis>SMEMBERS letters1) "b"2) "a"redis>SCARD letters(integer) 2
2.进行集合运算并将结果存储
SDIFFSTORE destination key [key …] SINTERSTORE destination key [key …] SUNIONSTORE destination key [key …]
SDIFFSTORE命令和SDIFF命令功能一样,唯一的区别就是前者不会直接返回运算结果,而是将结果存储在destination键中。
SDIFFSTORE命令常用于需要进行多步集合运算的场景中,如需要先计算差集再将结果和其他键计算交集。
SINTERSTORE和SUNIONSTORE命令与之类似,不再赘述。
3.随机获得集合中的元素 SRANDMEMBER key [count] SRANDMEMBER命令用来随机从集合中获取一个元素,如:
redis>SRANDMEMBER letters"a"redis>SRANDMEMBER letters"b"redis>SRANDMEMBER letters"a"
还可以传递count参数来一次随机获得多个元素,根据count的正负不同,具体表现也不同。 (1)当count为正数时,SRANDMEMBER会随机从集合里获得count个不重复的元素。如果count的值大于集合中的元素个数,则SRANDMEMBER会返回集合中的全部元素。 (2)当count为负数时,SRANDMEMBER会随机从集合里获得|count|个的元素,这些元素有可能相同。
为了示例,我们先在letters集合中加入两个元素:
redis>SADD letters c d(integer) 2
目前letters集合中共有“a”、“b”、“c”、“d”4个元素,下面使用不同的参数对SRANDMEMBER命令进行测试:
redis>SRANDMEMBER letters 21) "a"2) "c"redis>SRANDMEMBER letters 21) "a"2) "b"redis>SRANDMEMBER letters 1001) "b"2) "a"3) "c"4) "d"redis>SRANDMEMBER letters -21) "b"2) "b"redis>SRANDMEMBER letters -101) "b"2) "b"3) "c"4) "c"5) "b"6) "a"7) "b"8) "d"9) "b"10) "b"
细心的读者可能会发现SRANDMEMBER命令返回的数据似乎并不是非常的随机,从SRANDMEMBER letters -10这个结果中可以很明显地看出这个问题(b元素出现的次数相对较多① ),出现这种情况是由集合类型采用的存储结构(散列表)造成的。散列表使用散列函数将元素映射到不同的存储位置(桶)上以实现0(1)时间复杂度的元素查找,举个例子,当使用散列表存储元素b时,使用散列函数计算出b的散列值是0,所以将b存入编号为0 的桶(bucket)中,下次要查找b时就可以用同样的散列函数再次计算b的散列值并直接到相应的桶中找到b。当两个不同的元素的散列值相同时会出现冲突,Redis使用拉链法来解决冲突,即将散列值冲突的元素以链表的形式存入同一桶中,查找元素时先找到元素对应的桶,然后再从桶中的链表中找到对应的元素。使用SRANDMEMBER命令从集合中获得一个随机元素时,Redis首先会从所有桶中随机选择一个桶,然后再从桶中的所有元素中随机选择一个元素,所以元素所在的桶中的元素数量越少,其被随机选中的可能性就越大,如图3-19所示。注释:①如果你亲自跟着输入了命令可能会发现得到的结果与书中的结果并不相同,这是正常现象,见后文描述。
图3-19 Redis会先从3个桶中随机挑一个非空的桶,然后再从桶中随机选择一个元素,所以选中元素b的概率会大一些
4.从集合中弹出一个元素
SPOP key
3.4节中我们学习过LPOP命令,作用是从列表左边弹出一个元素(即返回元素的值并删除它)。SPOP命令的作用与之类似,但由于集合类型的元素是无序的,所以SPOP命令会从集合中随机选择一个元素弹出。例如:
redis>SPOP letters"b"redis>SMEMBERS letters1) "a"2) "c"3) "d"
11.有序集合类型
11.1 介绍 有序集合类型(sorted set)的特点从它的名字中就可以猜到,它与上一节介绍的集合类型的区别就是“有序”二字。
在集合类型的基础上有序集合类型为集合中的每个元素都关联了一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在等集合类型支持的操作,还能够获得分数最高(或最低)的前N个元素、获得指定分数范围内的元素等与分数有关的操作。虽然集合中每个元素都是不同的,但是它们的分数却可以相同。
有序集合类型在某些方面和列表类型有些相似。 (1)二者都是有序的。 (2)二者都可以获得某一范围的元素。 但是二者有着很大的区别,这使得它们的应用场景也是不同的。
(1)列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会较慢,所以它更加适合实现如“新鲜事”或“日志”这样很少访问中间元素的应用。
(2)有序集合类型是使用散列表和跳跃表(Skip list)实现的,所以即使读取位于中间部分的数据速度也很快(时间复杂度是O(log(N)))。
(3)列表中不能简单地调整某个元素的位置,但是有序集合可以(通过更改这个元素的分数)。
(4)有序集合要比列表类型更耗费内存。
有序集合类型算得上是 Redis的5种数据类型中最高级的类型了,在学习时可以与列表类型和集合类型对照理解。
11.2 命令
1.增加元素
ZADD key score member [score member …]
ZADD命令用来向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。ZADD命令的返回值是新加入到集合中的元素个数(不包含之前已经存在的元素)。
假设我们用有序集合模拟计分板,现在要记录Tom、Peter和David三名运动员的分数(分别是89分、67分和100分):
redis>ZADD scoreboard 89 Tom 67 Peter 100 David(integer) 3
这时我们发现Peter的分数录入有误,实际的分数应该是76分,可以用ZADD命令修改Peter的分数:
redis>ZADD scoreboard 76 Peter(integer) 0
分数不仅可以是整数,还支持双精度浮点数:
redis>ZADD testboard 17E+307 a(integer) 1redis>ZADD testboard 1.5 b(integer) 1redis>ZADD testboard +inf c(integer) 1redis>ZADD testboard -inf d(integer) 1
其中+inf和-inf分别表示正无穷和负无穷。
2.获得元素的分数
ZSCORE key member 示例如下:
redis>ZSCORE scoreboard Tom"89"
3.获得排名在某个范围的元素列表
ZRANGE key start stop [WITHSCORES] ZREVRANGE key start stop [WITHSCORES]
ZRANGE命令会按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素(包含两端的元素)。ZRANGE命令与LRANGE命令十分相似,如索引都是从0开始,负数代表从后向前查找(-1表示最后一个元素)。就像这样:
redis>ZRANGE scoreboard 0 21) "Peter"2) "Tom"3) "David"redis>ZRANGE scoreboard 1 -11) "Tom"2) "David"
如果需要同时获得元素的分数的话可以在ZRANGE命令的尾部加上WITHSCORES参数,这时返回的数据格式就从“元素1, 元素2, …, 元素n”变为了“元素1, 分数1, 元素2, 分数2, …, 元素n, 分数n”,例如:
redis>ZRANGE scoreboard 0 -1 WITHSCORES1) "Peter"2) "76"3) "Tom"4) "89"5) "David"6) "100"
ZRANGE命令的时间复杂度为0(logn+m)(其中n为有序集合的基数,m为返回的元素个数)。
如果两个元素的分数相同,Redis会按照字典顺序(即"0"<"9"<"A"<"Z"<"a"<"z"这样的顺序)来进行排列。再进一步,如果元素的值是中文怎么处理呢?答案是取决于中文的编码方式,如使用UTF-8编码:
redis>ZADD chineseName 0 马华 0 刘墉 0 司马光 0 赵哲(integer) 4redis>ZRANGE chineseName 0 -11) "xe5x88x98xe5xa2x89"2) "xe5x8fxb8xe9xa9xacxe5x85x89"3) "xe8xb5xb5xe5x93xb2"4) "xe9xa9xacxe5x8dx8e"
可见此时Redis依然按照字典顺序排列这些元素。
ZREVRANGE命令和ZRANGE的唯一不同在于ZREVRANGE命令是按照元素分数从大到小的顺序给出结果的。
4.获得指定分数范围的元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
ZRANGEBYSCORE命令参数虽然多,但是都很好理解。该命令按照元素分数从小到大的顺序返回分数在min和max之间(包含min和max)的元素:
redis>ZRANGEBYSCORE scoreboard 80 1001) "Tom"2) "David"
如果希望分数范围不包含端点值,可以在分数前加上“(”符号。例如,希望返回80分到100分的数据,可以含80分,但不包含100分,则稍微修改一下上面的命令即可:
redis>ZRANGEBYSCORE scoreboard 80 (1001) "Tom"
min和max还支持无穷大,同ZADD命令一样,-inf 和+inf分别表示负无穷和正无穷。比如你希望得到所有分数高于80分(不包含80分)的人的名单,但你却不知道最高分是多少(虽然有些背离现实,但是为了叙述方便,这里假设可以获得的分数是无上限的),这时就可以用上+inf了:
redis>ZRANGEBYSCORE scoreboard (80 +inf1) "Tom"2) "David"
WITHSCORES参数的用法与ZRANGE命令一样,不再赘述。
了解SQL语句的读者对LIMIT offset count应该很熟悉,在本命令中LIMIToffset count与SQL中的用法基本相同,即在获得的元素列表的基础上向后偏移offset个元素,并且只获取前count个元素。为了便于演示,我们先向scoreboard键中再增加些元素:
redis>ZADD scoreboard 56 Jerry 92 Wendy 67 Yvonne(integer) 3
现在scoreboard键中的所有元素为:
redis>ZRANGE scoreboard 0 -1 WITHSCORES1) "Jerry"2) "56"3) "Yvonne"4) "67"5) "Peter"6) "76"7) "Tom"8) "89"9) "Wendy"10) "92"11) "David"12) "100"
想获得分数高于60分的从第二个人开始的3个人:
redis>ZRANGEBYSCORE scoreboard 60 +inf LIMIT 1 31) "Peter"2) "Tom"3) "Wendy"
那么,如果想获取分数低于或等于100分的前3个人怎么办呢?这时可以借助ZREVRANGEBYSCORE命令实现。对照前文提到的ZRANGE命令和ZREVRANGE命令之间的关系,相信读者很容易能明白ZREVRANGEBYSCORE命令的功能。需要注意的是ZREVRANGEBYSCORE命令不仅是按照元素分数从大往小的顺序给出结果的,而且它的min和max参数的顺序和ZRANGEBYSCORE命令是相反的。就像这样:
redis>ZREVRANGEBYSCORE scoreboard 100 0 LIMIT 0 31) "David"2) "Wendy"3) "Tom"
5.增加某个元素的分数 ZINCRBY key increment member ZINCRBY命令可以增加一个元素的分数,返回值是更改后的分数。例如,想给Jerry加4分:
redis>ZINCRBY scoreboard 4 Jerry"60"
increment也可以是个负数表示减分,例如,给Jerry减4分:
redis>ZINCRBY scoreboard -4 Jerry" 56"
如果指定的元素不存在,Redis在执行命令前会先建立它并将它的分数赋为0再执行操作。
11.4 命令拾遗
1.获得集合中元素的数量 ZCARD key 例如:
redis>ZCARD scoreboard(integer) 6
2.获得指定分数范围內的元素个数 ZCOUNT key min max 例如:
redis>ZCOUNT scoreboard 90 100(integer) 2
ZCOUNT命令的min和max参数的特性与ZRANGEBYSCORE命令中的一样:
redis>ZCOUNT scoreboard (89 +inf(integer) 2
3.删除一个或多个元素 ZREM key member [member …] ZREM命令的返回值是成功删除的元素数量(不包含本来就不存在的元素)。
redis>ZREM scoreboard Wendy(integer) 1redis>ZCARD scoreboard(integer) 5
4.按照排名范围删除元素
ZREMRANGEBYRANK key start stop
ZREMRANGEBYRANK命令按照元素分数从小到大的顺序(即索引0表示最小的值)删除处在指定排名范围内的所有元素,并返回删除的元素数量。如:
redis>ZADD testRem 1 a 2 b 3 c 4 d 5 e 6 f(integer) 6redis>ZREMRANGEBYRANK 0 2(integer) 3redis>ZRANGE testRem 0 -11) "d"2) "e"3) "f"
5.按照分数范围删除元素 ZREMRANGEBYSCORE key min max ZREMRANGEBYSCORE命令会删除指定分数范围内的所有元素,参数min和max的特性和ZRANGEBYSCORE命令中的一样。返回值是删除的元素数量。如:
redis>ZREMRANGEBYSCORE testRem (4 5(integer) 1redis>ZRANGE testRem 0 -11) "d"2) "f"
6.获得元素的排名 ZRANK key member ZREVRANK key member ZRANK命令会按照元素分数从小到大的顺序获得指定的元素的排名(从0开始,即分数最小的元素排名为0)。如:
redis>ZRANK scoreboard Peter(integer) 0
ZREVRANK命令则相反(分数最大的元素排名为0):
redis>ZREVRANK scoreboard Peter(integer) 4
7.计算有序集合的交集 ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGREGATE SUM|MIN|MAX]
ZINTERSTORE命令用来计算多个有序集合的交集并将结果存储在destination键中(同样以有序集合类型存储),返回值为destination键中的元素个数。
destination键中元素的分数是由AGGREGATE参数决定的。
(1)当AGGREGATE是SUM时(也就是默认值),destination键中元素的分数是每个参与计算的集合中该元素分数的和。例如:
redis>ZADD sortedSets1 1 a 2 b(integer) 2redis>ZADD sortedSets2 10 a 20 b(integer) 2redis>ZINTERSTORE sortedSetsResult 2 sortedSets1 sortedSets2(integer) 2redis>ZRANGE sortedSetsResult 0 -1 WITHSCORES1) "a"2) "11"3) "b"4) "22"
(2)当AGGREGATE是MIN时,destination键中元素的分数是每个参与计算的集合中该元素分数的最小值。例如:
redis>ZINTERSTORE sortedSetsResult 2 sortedSets1 sortedSets2 AGGREGATE MIN(integer) 2redis>ZRANGE sortedSetsResult 0 -1 WITHSCORES1) "a"2) "1"3) "b"4) "2"
(3)当AGGREGATE是MAX时,destination键中元素的分数是每个参与计算的集合中该元素分数的最大值。例如:
redis>ZINTERSTORE sortedSetsResult 2 sortedSets1 sortedSets2 AGGREGATE MAX(integer) 2redis>ZRANGE sortedSetsResult 0 -1 WITHSCORES1) "a"2) "10"3) "b"4)"20"
ZINTERSTORE命令还能够通过WEIGHTS参数设置每个集合的权重,每个集合在参与计算时元素的分数会被乘上该集合的权重。例如:
redis>ZINTERSTORE sortedSetsResult 2 sortedSets1 sortedSets2 WEIGHTS 1 0.1(integer) 2redis>ZRANGE sortedSetsResult 0 -1 WITHSCORES1) "a"2) "2"3) "b"4) "4"
另外还有一个命令与ZINTERSTORE命令的用法一样,名为ZUNIONSTORE,它的作用是计算集合间的并集,这里不再赘述。
12.HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
实例
以下实例演示了 HyperLogLog 的工作过程:
redis 127.0.0.1:6379> PFADD w3ckey "redis"1) (integer) 1redis 127.0.0.1:6379> PFADD w3ckey "mongodb"1) (integer) 1redis 127.0.0.1:6379> PFADD w3ckey "mysql"1) (integer) 1redis 127.0.0.1:6379> PFCOUNT w3ckey(integer) 3
Redis HyperLogLog 命令
序号 命令及描述
1 PFADD key element [element ...] 添加指定元素到 HyperLogLog 中。
2 PFCOUNT key [key ...] 返回给定 HyperLogLog 的基数估算值。
3 PFMERGE destkey sourcekey [sourcekey ...] 将多个 HyperLogLog 合并为一个 HyperLogLog
13.进阶之事务
13.1 概述
Redis中的事务(transaction)是一组命令的集合。事务同命令一样都是Redis的最小执行单位,一个事务中的命令要么都执行,要么都不执行。事务的应用非常普遍,如银行转账过程中A给B汇款,首先系统从A的账户中将钱划走,然后向B的账户增加相应的金额。这两个步骤必
须属于同一个事务,要么全执行,要么全不执行。否则只执行第一步,钱就凭空消失了,这显然让人无法接受。
事务的原理是先将属于一个事务的命令发送给Redis,然后再让Redis依次执行这些命令。
例如:
redis>MULTIOKredis>SADD "user:1:following" 2QUEUEDredis>SADD "user:2:followers" 1QUEUEDredis>EXEC1) (integer) 12) (integer) 1
上面的代码演示了事务的使用方式。首先使用MULTI命令告诉Redis:“下面我发给你的命令属于同一个事务,你先不要执行,而是把它们暂时存起来。”Redis回答:“OK。”
而后我们发送了两个SADD命令来实现关注和被关注操作,可以看到Redis遵守了承诺,没有执行这些命令,而是返回QUEUED表示这两条命令已经进入等待执行的事务队列中了。
当把所有要在同一个事务中执行的命令都发给Redis后,我们使用EXEC命令告诉Redis将等待执行的事务队列中的所有命令(即刚才所有返回QUEUED的命令)按照发送顺序依次执行。EXEC命令的返回值就是这些命令的返回值组成的列表,返回值顺序和命令的顺序相同。
Redis保证一个事务中的所有命令要么都执行,要么都不执行。如果在发送EXEC命令前客户端断线了,则Redis会清空事务队列,事务中的所有命令都不会执行。而一旦客户端发送了EXEC命令,所有的命令就都会被执行,即使此后客户端断线也没关系,因为Redis中已经记录了所有要执行的命令。
除此之外,Redis的事务还能保证一个事务内的命令依次执行而不被其他命令插入。试想客户端A需要执行几条命令,同时客户端B发送了一条命令,如果不使用事务,则客户端B的命令可能会插入到客户端A的几条命令中执行。如果不希望发生这种情况,也可以使用事务。
13.2 错误处理
有些读者会有疑问,如果一个事务中的某个命令执行出错,Redis会怎样处理呢?要回答这个问题,首先需要知道什么原因会导致命令执行出错。
(1)语法错误。语法错误指命令不存在或者命令参数的个数不对。比如:
redis>MULTIOKredis>SET key valueQUEUEDredis>SET key(error)ERR wrong number of arguments for 'set' commandredis> ERRORCOMMAND key(error) ERR unknown command 'ERRORCOMMAND'redis> EXEC(error) EXECABORT Transaction discarded because of previous errors.
跟在MULTI命令后执行了3个命令:一个是正确的命令,成功地加入事务队列;其余两个命令都有语法错误。而只要有一个命令有语法错误,执行EXEC命令后Redis就会直接返回错误,连语法正确的命令也不会执行。
注释:Redis 2.6.5之前的版本会忽略有语法错误的命令,然后执行事务中其他语法正确的命令。就此例而言,SET key value会被执行,EXEC命令会返回一个结果:1) OK。
(2)运行错误。运行错误指在命令执行时出现的错误,比如使用散列类型的命令操作集合类型的键,这种错误在实际执行之前Redis是无法发现的,所以在事务里这样的命令是会被Redis接受并执行的。如果事务里的一条命令出现了运行错误,事务里其他的命令依然会继续
执行(包括出错命令之后的命令),示例如下:
redis>MULTIOKredis>SET key 1QUEUEDredis>SADD key 2QUEUEDredis>SET key 3QUEUEDredis>EXEC1) OK2) (error) ERR Operation against a key holding the wrong kind of value3) OKredis>GET key"3"
可见虽然SADD key 2出现了错误,但是SET key 3依然执行了。Redis的事务没有关系数据库事务提供的回滚(rollback) 功能。为此开发者必须在事务执行出错后自己收拾剩下的摊子(将数据库复原回事务执行前的状态等)。
不过由于Redis不支持回滚功能,也使得Redis在事务上可以保持简洁和快速。另外回顾刚才提到的会导致事务执行失败的两种错误,其中语法错误完全可以在开发时找出并解决,另外如果能够很好地规划数据库(保证键名规范等)的使用,是不会出现如命令与数据类型不匹配这样的运行错误的。
13.3 WATCH命令介绍
我们已经知道在一个事务中只有当所有命令都依次执行完后才能得到每个结果的返回值,可是有些情况下需要先获得一条命令的返回值,然后再根据这个值执行下一条命令。例如,介绍INCR命令时曾经说过使用GET和SET命令自己实现incr函数会出现竞态条件,伪代码如下:
def incr( key)value=GET keyif not valuevalue=0value= value+1SET key, valuereturn value
肯定会有很多读者想到可以用事务来实现incr函数以防止竞态条件,可是因为事务中的每个命令的执行结果都是最后一起返回的,所以无法将前一条命令的结果作为下一条命令的参数,即在执行SET命令时无法获得GET命令的返回值,也就无法做到增1的功能了。
为了解决这个问题,我们需要换一种思路。即在GET获得键值后保证该键值不被其他客户端修改,直到函数执行完成后才允许其他客户端修改该键键值,这样也可以防止竞态条件。要实现这一思路需要请出事务家族的另一位成员:WATCH。WATCH命令可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行。监控一直持续到EXEC命令(事务中的命令是在EXEC之后才执行的,所以在MULTI命令后可以修改WATCH监控的键值),如:
redis>SET key 1OKredis>WATCH keyOKredis>SET key 2OKredis>MULTIOKredis>SET key 3QUEUEDredis>EXEC(nil)redis>GET key"2"
上例中在执行WATCH命令后、事务执行前修改了key的值(即SET key 2),所以最后事务中的命令SET key 3没有执行,EXEC命令返回空结果。
学会了WATCH命令就可以通过事务自己实现incr函数了,伪代码如下:
def incr( key)WATCH keyvalue=GET keyif not valuevalue=0value= value+1MULTISET key, valueresult=EXECreturn result[0]
因为EXEC命令返回值是多行字符串类型,所以代码中使用result[0]来获得其中第一个结果。
提示 由于WATCH命令的作用只是当被监控的键值被修改后阻止之后一个事务的执行,而不能保证其他客户端不修改这一键值,所以我们需要在EXEC执行失败后重新执行整个函数。
执行EXEC命令后会取消对所有键的监控,如果不想执行事务中的命令也可以使用UNWATCH命令来取消监控。比如,我们要实现hsetxx函数,作用与HSETNX命令类似,只不过是仅当字段存在时才赋值。为了避免竞态条件我们使用事务来完成这一功能:
def hsetxx( key, field, value)WATCH keyisFieldExists = HEXISTS key, fieldif isFieldExists is 1MULTIHSET key, field, valueEXECelseUNWATCHreturn isFieldExists
在代码中会判断要赋值的字段是否存在,如果字段不存在的话就不执行事务中的命令,但需要使用UNWATCH命令来保证下一个事务的执行不会受到影响。
14.进阶之生存时间
14.1 命令介绍
在实际的开发中经常会遇到一些有时效的数据,比如限时优惠活动、缓存或验证码等,过了一定的时间就需要删除这些数据。在关系数据库中一般需要额外的一个字段记录到期时间,然后定期检测删除过期数据。而在Redis中可以使用EXPIRE命令设置一个键的生存时间,到时间后Redis会自动删除它。EXPIRE命令的使用方法为EXPIRE key seconds,其中seconds参数表示键的生存时间,单位是秒。如要想session:29e3d键在15分钟后被删除:
redis>SET session:29e3d uid1314OKredis>EXPIRE session:29e3d 900(integer) 1
EXPIRE命令返回1表示设置成功,返回0则表示键不存在或设置失败。例如:
redis>DEL session:29e3d(integer) 1redis>EXPIRE session:29e3d 900(integer) 0
如果想知道一个键还有多久的时间会被删除,可以使用TTL命令。返回值是键的剩余时间(单位是秒):
redis>SET foo barOKredis>EXPIRE foo 20(integer) 1redis>TTL foo(integer) 15redis>TTL foo(integer) 7redis> TTL foo(integer) -1
可见随着时间的不同,foo键的生存时间逐渐减少,20秒后foo键会被删除。当键不存在时TTL命令会返回1。另外同样会返回1的情况是没有为键设置生存时间(即永久存在,这是建立一个键后的默认情况):
redis>SET persistKey valueOKredis>TTL persistKey(integer) -1
如果想取消键的生存时间设置(即将键恢复成永久的),可以使用PERSIST命令。如果生存时间被成功清除则返回1;否则返回0(因为键不存在或键本来就是永久的):
redis>SET foo barOKredis>EXPIRE foo 20(integer) 1redis>PERSIST foo(integer) 1redis>TTL foo(integer) -1
除了PERSIST命令之外,使用SET或GETSET命令为键赋值也会同时清除键的生存时间,例如:
redis>EXPIRE foo 20(integer) 1redis>SET foo barOKredis>TTL foo(integer) -1
使用EXPIRE命令会重新设置键的生存时间,就像这样:
redis>SET foo barOKredis>EXPIRE foo 20(integer) 1redis>TTL foo(integer) 15redis>EXPIRE foo 20(integer) 1redis>TTL foo(integer) 17
其他只对键值进行操作的命令(如INCR、LPUSH、HSET、ZREM)均不会影响键的生存时间。
EXPIRE命令的seconds参数必须是整数,所以最小单位是1秒。如果想要更精确的控制键的生存时间应该使用PEXPIRE命令,PEXPIRE命令与EXPIRE的唯一区别是前者的时间单位是毫秒,即PEXPIRE key 1000与EXPIRE key 1等价。对应地可以用PTTL命令以毫秒为单位返回键的剩余时间。
提示 如果使用WATCH命令监测了一个拥有生存时间的键,该键时间到期自动删除并不会被WATCH命令认为该键被改变。
另外还有两个相对不太常用的命令:EXPIREAT和PEXPIREAT。
EXPIREAT命令与EXPIRE命令的差别在于前者使用Unix时间作为第二个参数表示键的生存时间的截止时间。PEXPIREAT命令与EXPIREAT命令的区别是前者的时间单位是毫秒。例如:
redis>SET foo barOKredis>EXPIREAT foo 1351858600(integer) 1redis>TTL foo(integer) 142redis>PEXPIREAT foo 1351858700000(integer) 1
14.3 实现缓存
为了提高网站的负载能力,常常需要将一些访问频率较高但是对CPU或IO资源消耗较大的操作的结果缓存起来,并希望让这些缓存过一段时间自动过期。比如教务网站要对全校所有学生的各个科目的成绩汇总排名,并在首页上显示前10名的学生姓名,由于计算过程较耗资源,所以可以将结果使用一个Redis的字符串键缓存起来。由于学生成绩总在不断地变化,需要每隔两个小时就重新计算一次排名,这可以通过给键设置生存时间的方式实现。每次用户访问首页时程序先查询缓存键是否存在,如果存在则直接使用缓存的值;否则重新计算排名并将计算结果赋值给该键并同时设置该键的生存时间为两个小时。伪代码如下:
rank=GET cache:rankif not rankrank=计算排名...MUlTISET cache:rank, rankEXPIRE cache:rank, 7200EXEC
然而在一些场合中这种方法并不能满足需要。当服务器内存有限时,如果大量地使用缓存键且生存时间设置得过长就会导致Redis占满内存;另一方面如果为了防止Redis占用内存过大而将缓存键的生存时间设得太短,就可能导致缓存命中率过低并且大量内存白白地闲置。
实际开发中会发现很难为缓存键设置合理的生存时间,为此可以限制Redis能够使用的最大内存,并让Redis按照一定的规则淘汰不需要的缓存键,这种方式在只将Redis用作缓存系统时非常实用。
具体的设置方法为:修改配置文件的maxmemory参数,限制Redis最大可用内存大小(单位是字节),当超出了这个限制时Redis会依据maxmemory-policy参数指定的策略来删除不需要的键,直到Redis占用的内存小于指定内存。
maxmemory-policy支持的规则如表4-1所示。其中的LRU(Least Recently Used)算法即“最近最少使用”,其认为最近最少使用的键在未来一段时间内也不会被用到,即当需要空间时这些键是可以被删除的。
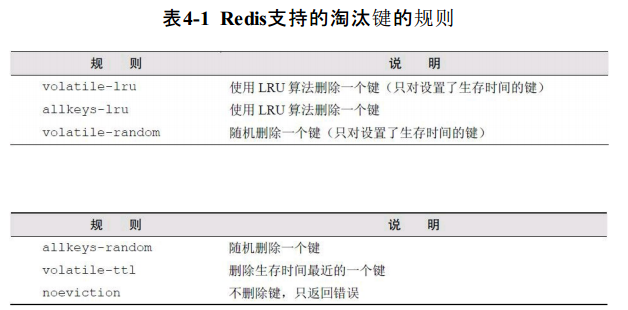
如当maxmemory-policy设置为allkeys-lru时,一旦Redis占用的内存超过了限制值,Redis会不断地删除数据库中最近最少使用的键① ,直到占用的内存小于限制值。
注释:①事实上Redis并不会准确地将整个数据库中最久未被使用的键删除,而是每次从数据库中随机取3个键并删除这3个键中最久未被使用的键。删除生存时间最接近的键的实现方法也是这样。“3”这个数字可以通过Redis的配置文件中的maxmemory-samples参数设置。
15.进阶之排序
午后,宋老师正在批改学生们提交的程序,再过几天就会迎来第一次计算机全市联考。他在每个学生的程序代码末尾都用注释详细地做了批注——严谨的治学态度让他备受学生们的爱戴。
一个电话打来。“小白的?”宋老师拿出手机,“博客最近怎么样了?”未及小白开口,他就抢先问道。
特别好!现在平均每天都有50多人访问我的博客。不过咋天我收到一个访客的邮件,他向我反映了一个问题:查看一个标签下的文章列表时文章不是按照时间顺序排列的,找起来很麻烦。我看了一下代码,发现程序中是使用SMEMBERS命令获取标签下的文章列表,因为集合类型是无序的,所以不能实现按照文章的发布时间排列。我考虑过使用有序集合类型存储标签,但是有序集合类型的集合操作不如集合类型强大。您有什么好方法来解决这个问题吗?
方法有很多,我推荐使用SORT命令,你先挂了电话,我写好后发邮件给你吧。
15.1 有序集合的集合操作
集合类型提供了强大的集合操作命令,但是如果需要排序就要用到有序集合类型。Redis的作者在设计Redis的命令时考虑到了不同数据类型的使用场景,对于不常用到的或者在不损失过多性能的前提下可以使用现有命令来实现的功能,Redis就不会单独提供命令来实现。这一原则使得Redis在拥有强大功能的同时保持着相对精简的命令。
有序集合常见的使用场景是大数据排序,如游戏的玩家排行榜,所以很少会需要获得键中的全部数据。同样Redis认为开发者在做完交集、并集运算后不需要直接获得全部结果,而是会希望将结果存入新的键中以便后续处理。这解释了为什么有序集合只有ZINTERSTORE和ZUNIONSTORE命令而没有ZINTER和ZUNION命令。
当然实际使用中确实会遇到像小白那样需要直接获得集合运算结果的情况,除了等待Redis加入相关命令,我们还可以使用MULTI, ZINTERSTORE, ZRANGE, DEL 和EXEC 这5个命令自己实现ZINTER:
MULTIZINTERSTORE tempKey ...ZRANGE tempKey ...DEL tempKeyEXEC
15.2 SORT命令
除了使用有序集合外,我们还可以借助Redis提供的SORT命令来解决小白的问题。SORT命令可以对列表类型、集合类型和有序集合类型键进行排序,并且可以完成与关系数据库中的连接查询相类似的任务。
小白的博客中标有“ruby”标签的文章的ID分别是:“2”,“6”,“12”,“26”。由于在集合类型中所有元素是无序的,所以使用SMEMBERS命令并不能获得有序的结果① 。为了能够让博客的标签页面下的文章也能按照发布的时间顺序排列(如果不考虑发布后再修改文章发布时间,就是按照文章ID的顺序排列),可以借助SORT命令实现,方法如下所示:
注释:①集合类型经常被用于存储对象的ID,很多情况下都是整数。所以Redis对这种情况进行了特殊的优化,元素的排列是有序的。4.6节会详细介绍具体的原理。
redis>SORT tag:ruby:posts1) "2"2) "6"3) "12"4) "26"
是不是十分简单?除了集合类型,SORT命令还可以对列表类型和有序集合类型进行排序:
redis>LPUSH mylist 4 2 6 1 3 7(integer)6redis>SORT mylist1) "1"2) "2"3) "3"4) "4"5) "6"6) "7"
在对有序集合类型排序时会忽略元素的分数,只针对元素自身的值进行排序。例如:
redis>ZADD myzset 50 2 40 3 20 1 60 5(integer) 4redis>SORT myzset1) "1"2) "2"3) "3"4) "5"
除了可以排列数字外,SORT命令还可以通过ALPHA参数实现按照字典顺序排列非数字元素,就像这样:
redis>LPUSH mylistalpha a c e d B C A(integer) 7redis>SORT mylistalpha(error) ERR One or more scores can't be converted into doubleredis>SORT mylistalpha ALPHA1) "A"2) "B"3) "C"4) "a"5) "c"6) "d"7) "e"
从这段示例中可以看到如果没有加ALPHA参数的话,SORT命令会尝试将所有元素转换成双精度浮点数来比较,如果无法转换则会提示错误。
回到小白的问题,SORT命令默认是按照从小到大的顺序排列,而一般博客中显示文章的顺序都是按照时间倒序的,即最新的文章显示在最前面。SORT命令的 DESC参数可以实现将元素按照从大到小的顺序排列:
redis>SORT tag:ruby:posts DESC1) "26"2) "12"3) "6"4) "2"
那么如果文章数量过多需要分页显示呢?SORT命令还支持LIMIT参数来返回指定范围的结果。用法和SQL语句一样,LIMIT offset count,表示跳过前offset个元素并获取之后的count个元素。
SORT命令的参数可以组合使用,像这样:
redis>SORT tag:ruby:posts DESC LIMIT 1 21) "12"2) "6"
15.3 BY参数
很多情况下列表(或集合、有序集合)中存储的元素值代表的是对象的ID(如标签集合中存储的是文章对象的ID),单纯对这些ID自身排序有时意义并不大。更多的时候我们希望根据ID对应的对象的某个属性进行排序。回想3.6节,我们通过使用有序集合键来存储文章ID列表,使得小白的博客能够支持修改文章时间,所以文章ID的顺序和文章的发布时间的顺序并不完全一致,因此15.2节介绍的对文章ID本身排序就变得没有意义了。小白的博客是使用散列类型键存储文章对象的,其中time字段存储的就是文章的发布时间。
现在我们知道ID为“1352619200”,“1352619600”,“1352620100”和“1352620000”(Unix时间)。
如果要按照文章的发布时间递减排列结果应为“12”,“26”,“6”,“2”。为了获得这样的结果,需要使用SORT命令的另一个强大的参数——BY。
BY 参数的语法为“BY参考键”。其中参考键可以是字符串类型键或者是散列类型键的某个字段(表示为键名->字段名)。如果提供了BY参数,SORT命令将不再依据元素自身的值进行排序,而是对每个元素使用元素的值替换参考键中的第一个“*”并获取其值,然后依据该值对元素排序。就像这样:
redis>SORT tag:ruby:posts BY post:*->time DESC1) "12"2) "26"3) "6"4) "2"
在上例中SORT命令会读取post:2、post:6、post:12、post:26几个散列键中的time字段的值并以此决定tag:ruby:posts键中各个文章ID的顺序。
除了散列类型之外,参考键还可以是字符串类型,比如:
redis>LPUSH sortbylist 2 1 3(integer) 3redis>SET itemscore:1 50OKredis>SET itemscore:2 100OKredis>SET itemscore:3 -10OKredis>SORT sortbylist BY itemscore:* DESC1) "2"2) "1"3) "3"
当参考键名不包含“*”时(即常量键名,与元素值无关),SORT命令将不会执行排序操作,因为Redis认为这种情况是没有意义的(因为所有要比较的值都一样)。例如:
redis>SORT sortbylist BY anytext1) "3"2) "1"3) "2"
例子中anytext是常量键名(甚至anytext键可以不存在),此时SORT的结果与LRANGE的结果相同,没有执行排序操作。在不需要排序但需要借助SORT命令获得与元素相关联的数据时(见15.4节),常量键名是很有用的。
如果几个元素的参考键值相同,则SORT命令会再比较元素本身的值来决定元素的顺序。像这样:
redis>LPUSH sortbylist 4(integer) 4redis>SET itemscore:4 50OKredis>SORT sortbylist BY itemscore:* DESC1) "2"2) "4"3) "1"4) "3"
示例中元素“4”的参考键itemscore:4的值和元素“1”的参考键itemscore:1的值都是50,所以SORT命令会再比较“4”和“1”元素本身的大小来决定两者的顺序。
当某个元素的参考键不存在时,会默认参考键的值为0:
redis>LPUSH sortbylist 5(integer) 5redis>SORT sortbylist BY itemscore:* DESC1) "2"2) "4"3) "1"4) "5"5) "3"
上例中“5”排在了“3”的前面,是因为“5”的参考键不存在,所以默认为0,而“3”的参考键值为10。
补充知识 参考键虽然支持散列类型,但是“*”只能在“->”符号前面(即键名部分)才有用,在“->”后(即字段名部分)会被当成字段名本身而不会作为占位符被元素的值替換,即常量键名。但是实际运行时会发现一个有趣的结果:
redis>SORT sortbylist BY somekey->somefield:*1) "1"2) "2"3) "3"4) "4"5) "5"
上面提到了当参考键名是常量键名时SORT命令将不会执行排序操作,然而上例中确进行了排序,而且只是对元素本身进行排序。这是因为Redis判断参考键名是不是常量键名的方式是判断参考键名中是否包含“”,而somekey->somefield:中包含“”所以不是常量键名。所以在排序的时候Redis对每个元素都会读取键somekey中的somefield:字段(“*”不会被替換),无论能否获得其值,每个元素的参考键值是相同的,所以Redis会按照元素本身的大小排列。
15.4 GET参数
现在小白的博客已经可以按照文章的发布顺序获得一个标签下的文章ID列表了,接下来要做的事就是对每个ID都使用HGET命令获取文章的标题以显示在博客列表页中。有没有觉得很麻烦?不论你的答案如何,都有一种更简单的方式来完成这个操作,那就是借助SORT命令的GET参数。
GET参数不影响排序,它的作用是使SORT命令的返回结果不再是元素自身的值,而是GET参数中指定的键值。GET参数的规则和BY参数一样,GET参数也支持字符串类型和散列类型的键,并使用“*”作为占位符。要实现在排序后直接返回ID对应的文章标题,可以这样写:
redis>SORT tag:ruby:posts BY post:*->time DESC GET post:*->title1) "Windows 8 app designs"2) "RethinkDB - An open-source distributed database built with love"3) "Uses for cURL"4) "The Nature of Ruby"
在一个SORT命令中可以有多个GET参数(而BY参数只能有一个),所以还可以这样用:
redis>SORT tag:ruby:posts BY post:*->time DESC GET post:*->title GET post:*->time1) "Windows 8 app designs"2) "1352620100"3) "RethinkDB - An open-source distributed database built with love"4) "1352620000"5) "Uses for cURL"6) "1352619600"7) "The Nature of Ruby"8) "1352619200"
可见有N个GET参数,每个元素返回的结果就有N行。这时有个问题:如果还需要返回文章ID该怎么办?答案是使用GET #。就像下面这样:
redis>SORT tag:ruby:posts BY post:*->time DESC GET post:*->title GET post:*->time GET #1) "Windows 8 app designs"2) "1352620100"3) "12"4) "RethinkDB - An open-source distributed database built with love"5) "1352620000"6) "26"7) "Uses for cURL"8) "1352619600"9) "6"10) "The Nature of Ruby"11) "1352619200"12) "2"
也就是说,GET #会返回元素本身的值。
15.5 STORE参数
默认情况下SORT会直接返回排序结果,如果希望保存排序结果,可以使用STORE参数。如希望把结果保存到sort.result键中:
redis>SORT tag:ruby:posts BY post:*->time DESC GET post:*->title GET post:*->timeGET # STORE sort.result(integer) 12redis>LRANGE sort.result 0 -11) "Windows 8 app designs"2) "1352620100"3) "12"4) "RethinkDB - An open-source distributed database built with love"5) "1352620000"6) "26"7) "Uses for cURL"8) "1352619600"9) "6"10) "The Nature of Ruby"11) "1352619200"12) "2"
保存后的键的类型为列表类型,如果键已经存在则会覆盖它。加上STORE参数后SORT命令的返回值为结果的个数。
STORE参数常用来结合EXPIRE命令缓存排序结果,如下面的伪代码:
#判断是否存在之前排序结果的缓存isCacheExists = EXISTS cache.sortif isCacheExists is 1#如果存在则直接返回return LRANGE cache.sort, 0, -1else#如果不存在,则使用SORT命令排序并将结果存入cache.sort键中作为缓存sortResult=SORT some.list STORE cache.sort#设置缓存的生存时间为10分钟EXPIRE cache.sort, 600#返回排序结果return sortResult
15.6 性能优化
SORT是Redis中最强大最复杂的命令之一,如果使用不好很容易成为性能瓶颈。SORT命令的时间复杂度是0(n+mlogm),其中n表示要排序的列表(集合或有序集合)中的元素个数,m表示要返回的元素个数。当n较大的时候SORT命令的性能相对较低,并且Redis在排序前会建立一个长度为n① 的容器来存储待排序的元素,虽然是一个临时的过程,但如果同时进行较多的大数据量排序操作则会严重影响性能。
注释:①有一个例外是当键类型为有序集合且参考键为常量键名时容器大小为m而不是n。
所以开发中使用SORT命令时需要注意以下几点。
(1)尽可能减少待排序键中元素的数量(使n尽可能小)。
(2)使用LIMIT参数只获取需要的数据(使m尽可能小)。
(3)如果要排序的数据数量较大,尽可能使用STORE参数将结果缓存。
16.进阶之消息通知
凭着小白的用心经营,博客的访问量逐渐增多,甚至有了小白自己的粉丝。这不,小白刚收到一封来自粉丝的邮件,在邮件中那个粉丝强烈建议小白给博客加入邮件订阅功能,这样当小白发布新文章后订阅小白博客的用户就可以收到通知邮件了。在信的末尾,那个粉丝还着重强调了一下:“这个功能对不习惯使用RSS的用户很重要,希望能够加上!”
看过信后,小白心想:“是个好建议!不过话说回来,似乎他还没发现其实我的博客连RSS功能都没有。”
邮件订阅功能太好实现了,无非是在博客首页放一个文本框供访客输入自己的邮箱地址,提交后博客会将该地址存入Redis的一个集合类型键中(使用集合类型是为了保证同一邮箱地址不会存储多个)。每当发布新文章时,就向收集到的邮箱地址发送通知邮件。
想的简单,可是做出来后小白却发现了一个问题:输入邮箱地址提交后,页面需要很久时间才能载入完。
原来小白为了确保用户没有输入他人的邮箱,在提交之后程序会向用户输入的邮箱发送一封包含确认链接的邮件,只有用户单击这个链接后对应的邮箱地址才会被程序记录。可是由于发送邮件需要连接到一个远程的邮件发送服务器,网络好的情况下也得花上2秒左右的时间,赶上网络不好10秒都必能发完。所以每次用户提交邮箱后页面都要等待程序发送完邮件才能加载出来,而加载出来的页面上显示的内容只是提示用户查看自己的邮箱单击确认链接。“完全可以等页面加载出来后再发送邮件,这样用户就不需要等了。”小白喃喃道。
按照惯例,有问题问宋老师,小白给宋老师发了一封邮件,不久就收到了答复。
16.1 任务队列
小白的问题在网站开发中十分常见,当页面需要进行如发送邮件、复杂数据运算等耗时较长的操作时会阻塞页面的渲染。为了避免用户等待太久,应该使用独立的线程来完成这类操作。不过一些编程语言或框架不易实现多线程,这时很容易就会想到通过其他进程来实现。
就小白的例子来说,设想有一个进程能够完成发邮件的功能,那么在页面中只需要想办法通知这个进程向指定的地址发送邮件就可以了。
通知的过程可以借助任务队列来实现。任务队列顾名思义,就是“传递任务的队列”。与任务队列进行交互的实体有两类,一类是生产者(producer),一类是消费者(consumer)。生产者会将需要处理的任务放入任务队列中,而消费者则不断地从任务队列中读入任务信息并执行。
对于发邮件这个操作来说页面程序就是生产者,而发邮件的进程就是消费者。当需要发送邮件时,页面程序会将收件地址、邮件主题和邮件正文组装成一个任务后存入任务队列中。同时发邮件的进程会不断检查任务队列,一旦发现有新的任务便会将其从队列中取出并执行。由此实现了进程间的通信。
使用任务队列有如下好处。
(1)松耦合。生产者和消费者无需知道彼此的实现细节,只需要约定好任务的描述格式。这使得生产者和消费者可以由不同的团队使用不同的编程语言编写。
(2)易于扩展消费者可以有多个,而且可以分布在不同的服务器中,如图4-1所示。借此可以轻易地降低单台服务器的负载。
16.2 使用Redis实现任务队列
说到队列很自然就能想到Redis的列表类型,3.4.2节介绍了使用LPUSH和RPOP命令实现队列的概念。如果要实现任务队列,只需要让生产者将任务使用LPUSH命令加入到某个键中,另一边让消费者不断地使用RPOP命令从该键中取出任务即可。
在小白的例子中,完成发邮件的任务需要知道收件地址、邮件主题和邮件正文。所以生产者需要将这三个信息组成对象并序列化成字符串,然后将其加入到任务队列中。而消费者则循环从队列中拉取任务,就像如下伪代码:
#无限循环读取任务队列中的内容looptask=RPOR queueif task#如果任务队列中有任务则执行它execute( task)else#如果没有则等待1秒以免过于频繁地请求数据wait 1 second
到此一个使用Redis实现的简单的任务队列就写好了。不过还有一点不完美的地方:当任务队列中没有任务时消费者每秒都会调用一次RPOP命令查看是否有新任务。如果可以实现一旦有新任务加入任务队列就通知消费者就好了。其实借助 BRPOP 命令就可以实现这样的需求。
BRPOP命令和RPOP命令相似,唯一的区别是当列表中没有元素时BRPOP命令会一直阻塞住连接,直到有新元素加入。如上段代码可改写为:
loop#如果任务队列中没有新任务,BRPOP 命令会一直阻塞,不会执行execute()。task=BRPOP queue, 0#返回值是一个数组(见下介绍),数组第二个元素是我们需要的任务。execute( task[1])
BRPOP命令接收两个参数,第一个是键名,第二个是超时时间,单位是秒。当超过了此时间仍然没有获得新元素的话就会返回nil。上例中超时时间为“0”,表示不限制等待的时间,即如果没有新元素加入列表就会永远阻塞下去。
当获得一个元素后BRPOP命令返回两个值,分别是键名和元素值。为了测试BRPOP命令,我们可以打开两个redis-cli实例,在实例A中:
redis A>BRPOP queue 0
键入回车后实例1会处于阻塞状态,这时在实例B中向queue中加入一个元素:
redis B>LPUSH queue task(integer) 1
在LPUSH命令执行后实例A马上就返回了结果:
1) "queue"2) "task"
同时会发现queue中的元素已经被取走:
redis>LLEN queue(integer) 0
除了BRPOP命令外,Redis还提供了BLPOP,和BRPOP的区别在与从队列取元素时BLPOP会从队列左边取。具体可以参照LPOP理解,这里不再赘述。
16.3 优先级队列
前面说到了小白博客需要在发布文章的时候向每个订阅者发送邮件,这一步骤同样可以使用任务队列实现。由于要执行的任务和发送确认邮件一样,所以二者可以共用一个消费者。然而设想这样的情况:假设订阅小白博客的用户有1000人,那么当发布一篇新文章后博客就会向任务队列中添加1000个发送通知邮件的任务。如果每发一封邮件需要10秒,全部完成这1000个任务就需要近3个小时。问题来了,假如这期间有新的用户想要订阅小白博客,当他提交完自己的邮箱并看到网页提示他查收确认邮件时,他并不知道向自己发送确认邮件的任务被加入到了已经有1000个任务的队列中。要收到确认邮件,他不得不等待近3个小时。多么糟糕的用户体验!而另一方面发布新文章后通知订阅用户的任务并不是很紧急,大多数用户并不要求有新文章后马上就能收到通知邮件,甚至延迟一天的时间在很多情况下也是可以接受的。
所以可以得出结论当发送确认邮件和发送通知邮件两种任务同时存在时,应该优先执行前者。为了实现这一目的,我们需要实现一个优先级队列。
BRPOP命令可以同时接收多个键,其完整的命令格式为BLPOP key [key …]timeout,如BLPOP queue:1 queue:2 0。意义是同时检测多个键,如果所有键都没有元素则阻塞,如果其中有一个键有元素则会从该键中弹出元素。
例如,打开两个redis-cli实例,在实例A中:
redis A>BLPOP queue:1 queue:2 queue:3 0
在实例B中:
redis B>LPUSH queue:2 task(integer) 1
则实例A中会返回:
1) "queue:2"2) "task"
如果多个键都有元素则按照从左到右的顺序取第一个键中的一个元素。我们先在queue:2和queue:3中各加入一个元素:
redis>LPUSH queue:2 task11) (integer) 1redis>LPUSH queue:3 task22) (integer) 1
然后执行BRPOP命令:
redis>BRPOP queue:1 queue:2 queue:3 01) "queue:2"2) "task1"
借此特性可以实现区分优先级的任务队列。我们分别使用queue:confirmation.email和queue:notification.email两个键存储发送确认邮件和发送通知邮件两种任务,然后将消费者的代码改为:
looptask =BRPOP queue:confirmation.email,queue:notification.email,0execute( task[1])
这时一旦发送确认邮件的任务被加入到queue:confirmation.email队列中,无论queue:notification.email还有多少任务,消费者都会优先完成发送确认邮件的任务。
16.4 “发布/订阅”模式
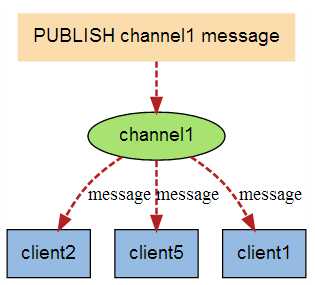
除了实现任务队列外,Redis还提供了一组命令可以让开发者实现“发布/订阅”(publish/subscribe)模式。“发布/订阅”模式同样可以实现进程间的消息传递,其原理是这样的:
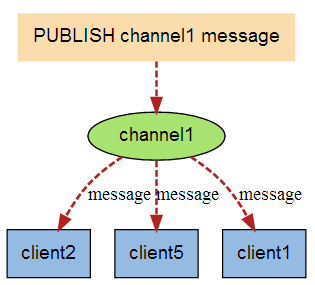
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
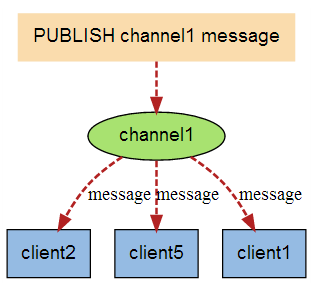
“发布/订阅”模式中包含两种角色,分别是发布者和订阅者。订阅者可以订阅一个或若干个频道(channel),而发布者可以向指定的频道发送消息,所有订阅此频道的订阅者都会收到此消息。
发布者发布消息的命令是PUBLISH,用法是PUBLISH channel message,如向channel.1说一声“hi”:
redis>PUBLISH channel.1 hi(integer) 0
这样消息就发出去了。PUBLISH命令的返回值表示接收到这条消息的订阅者数量。因为此时没有客户端订阅channel.1,所以返回0。发出去的消息不会被持久化,也就是说当有客户端订阅channel.1后只能收到后续发布到该频道的消息,之前发送的就收不到了。
订阅频道的命令是SUBSCRIBE,可以同时订阅多个频道,用法是SUBSCRIBEchannel[channel …]。现在新开一个redis-cli实例A,用它来订阅
channel.1:redis A>SUBSCRIBE channel.1Reading messages... (press Ctrl-C to quit)1) "subscribe"2) "channel.1"3) (integer) 1
执行SUBSCRIBE命令后客户端会进入订阅状态,处于此状态下客户端不能使用除SUBSCRIBE/UNSUBSCRIBE/PSUBSCRIBE/PUNSUBSCRIBE这4个属于“发布/订阅”模式的命令之外的命令(后面3个命令会在下面介绍),否则会报错。
进入订阅状态后客户端可能收到三种类型的回复。每种类型的回复都包含3个值,第一个值是消息的类型,根据消息类型的不同,第二、三个值的含义也不同。消息类型可能的取值有:
(1)Subscribe。表示订阅成功的反馈信息。第二个值是订阅成功的频道名称,第三个值是当前客户端订阅的频道数量。
(2)message。这个类型的回复是我们最关心的,它表示接收到的消息。第二个值表示产生消息的频道名称,第三个值是消息的内容。
(3)unsubscribe。表示成功取消订阅某个频道。第二个值是对应的频道名称,第三个值是当前客户端订阅的频道数量,当此值为0时客户端会退出订阅状态,之后就可以执行其他非“发布/订阅”模式的命令了。
上例中当实例A订阅了channel.1进入订阅状态后收到了一条subscribe类型的回复,这时我们打开另一个redis-cli实例B,并向channel.1发送一条消息:
redis B>PUBLISH channel.1 hi!(integer) 1
返回值为1表示有一个客户端订阅了channel.1,此时实例A 收到了类型为message的回复:
1) "message"2) "channel.1"3) "hi!"
使用UNSUBSCRIBE命令可以取消订阅指定的频道,用法为UNSUBSCRIBE[channel[channel …]],如果不指定频道则会取消订阅所有频道① 。
注释:①由于redis-cli的限制我们无法在其中测试UNSUBSCRIBE命令。
16.5 按照规则订阅
除了可以使用SUBSCRIBE命令订阅指定名称的频道外,还可以使用PSUBSCRIBE命令订阅指定的规则。规则支持glob风格通配符格式(见3.1节),下面我们新打开一个redis-cli实例C进行演示:
redis C>PSUBSCRIBE channel.?*Reading messages... (press Ctrl-C to quit)1) "psubscribe"2) "channel.?*"3) (integer) 1
规则channel.?*可以匹配channel.1和channel.10,但不会匹配channel.。这时在实例B中发布消息:
redis B>PUBLISH channel.1 hi!(integer) 2
返回结果为2是因为实例A和实例C两个客户端都订阅了channel.1频道。实例C接收到的回复是:
- "pmessage"2) "channel.?*"3) "channel.1"4) "hi!"
第一个值表示这条消息是通过PSUBSCRIBE命令订阅频道而收到的,第二个值表示订阅时使用的通配符,第三个值表示实际收到消息的频道命令,第四个值则是消息内容。
提示 使用PSUBSCRIBE命令可以重复订阅一个频道,如某客户端执行了PSUBSCRIBE channel.? channel.?,这时向channel.2发布消息后该客户端会收到两条消息,而同时PUBLISH命令返回的值也是2而不是1。同样的,如果有另一个客户端执行了SUBSCRIBE channel.10,和PSUBSCRIBE channel.?的话,向channel.10发送命令该客户端也会收到两条消息(但是是两种类型,message 和pmessage),同时PUBLISH命令会返回2。
PUNSUBSCRIBE命令可以退订指定的规则,用法是PUNSUBSCRIBE [pattern[pattern …]],如果没有参数则会退订所有规则。
注意 使用PUNSUBSCRIBE命令只能退订通过PSUBSCRIBE命令订阅的规则,不会影响直接通过SUBSCRIBE命令订阅的频道;同样UNSUBSCRIBE命令也不会影响通过PSUBSCRIBE命令订阅的规则。另外容易出错的一点是使用PUNSUBSCRIBE命令退订某个规则时不会将其中的通配符展开,而是进行严格的字符串匹配,所以PUNSUBSCRIBE无法退订channel.规则,而是必须使用PUNSUBSCRIBE channel.*才能退订。
17.管道
客户端和Redis使用TCP协议连接。不论是客户端向Redis发送命令还是Redis向客户端返回命令的执行结果,都需要经过网络传输,这两个部分的总耗时称为往返时延。根据网络性能不同,往返时延也不同,大致来说到本地回环地址(loop backaddress)的往返时延在数量级上相当于Redis处理一条简单命令(如LPUSH list 1 2 3)的时间。如果执行较多的命令,每个命令的往返时延累加起来对性能还是有一定影响的。
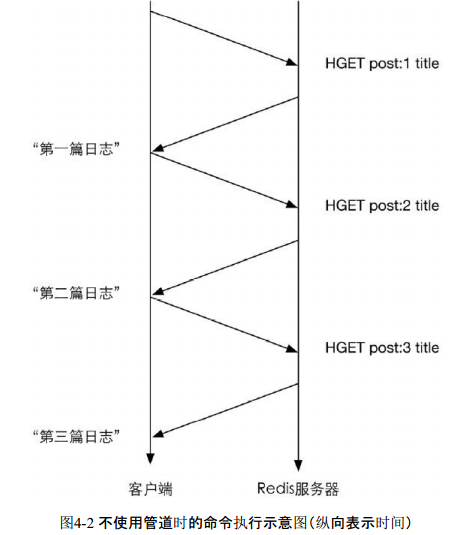
在执行多个命令时每条命令都需要等待上一条命令执行完(即收到Redis的返回结果)才能执行,即使命令不需要上一条命令的执行结果。如要获得post:1、post:2和post:3这3个键中的title字段,需要执行三条命令,如图4-2所示。
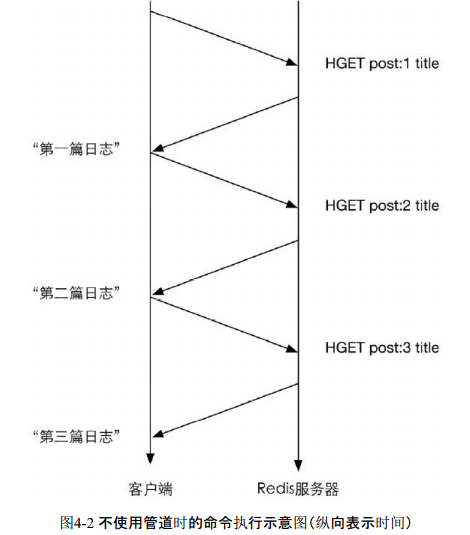
Redis的底层通信协议对管道(pipelining)提供了支持。通过管道可以一次性发送多条命令并在执行完后一次性将结果返回,当一组命令中每条命令都不依赖于之前命令的执行结果时就可以将这组命令一起通过管道发出。管道通过减少客户端与Redis的通信次数来实现降低往返时延累计值的目的,如图4-3所示。
18.进阶之节省空间
Jim Gray① 曾经说过:“内存是新的硬盘,硬盘是新的磁带 。”内存的容量越来越大,价格也越来越便宜。2012年年底,亚马逊宣布即将发布一个拥有240GB内存的EC2实例,如果放到若干年前来看,这个容量就算是对于硬盘来说也是很大的了。即便如此,相比于硬盘而言,内存在今天仍然显得比较昂贵。而Redis是一个基于内存的数据库,所有的数据都存储在内存中,所以如何优化存储,减少内存空间占用对成本控制来说是一个非常重要的话题。
注释:①Jim Gray是1998年的图灵奖得主,在数据库(尤其是事务)方面做出过卓越的贡献。其于2007年独自驾船在海上失踪。
18.1 精简键名和键值
精简键名和键值是最直观的减少内存占用的方式,如将键名very.important.person:20改成VIP:20。当然精简键名一定要把握好尺度,不能单纯为了节约空间而使用不易理解的键名(比如将VIP:20修改为V:20,这样既不易维护,还容易造成命名沖突)。又比如一个存储用户性别的字符串类型键的取值是male和female,我们可以将其修改成m和f来为每条记录节约几个字节的空间(更好的方法是使用0和1来表示性别,稍后会详细介绍原因)① 。
注释:①3.2.4节还介绍过使用字符串类型的位操作来存储性别,更加节约空间。
18.2 内部编码优化
有时候仅凭精简键名和键值所减少的空间并不足以满足需求,这时就需要根据Redis内部编码规则来节省更多的空间。Redis为每种数据类型都提供了两种内部编码方式,以散列类型为例,散列类型是通过散列表实现的,这样就可以实现0(1)时间复杂度的查找、赋值操作,然而当键中元素很少的时候,0(1)的操作并不会比0(n)有明显的性能提高,所以这种情况下Redis会采用一种更为紧凑但性能稍差(获取元素的时间复杂度为0(n))的内部编码方式。内部编码方式的选择对于开发者来说是透明的,Redis会根据实际情况自动调整。当键中元素变多时Redis会自动将该键的内部编码方式转换成散列表。如果想查看一个键的内部编码方式可以使用OBJECT ENCODING命令,例如:
redis>SET foo barOKredis>OBJECT ENCODING foo"raw"
Redis的每个键值都是使用一个redisObject结构体保存的,redisObject的定义如下:
typedef struct redisObject {unsigned type:4;unsigned notused:2; /* Not used */unsigned encoding:4;unsigned lru:22; /* lru time (relative to server.lruclock) */int refcount;void *ptr;}robj;
其中type字段表示的是键值的数据类型,取值可以是如下内容:
#define REDIS_STRING 0#define REDIS_LIST 1#define REDIS_SET 2#define REDIS_ZSET 3#define REDIS_HASH 4
encoding字段表示的就是Redis键值的内部编码方式,取值可以是:
#define REDIS_ENCODING_RAW 0 /* Raw representation */#define REDIS_ENCODING_INT 1 ed as integer */#define REDIS_ENCODING_HT 2 /* Encoded as hash table */#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
各个数据类型可能采用的内部编码方式以及相应的OBJECT ENCODING命令执行结果如表4-2所示。
下面针对每种数据类型分别介绍其内部编码规则及优化方式。
1.字符串类型
Redis使用一个sdshdr类型的变量来存储字符串,而redisObject的ptr字段指向的是该变量的地址。sdshdr的定义如下:
struct sdshdr {int len;int free;char buf[];};
其中len字段表示的是字符串的长度,free字段表示buf中的剩余空间,而buf字段存储的才是字符串的内容。
所以当执行SET key foobar时,存储键值需要占用的空间是sizeof(redisObject)+sizeof(sdshdr)+strlen("foobar")=30字节① ,如图4-4所示。
注释:①本节所说的字节数以64位Linux系统为前提。
而当键值内容可以用一个64位有符号整数表示时,Redis会将键值转换成long类型来存储。如SET key 123456,实际占用的空间是sizeof(redisObject)=16字节,比存储"foobar"节省了一半的存储空间,如图4-5所示。
redisObject中的refcount字段存储的是该键值被引用数量,即一个键值可以被多个键引用。Redis启动后会预先建立10000个分别存储从0到9999这些数字的redisObject类型变量作为共享对象,如果要设置的字符串键值在这10000个数字内(如SET key1 123)则可以直接引用共享对象而不用再建立一个redisObject了,也就是说存储键值占用的空间是0字节,如图4-6所示。
由此可见,使用字符串类型键存储对象ID这种小数字是非常节省存储空间的,Redis只需存储键名和一个对共享对象的引用即可。
提示 当通过配置文件参数maxmemory设置了Redis可用的最大空间大小时,Redis不会使用共享对象,因为对于每一个键值都需要使用一个redisObject来记录其LRU信息。
2.散列类型
散列类型的内部编码方式可能是REDIS_ENCODING_HT或REDIS_ENCODING_ZIPLIST① 。在配置文件中可以定义使用REDIS_ENCODING_ZIPLIST方式编码散列类型的时机:
注释:①在Redis 2.4及以前的版本中散列类型的键采用REDIS_ENCODING_HT或REDIS_ENCODING_ZIPMAP的编码方式。
hash-max-ziplist-entries 512hash-max-ziplist-value 64
当散列类型键的字段个数少于hash-max-ziplist-entries参数值且每个字段名和字段值的长度都小于hash-max-ziplist-value参数值(单位为字节)时,Redis就会使用REDIS_ENCODING_ZIPLIST来存储该键,否则就会使用REDIS_ENCODING_HT。转换过程是透明的,每当键值变更后Redis都会自动判断是否满足条件来完成转换。
REDIS_ENCODING_HT编码即散列表,可以实现O(1)时间复杂度的赋值取值等操作,其字段和字段值都是使用redisObject存储的,所以前面讲到的字符串类型键值的优化方法同样适用于散列类型键的字段和字段值。
提示 Redis的键值对存储也是通过散列表实现的,与REDIS_ENCODING_HT编码方式类似,但键名并非使用redisObject存储,所以键名“123456”并不会比“abcdef”占用更少的空间。之所以不对键名进行优化是因为绝大多数情况下键名都不会是纯数字。
补充知识 Redis支持多数据库,每个数据库中的数据都是通过结构体redisDb存储的。redisDb的定义如下:
typedef struct redisDb {dict *dict; /* The keyspace for this DB */dict *expires; /* Timeout of keys with a timeout set */dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */dict *ready_keys; /* Blocked keys that received a PUSH */dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */int id;} redisDb;
dict类型就是散列表结构,expires存储的是数据的过期时间。当Redis启动时会根据配置文件中databases参数指定的数量创建若干个redisDb类型变量存储不同数据库中的数据。
REDIS_ENCODING_ZIPLIST编码类型是一种紧凑的编码格式,它牺牲了部分读取性能以换取极高的空间利用率,适合在元素较少时使用。该编码类型同样还在列表类型和有序集合类型中使用。REDIS_ENCODING_ZIPLIST编码结构如图4-7所示,其中zlbytes是uint32_t类型,表示整个结构占用的空间。zltail也是uint32_t类型,表示到最后一个元素的偏移,记录zltail使得程序可以直接定位到尾部元素而无需遍历整个结构,执行从尾部弹出(对列表类型而言)等操作时速度更快。zllen是uint16_t类型,存储的是元素的数量。zlend是一个单字节标识,标记结构的末尾,值永远是255。
在REDIS_ENCODING_ZIPLIST 中每个元素由4个部分组成。
第一个部分用来存储前一个元素的大小以实现倒序查找,当前一个元素的大小小于254字节时第一个部分占用1个字节,否则会占用5个字节。
第二、三个部分分别是元素的编码类型和元素的大小,当元素的大小小于或等于63个字节时,元素的编码类型是ZIP_STR_06B(即0<<6),同时第三个部分用6个二进制位来记录元素的长度,所以第二、三个部分总占用空间是1字节。当元素的大小大于63且小于或等于16383字节时,第二、三个部分总占用空间是2字节。当元素的大小大于16383字节时,第二、三个部分总占用空间是5字节。
第四个部分是元素的实际内容,如果元素可以转换成数字的话Redis会使用相应的数字类型来存储以节省空间,并用第二、三个部分来表示数字的类型(int16_t、int32_t等)。
使用REDIS_ENCODING_ZIPLIST编码存储散列类型时元素的排列方式是:元素1存储字段1,元素2存储字段值1,依次类推,如图4-8所示。
例如,当执行命令HSET hkey foo bar命令后,hkey键值的内存结构如图4-9所示。
下次需要执行HSET hkey foo anothervalue时Redis需要从头开始找到值为foo的元素(查找时每次都会跳过一个元素以保证只查找字段名),找到后删除其下一个元素,并将新值anothervalue插入。删除和插入都需要移动后面的内存数据,而且查找操作也需要遍历才能完成,可想而知当散列键中数据多时性能将很低,所以不宜将hash-max-ziplist-entries和hash-maxziplist-value两个参数设置得很大。
3.列表类型
列表类型的内部编码方式可能是REDIS_ENCODING_LINKEDLIST或REDISENCODINGZIPLIST。同样在配置文件中可以定义使用REDIS_ENCODING_ZIPLIST方式编码的时机:
list-max-ziplist-entries 512list-max-ziplist-value 64
具体转换方式和散列类型一样,这里不再赘述。
REDIS_ENCODING_LINKEDLIST编码方式即双向链表,链表中的每个元素是用redisObject存储的,所以此种编码方式下元素值的优化方法与字符串类型的键值相同。
而使用REDIS_ENCODING_ZIPLIST编码方式时具体的表现和散列类型一样,由于REDIS_ENCODING_ZIPLIST编码方式同样支持倒序访问,所以采用此种编码方式时获取两端的数据依然较快。
4.集合类型
集合类型的内部编码方式可能是REDIS_ENCODING_HT或REDIS_ENCODING_INTSET。当集合中的所有元素都是整数且元素的个数小于配置文件中的set-max-intset-entries参数指定值(默认是512)时Redis会使用REDIS_ENCODING_INTSET编码存储该集合,否则会使用REDIS_ENCODING_HT来存储。
REDIS_ENCODING_INTSET编码存储结构体intset的定义是:
typedef struct intset {uint32_t encoding;uint32_t length;int8_t contents[];} intset;
其中contents存储的就是集合中的元素值,根据encoding的不同,每个元素占用的字节大小不同。默认的encoding是INTSET_ENC_INT16(即2个字节),当新增加的整数元素无法使用2个字节表示时,Redis会将该集合的encoding升级为INTSET_ENC_INT32(即4个字节)并调整之前所有元素的位置和长度,同样集合的encoding还可升级为INTSET_ENC_INT64(即8个字节)。
REDIS_ENCODING_INTSET编码以有序的方式存储元素(所以使用SMEMBERS命令获得的结果是有序的),使得可以使用二分算法查找元素。然而无论是添加还是删除元素,Redis都需要调整后面元素的内存位置,所以当集合中的元素太多时性能较差。
当新增加的元素不是整数或集合中的元素数量超过了set-max-intset-entries参数指定值时,Redis会自动将该集合的存储结构转换成REDIS_ENCODING_HT。
注意 当集合的存储结构转換成REDIS_ENCODING_HT后,即使将集合中的所有非整数元素删除,Redis也不会自动将存储结构转換回REDIS_ENCODING_INTSET。因为如果要支持自动回转,就意味着Redis在每次删除元素时都需要遍历集合中的键来判断是否可以转換回原来的编码,这会使得删除元素变成了时间复杂度为0(n)的操作。
5.有序集合类型
有序集合类型的内部编码方式可能是REDIS_ENCODING_SKIPLIST或REDIS_ENCODING_ZIPLIST。同样在配置文件中可以定义使用REDIS_ENCODING_ZIPLIST方式编码的时机:
zset-max-ziplist-entries 128zset-max-ziplist-value 64
具体规则和散列类型及列表类型一样,不再赘述。
当编码方式是REDIS_ENCODING_SKIPLIST时,Redis使用散列表和跳跃列表(skiplist)两种数据结构来存储有序集合类型键值,其中散列表用来存储元素值与元素分数的映射关系以实现0(1)时间复杂度的ZSCORE等命令。跳跃列表用来存储元素的分数及其到元素值的映射以实现排序的功能。Redis对跳跃列表的实现进行了几点修改,其中包括允许跳跃列表中的元素(即分数)相同,还有为跳跃链表每个节点增加了指向前一个元素的指针以实现倒序查找。
采用此种编码方式时,元素值是使用redisObject存储的,所以可以使用字符串类型键值的优化方式优化元素值,而元素的分数是使用double类型存储的。
使用REDIS_ENCODING_ZIPLIST编码时有序集合存储的方式按照“元素1的值,元素1的分数,元素2的值,元素2的分数”的顺序排列,并且分数是有序的。
19.进阶之虚拟内存
20.Python操作redis
1、安装redis-py
pip install redis
API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
2、使用 redis-py
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
直接使用
`import redis
r = redis.Redis(host='192.168.49.130', port=6379)
r.set('foo', 'Bar')
print r.get('foo')`
创建连接池:
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
`import redis
pool = redis.ConnectionPool(host='192.168.49.130', port=6379)
r = redis.Redis(connection_pool=pool)
r = redis.StrictRedis(connection_pool=pool) #StrictRedis也是支持的
r.set('foo', 'Bar')
print r.get('foo')`
三、操作
String操作
redis中的String在在内存中按照一个name对应一个value来存储。如图:
img
设值
1、set
`set(name, value, ex=None, px=None, nx=False, xx=False)
设值
在Redis中设置值,默认,不存在则创建,存在则修改参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行`
2、setnx
`setnx(name, value)
设值,只有name不存在时,执行设置操作(添加)`
3、setex
`setex(name, value, time)
设值, 参数:time,过期时间(数字秒 或 timedelta对象)`
4、psetex
`psetex(name, time_ms, value)
设值 参数:time_ms,过期时间(数字毫秒 或 timedelta对象)`
5.mset
`mset(*args, **kwargs)
批量设值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})`
取值
1、get
`get(name)
取值`
2、mget
`mget(keys, *args)
批量获取
如:
mget('name', 'age')
或
r.mget(['name', 'age'])`
3、getset
`getset(name, value)
设置新值并获取原来的值`
bit方式取值设值
1、getrange
`getrange(key, start, end)
获取子序列(根据字节获取,非字符)
参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
如: "神一样的人儿" ,0-3表示 "神"`
2、setrange
`setrange(name, offset, value)
修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值`
3、setbit
`setbit(name, offset, value)
对name对应值的二进制表示的位进行操作
参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
扩展,转换二进制表示:
# source = ""
source = "foo"
for i in source:
num = ord(i)
print bin(num).replace('b','')
特别的,如果source是汉字怎么办?
#答:对于utf-8,每一个汉字占 3 个字节,汉字姓名一般为三个则有 9个字节
# 对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制
11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000`
4、getbit
`getbit(name, offset)
获取name对应的值的二进制表示中的某位的值 (0或1)`
5、bitcount
`bitcount(key, start=None, end=None)
获取name对应的值的二进制表示中 1 的个数
参数:
# key,Redis的name
# start,位起始位置
# end,位结束位置`
6、bitop
`bitop(operation, dest, *keys)
获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
参数:
# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
# dest, 新的Redis的name
# *keys,要查找的Redis的name
如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
# 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中`
获取值的长度
strlen
`strlen(name)
返回name对应值的字节长度(一个汉字3个字节)`
自增
1、incr
`incr(self, name, amount=1)
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
# name,Redis的name
# amount,自增数(必须是整数)
注:同incrby`
2、incrbyfloat
`incrbyfloat(self, name, amount=1.0)
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
# name,Redis的name
# amount,自增数(浮点型)`
3、decr
`decr(self, name, amount=1)
自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
参数:
# name,Redis的name
# amount,自减数(整数)`
追加
append
`append(key, value)
在redis name对应的值后面追加内容
参数:
key, redis的name
value, 要追加的字符串`
21.Hash操作
Hash操作,redis中Hash在内存中的存储格式如下图:
hset(name, key, value)
`# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)`
hmset(name, mapping)
`# 在name对应的hash中批量设置键值对
参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})`
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
`# 在name对应的hash中获取多个key的值
参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')`
hgetall(name)
获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
`# 自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)`
hincrbyfloat(name, key, amount=1.0)
`# 自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
自增name对应的hash中的指定key的值,不存在则创建key=amount`
hscan(name, cursor=0, match=None, count=None)
`# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕`
hscan_iter(name, match=None, count=None)
`# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:
# for item in r.hscan_iter('xx'):
# print item`
22.List操作
redis中的List在在内存中按照一个name对应一个List来存储。如图:
lpush(name,values)
`# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
扩展:
# rpush(name, values) 表示从右向左操作`
lpushx(name,value)
`# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
更多:
# rpushx(name, value) 表示从右向左操作`
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
`# 在name对应的列表的某一个值前或后插入一个新值
参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据`
r.lset(name, index, value)
`# 对name对应的list中的某一个索引位置重新赋值
参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值`
r.lrem(name, value, num)
`# 在name对应的list中删除指定的值
参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个`
lpop(name)
`# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
更多:
# rpop(name) 表示从右向左操作`
lindex(name, index)
在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
`# 在name对应的列表分片获取数据
参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置`
ltrim(name, start, end)
`# 在name对应的列表中移除没有在start-end索引之间的值
参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置`
rpoplpush(src, dst)
`# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name`
blpop(keys, timeout)
`# 将多个列表排列,按照从左到右去pop对应列表的元素
参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
更多:
# r.brpop(keys, timeout),从右向左获取数据`
brpoplpush(src, dst, timeout=0)
`# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞`
自定义增量迭代
`# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
# 1、获取name对应的所有列表
# 2、循环列表
但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index)
使用
for item in list_iter('pp'):
print item`
23.Set操作
Set集合就是不允许重复的列表
集合操作(无序)
sadd(name,values)
# name对应的集合中添加元素
scard(name)
获取name对应的集合中元素个数
sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args)
# 获取多一个name对应集合的并集
sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value)
# 检查value是否是name对应的集合的成员
smembers(name)
# 获取name对应的集合的所有成员
smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name, values)
# 在name对应的集合中删除某些值
sunion(keys, *args)
# 获取多一个name对应的集合的并集
sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name, cursor=0, match=None, count=None) sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合
在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, args, *kwargs)
# 在name对应的有序集合中添加元素``# 如:`` ``# zadd('zz', 'n1', 1, 'n2', 2)`` ``# 或`` ``# zadd('zz', n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素``# 参数:`` ``# name,redis的name`` ``# start,有序集合索引起始位置(非分数)`` ``# end,有序集合索引结束位置(非分数)`` ``# desc,排序规则,默认按照分数从小到大排序`` ``# withscores,是否获取元素的分数,默认只获取元素的值`` ``# score_cast_func,对分数进行数据转换的函数``# 更多:`` ``# 从大到小排序`` ``# zrevrange(name, start, end, withscores=False, score_cast_func=float)`` ``# 按照分数范围获取name对应的有序集合的元素`` ``# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)`` ``# 从大到小排序`` ``# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)``# 更多:`` ``# zrevrank(name, value),从大到小排序
zrangebylex(name, min, max, start=None, num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员``# 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大``# 参数:`` ``# name,redis的name`` ``# min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间`` ``# min,右区间(值)`` ``# start,对结果进行分片处理,索引位置`` ``# num,对结果进行分片处理,索引后面的num个元素``# 如:`` ``# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga`` ``# r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca']``# 更多:`` ``# 从大到小排序`` ``# zrevrangebylex(name, max, min, start=None, num=None)
zrem(name, values)
# 删除name对应的有序集合中值是values的成员``# 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zremrangebylex(name, min, max)
# 根据值返回删除
zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作``# aggregate的值为: SUM MIN MAX
zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作``# aggregate的值为: SUM MIN MAX
zscan(name, cursor=0, match=None, count=None, score_cast_func=float) zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
更多参见:https://github.com/andymccurdy/redis-py/
24.其他常用操作
delete(*names)
`# 根据删除redis中的任意数据类型
exists(name)
检测redis的name是否存在`
keys(pattern='*')
`# 根据模型获取redis的name
更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo`
expire(name ,time)
#为某个redis的某个name设置超时时间
rename(src, dst)
#对redis的name重命名为
move(name, db))
# 将redis的某个值移动到指定的db下
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None) scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
25. Python操作redis管道
为什么使用管道?
Redis是一个TCP服务器,支持请求/响应协议。 在Redis中,请求通过以下步骤完成:
客户端向服务器发送查询,并从套接字读取,通常以阻塞的方式,用于服务器响应。
服务器处理命令并将响应发送回客户端。
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。
redis-py
例如,redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
`#!/usr/bin/env python
-- coding:utf-8 --
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.set('name', 'sb')
pipe.set('sex', 'male')
前面两个操作都成功才execute(),否则回滚
pipe.execute() ps:默认的情况下,管道里执行的命令可以保证执行的原子性,执行pipe = r.pipeline(transaction=False)`可以禁用这一特性
- 发布与订阅(pub/sub)
介绍
Redis 通过 PUBLISH 、 SUBSCRIBE 等命令实现了订阅与发布模式, 这个功能提供两种信息机制, 分别是订阅/发布到频道和订阅/发布到模式
订阅者可以订阅一个或多个频道,发布者向一个频道发送消息后,所有订阅这个频道的订阅者都将收到消息,而发布者也将收到一个数值,这个数值是收到消息的订阅者的数量。订阅者只能收到自它开始订阅后发布者所发布的消息,而之前发布的消息是收不到的。
运行原理:
Redis 的 SUBSCRIBE 命令可以让客户端订阅任意数量的频道, 每当有新信息发送到被订阅的频道时, 信息就会被发送给所有订阅指定频道的客户端。
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
Python下实现Redis的发布和订阅
Demo如下:
redisPubSub.py
`#用来连接redis server并封装了发布与订阅的功能
import redis
class RedisPubSubHelper():
def __init__(self):
# redis连接对象
self.__conn = redis.Redis(host='192.168.49.130')
def publish(self, message, channel):
# redis对象的publish方法(发布)
# 往指定的频道中发布信息
self.__conn.publish(channel, message)
return True
def subscribe(self, channel):
# 返回了一个发布订阅的对象
pub = self.__conn.pubsub()
# 订阅到指定的频道上
pub.subscribe(channel)
pub.parse_response()
return pub`
订阅者:
`#!/usr/bin/env/ python
--coding:utf-8 --
import redisPubSub
创建一个连接redis的对象(使用发布与订阅模式的redis对象)
r = redisPubSub.RedisPubSubHelper()
创建发布订阅的对象
redis_sub=r.subscribe('fm104.9')# 指定订阅频道
while True:
接收频道中的内容,代码会阻塞到这里,直到收到消息
msg=redis_sub.parse_response()
print(msg)`
发布者:
`#!/usr/bin/env/ python
--coding:utf-8 --
import redisPubSub
创建一个连接redis的对象(使用发布与订阅模式的redis对象)
r = redisPubSub.RedisPubSubHelper()
向指定的频道发布消息
r.publish('hello world', 'fm104.9')`
更多参见:https://github.com/andymccurdy/redis-py/
27.Flask操作redis
待整理
28.Django操作redis
待整理
30.redis主从复制
待整理
31.redis-sentinel
待整理
32.redis-分区
待整理
33.redis-集群实战
待整理
34.redis-集群规范
待整理
35.管理-安全
Redis的作者Salvatore Sanfilippo曾经发表过Redis宣言 ,其中提到Redis以简洁为美。同样在安全层面Redis也没有做太多的工作。
35.1 可信的环境
Redis的安全设计是在“Redis运行在可信环境”这个前提下做出的,在生产环境运行时不能允许外界直接连接到Redis服务器上,而应该通过应用程序进行中转,运行在可信的环境中是保证Redis安全的最重要方法。
Redis的默认配置会接受来自任何地址发送来的请求,即在任何一个拥有公网IP的服务器上启动Redis服务器,都可以被外界直接访问到。要更改这一设置,在配置文件中修改bind参数,如只允许本机应用连接Redis,可以将bind参数改成:
bind 127.0.0.1
2.8版本之前,bind参数只能绑定一个地址 ,如果想更自由地设置访问规则需要通过防火墙来完成。
35.2 数据库密码
除此之外,还可以通过配置文件中的requirepass参数为Redis设置一个密码。例如:
requirepass TAFK(@~!ji^XALQ(sYh5xIwTn5D s7JF
客户端每次连接到Redis时都需要发送密码,否则Redis会拒绝执行客户端发来的命令。例如:
redis>GET foo(error) ERR operation not permitted
发送密码需要使用AUTH命令,就像这样:
redis>AUTH TAFK(@~!ji^XALQ(sYh5xIwTn5D s7JFOK
之后就可以执行任何命令了:
redis>GET foo" 1"
由于Redis的性能极高,并且输入错误密码后Redis并不会进行主动延迟(考虑到Redis的单线程模型),所以攻击者可以通过穷举法破解Redis的密码(1秒内能够尝试十几万个密码),因此在设置时一定要选择复杂的密码。
提示 配置Redis复制的时候如果主数据库设置了密码,需要在从数据库的配置文件中通过masterauth参数设置主数据库的密码,以使从数据库连接主数据库时自动使用AUTH命令认证。
35.3 命名命令
Redis支持在配置文件中将命令重命名,比如将FLUSHALL命令重命名成一个比较复杂的名字,以保证只有自己的应用可以使用该命令。就像这样:
rename-command FLUSHALL oyfekmjvmwxq5a9c8usofuo369x0it2k
如果希望直接禁用某个命令可以将命令重命名成空字符串:
rename-command FLUSHALL ""
注意 无论设置密码还是重命名命令,都需要保证配置文件的安全性,否则就没有任何意义了。
http://ifeve.com/redis-securit/
36.管理-通讯协议
Redis通信协议是Redis客户端与Redis之间交流的语言,通信协议规定了命令和返回值的格式。了解Redis通信协议后不仅可以理解AOF文件的格式和主从复制时主数据库向从数据库发送的内容等,还可以开发自己的Redis客户端(不过由于几乎所有常用的语言都有相应的Redis客户端,需要使用通信协议直接和Redis打交道的机会确实不多)。
Redis支持两种通信协议,一种是二进制安全的统一请求协议(unified request protocol),一种是比较直观的便于在telnet程序中输入的简单协议。这两种协议只是命令的格式有区别,命令返回值的格式是一样的。
36.1 简单协议
简单协议适合在telnet程序中和Redis通信。简单协议的命令格式就是将命令和各个参数使用空格分隔开,如“EXISTS foo”、“SET foo bar”等。由于Redis解析简单协议时只是简单地以空格分隔参数,所以无法输入二进制字符。我们可以通过telnet程序测试:
telnet 127.0.0.1 6379 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. SET foo bar +OK GET foo $3 bar LPUSH plist 1 2 3 :3 LRANGE plist 0 -1 *3 $1 3 $1 2 $1 1 ERRORCOMMAND -ERR unknown command 'ERRORCOMMAND'
提示 Redis 2.4之前的版本对于某些命令可以使用类似简单协议的特殊方式输入二进制安全的参数,例如:
C:SET foo 3 C:bar S:+OK
其中C:表示客户端发出的内容,S:表示服务端发出的内容。第一行的最后一个参数表示字符串的长度,第二行是字符串的实际内容,因为指定了长度,所以第二行的字符串可以包含二进制字符。但是这个协议已经废弃,被新的统一请求协议取代。“统一”二字指所有的命令使用同样的请求方式而不再为某些命令使用特殊方式,如果需要在参数中包含二进制字符应该使用36.2节介绍的统一请求协议。
我们在telnet程序中输入的5条命令恰好展示了Redis的5种返回值类型的格式,2.3.2节介绍了这5种返回值类型在redis-cli中的展现形式,这些展现形式是经过了redis-cli封装的,而上面的内容才是Redis真正返回的格式。下面分别介绍。
1.错误回复
错误回复(error reply)以-开头,并在后面跟上错误信息,最后以 结尾:
-ERR unknown command 'ERRORCOMMAND'
2.状态回复
状态回复(status reply)以+开头,并在后面跟上状态信息,最后以 结尾:
+OK
3.整数回复
整数回复(integer reply)以:开头,并在后面跟上数字,最后以 结尾:
:3
4.字符串回复
字符串回复(bulk reply)以 开头,并在后面跟上字符串的长度,并以 分隔,接着是字符串的内容和 :
$3
bar
如果返回值是空结果nil,则会返回 -1以和空字符串相区别。
5.多行字符串回复
多行字符串回复(multi-bulk reply)以*开头,并在后面跟上字符串回复的组数,并以 分隔。接着后面跟的就是字符串回复的具体内容了:
*3
1
3
1
2
1
1
36.2 统一请求协议
统一请求协议是从Redis 1.2开始加入的,其命令格式和多行字符串回复的格式很类似,如SET foo bar的统一请求协议写法是“*3 3 SET 3 foo 3 bar ”。还是使用telnet进行演示:
telnet 127.0.0.1 6379 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. *3 $3 SET $3 foo $3 bar +OK
同样发送命令时指定了后面字符串的长度,所以命令的每个参数都可以包含二进制的字符。统一请求协议的返回值格式和简单协议一样,这里不再赘述。
Redis的AOF文件和主从复制时主数据库向从数据库发送的内容都使用了统一请求协议。如果要开发一个和Redis直接通信的客户端,推荐使用此协议。如果只是想通过telnet向Redis服务器发送命令则使用简单协议就可以了。
37.管理-管理工具
工欲善其事,必先利其器。在使用Redis的时候如果能够有效利用Redis的各种管理工具,将会大大方便开发和管理。
37.1 redis-cli
相信大家对redis-cli已经很熟悉了,作为Redis自带的命令行客户端,你可以从任何安装有Redis的服务器中找到它,所以对于管理Redis而言redis-cli是最简单实用的工具。
redis-cli可以执行大部分的Redis命令,包括查看数据库信息的INFO命令,更改数据库设置的CONFIG命令和强制进行RDB快照的SAVE命令等,下面会介绍几个管理Redis时非常有用的命令。
1.耗时命令日志
当一条命令执行时间超过限制时,Redis会将该命令的执行时间等信息加入耗时命令日志(slow log)以供开发者查看。可以通过配置文件的slowlog-log-slower-than参数设置这一限制,要注意单位是微秒(1000000微秒相当于1秒),默认值是10000。耗时命令日志存储在内存中,可以通过配置文件的slowlog-max-len参数来限制记录的条数。
使用SLOWLOG GET命令来获得当前的耗时命令日志,如:
`redis>SLOWLOG GET
-
- (integer) 4
- (integer) 1356806413
- (integer) 58
-
- "get"
- "foo"
-
- (integer) 3
- (integer) 1356806408
- (integer) 34
-
- "set"
- "foo"
- "bar"`
每条日志都由以下4个部分组成:
(1)该日志唯一ID;
(2)该命令执行的UNIX时间;
(3)该命令的耗时时间,单位是微秒;
(4)命令及其参数。
提示 为了产生一些耗时命令日志作为演示,这里将slowlog-log-slower-than参数值设置为O,即记录所有命令。如果设置为负数则会关闭耗时命令日志。
2.命令监控
Redis提供了MONITOR命令来监控Redis执行的所有命令,redis-cli同样支持这个命令,如在redis-cli中执行MONITOR:
redis>MONITOR OK
这时Redis执行的任何命令都会在redis-cli中打印出来,如我们打开另一个redis-cli执行SET foo bar命令,在之前的redis-cli中会输出如下内容:
1356806981.885237 [0 127.0.0.1:57339] "SET" "foo" "bar
MONITOR命令非常影响Redis的性能,一个客户端使用MONITOR命令会降低 Redis将近一半的负载能力。所以MONITOR命令只适合用来调试和纠错。
补充知识 Instagram① 团队开发了一个基于MONITOR命令的Redis查询分析程序redis-faina。redis-faina可以根据MONITOR命令的监控结果分析出最常用的命令、访问最频繁的键等信息,对了解Redis的使用情况帮助很大。
redis-faina的项目地址是https://github.com/Instagram/redis-faina,直接下载其中的redis-faina.py文件即可使用。
redis-faina.py的输入值为一段时间的MONITOR命令执行结果。例如:
redis-cli MONITOR | head -n <要分析的命令数> | ./redis-faina.py
37.2 phpRedisAdmin
当Redis中的键较多时,使用redis-cli管理数据并不是很方便,就如同管理MySQL时有人喜欢使用phpMyAdmin一样,Redis同样有一个PHP开发的网页端管理工具phpRedisAdmin。phpRedisAdmin支持以树形结构查看键列表,编辑键值,导入/导出数据库数据,查看数据库信息和查看键信息等功能。
1.安装phpRedisAdmin安装phpRedisAdmin的方法如下:
git clone https://github.com/ErikDubbelboer/phpRedisAdmin.gitcd phpRedisAdmin
phpRedisAdmin依赖PHP的Redis客户端Predis,所以还需要执行下面两个命令下载Predis:
git submodule initgit submodule update
2.配置数据库连接
下载完phpRedisAdmin后需要配置Redis的连接信息。默认phpRedisAdmin会连接到127.0.0.1,端口6379,如果需要更改或者添加数据库信息可以编辑includes文件夹中的config.inc. php文件。
3.使用phpRedisAdmin
安装PHP和Web服务器(如Nginx),并将phpRedisAdmin文件夹存放到网站目录中即可访问,如图7-3所示。
phpRedisAdmin自动将Redis的键以“:”分隔并用树形结构显示出来,十分直观。如post:1和post:2两个键都在post树中。
点击一个键后可以查看键的信息,包括键的类型、生存时间及键值,并且可以很方便地编辑。
4.性能
phpRedisAdmin在获取键列表时使用的是KEYS*命令,然后对所有的键使用TYPE命令来获取其数据类型,所以当键非常多的时候性能并不高(对于一个有一百万个键的Redis数据库,在一台普通个人计算机上使用KEYS*命令大约会花费几十毫秒)。由于Redis使用单线程处理命令,所以对生产环境下拥有大数据量的数据库来说不适宜使用phpRedisAdmin管理。
37.3 Rdbtools
Rdbtools是一个Redis的快照文件解析器,它可以根据快照文件导出JSON数据文件、分析Redis中每个键的占用空间情况等。Rdbtools是使用Python开发的,项目地址是https://github.com/sripathikrishnan/redis-rdb-tools。
1.安装Rdbtools
使用如下命令安装Rdbtools:
git clone https://github.com/sripathikrishnan/redis-rdb-toolscd redis-rdb-toolssudo python setup.py install
2.生成快照文件
如果没有启用RDB持久化,可以使用SAVE命令手动使Redis生成快照文件。
3.将快照导出为JSON格式
快照文件是二进制格式,不利于查看,可以使用Rdbtools来将其导出为JSON格式,命令如下:
rdb --command json /path/to/dump.rdb > output_filename.json
其中/path/to/dump.rdb是快照文件的路径,output_filename.json为要导出的文件路径。
4.生成空间使用情况报告
Rdbtools能够将快照文件中记录的每个键的存储情况导出为CSV文件,可以将该CSV文件导入到Excel等数据分析工具中分析来了解Redis的使用情况。命令如下:
rdb -c memory /path/to/dump.rdb > output_filename.csv
导出的CSV文件的字段及说明如表所示。
38.管理-Redis性能测试
语法
redis 性能测试的基本命令如下:
redis-benchmark [option] [option value]
实例
以下实例同时执行 10000 个请求来检测性能:
`redis-benchmark -n 10000
PING_INLINE: 141043.72 requests per second
PING_BULK: 142857.14 requests per second
SET: 141442.72 requests per second
GET: 145348.83 requests per second
INCR: 137362.64 requests per second
LPUSH: 145348.83 requests per second
LPOP: 146198.83 requests per second
SADD: 146198.83 requests per second
SPOP: 149253.73 requests per second
LPUSH (needed to benchmark LRANGE): 148588.42 requests per second
LRANGE_100 (first 100 elements): 58411.21 requests per second
LRANGE_300 (first 300 elements): 21195.42 requests per second
LRANGE_500 (first 450 elements): 14539.11 requests per second
LRANGE_600 (first 600 elements): 10504.20 requests per second
MSET (10 keys): 93283.58 requests per second`
redis 性能测试工具可选参数如下所示:
序号 选项 描述 默认值
1 -h 指定服务器主机名 127.0.0.1
2 -p 指定服务器端口 6379
3 -s 指定服务器 socket
4 -c 指定并发连接数 50
5 -n 指定请求数 10000
6 -d 以字节的形式指定 SET/GET 值的数据大小 2
7 -k 1=keep alive 0=reconnect 1
8 -r SET/GET/INCR 使用随机 key, SADD 使用随机值
9 -P 通过管道传输 请求 1
10 -q 强制退出 redis。仅显示 query/sec 值
11 --csv 以 CSV 格式输出
12 -l 生成循环,永久执行测试
13 -t 仅运行以逗号分隔的测试命令列表。
14 -I Idle 模式。仅打开 N 个 idle 连接并等待。
实例
以下实例我们使用了多个参数来测试 redis 性能:
`redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 10000 -q
SET: 146198.83 requests per second
LPUSH: 145560.41 requests per second`
以上实例中主机为 127.0.0.1,端口号为 6379,执行的命令为 set,lpush,请求数为 10000,通过 -q 参数让结果只显示每秒执行的请求数。
参考文档:
http://ifeve.com/redis-benchmarks/
http://www.runoob.com/redis/redis-benchmarks.html
39.管理-客户端连接
Redis 通过监听一个 TCP 端口或者 Unix socket 的方式来接收来自客户端的连接,当一个连接建立后,Redis 内部会进行以下一些操作:
- 首先,客户端 socket 会被设置为非阻塞模式,因为 Redis 在网络事件处理上采用的是非阻塞多路复用模型。
- 然后为这个 socket 设置 TCP_NODELAY 属性,禁用 Nagle 算法
- 然后创建一个可读的文件事件用于监听这个客户端 socket 的数据发送
最大连接数
在 Redis2.4 中,最大连接数是被直接硬编码在代码里面的,而在2.6版本中这个值变成可配置的。
maxclients的默认值是 10000,你也可以在 redis.conf 中对这个值进行修改。
`config get maxclients
- "maxclients"
- "10000"`
S.N. 命令 描述
1 CLIENT LIST 返回连接到 redis 服务的客户端列表
2 CLIENT SETNAME 设置当前连接的名称
3 CLIENT GETNAME 获取通过 CLIENT SETNAME 命令设置的服务名称
4 CLIENT PAUSE 挂起客户端连接,指定挂起的时间以毫秒计
5 CLIENT KILL 关闭客户端连接
40.管理-服务器
以下实例演示了如何获取 redis 服务器的统计信息:
`127.0.0.1:6379> INFO
Server
redis_version:3.0.7
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:d8d764d8bdb260a1
redis_mode:standalone
os:Linux 3.10.0-123.9.3.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.8.2
process_id:24865
run_id:6cb5ecae3a2035fbf4a0c8b539c5f2d28282b9eb
tcp_port:6379
uptime_in_seconds:128229
uptime_in_days:1
hz:10
lru_clock:15483518
config_file:
Clients
connected_clients:1
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
Memory
used_memory:816072
used_memory_human:796.95K
used_memory_rss:2527232
used_memory_peak:836920
used_memory_peak_human:81350K
used_memory_lua:36864
mem_fragmentation_ratio:3.10
mem_allocator:jemalloc-3.6.0
Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1458285243
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
Stats
total_connections_received:5
total_commands_processed:81
instantaneous_ops_per_sec:0
total_net_input_bytes:2549
total_net_output_bytes:5289
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
evicted_keys:0
keyspace_hits:36
keyspace_misses:4
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:182
migrate_cached_sockets:0
Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
CPU
used_cpu_sys:75.82
used_cpu_user:53.30
used_cpu_sys_children:0.00
used_cpu_user_children:0.00
Cluster
cluster_enabled:0
Keyspace
db0:keys=7,expires=0,avg_ttl=0`
下表列出了 redis 服务器的相关命令:
序号 命令及描述
1 BGREWRITEAOF 异步执行一个 AOF(AppendOnly File) 文件重写操作
2 BGSAVE 在后台异步保存当前数据库的数据到磁盘
3 CLIENT KILL [ip:port] [ID client-id] 关闭客户端连接
4 CLIENT LIST 获取连接到服务器的客户端连接列表
5 CLIENT GETNAME 获取连接的名称
6 CLIENT PAUSE timeout 在指定时间内终止运行来自客户端的命令
7 CLIENT SETNAME connection-name 设置当前连接的名称
8 CLUSTER SLOTS 获取集群节点的映射数组
9 COMMAND 获取 Redis 命令详情数组
10 COMMAND COUNT 获取 Redis 命令总数
11 COMMAND GETKEYS 获取给定命令的所有键
12 TIME 返回当前服务器时间
13 COMMAND INFO command-name [command-name ...] 获取指定 Redis 命令描述的数组
14 CONFIG GET parameter 获取指定配置参数的值
15 CONFIG REWRITE 对启动 Redis 服务器时所指定的 redis.conf 配置文件进行改写
16 CONFIG SET parameter value 修改 redis 配置参数,无需重启
17 CONFIG RESETSTAT 重置 INFO 命令中的某些统计数据
18 DBSIZE 返回当前数据库的 key 的数量
19 DEBUG OBJECT key 获取 key 的调试信息
20 DEBUG SEGFAULT 让 Redis 服务崩溃
21 FLUSHALL 删除所有数据库的所有key
22 FLUSHDB 删除当前数据库的所有key
23 INFO [section] 获取 Redis 服务器的各种信息和统计数值
24 LASTSAVE 返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 时间戳格式表示
25 MONITOR 实时打印出 Redis 服务器接收到的命令,调试用
26 ROLE 返回主从实例所属的角色
27 SAVE 异步保存数据到硬盘
28 SHUTDOWN [NOSAVE] [SAVE] 异步保存数据到硬盘,并关闭服务器
29 SLAVEOF host port 将当前服务器转变为指定服务器的从属服务器(slave server)
30 SLOWLOG subcommand [argument] 管理 redis 的慢日志
31 SYNC 用于复制功能(replication)的内部命令