
package ***** import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { //设置分布式的运行平台,和appname //使用Master运行平台,yarn,standalong(spark自带的运行平台),mesos,local四种 //local开发调试时用的环境,前三种一般为上线的运行环境 //local local[N] local[*] val conf = new SparkConf().setMaster("local[1]").setAppName("WordCount") //构建sparkContext对象 val sc = new SparkContext(conf) //加载数据源,获取RDD对象 val textFile = sc.textFile("C:\Users\zuizui\Desktop\README.txt") val counts = textFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_) counts.saveAsTextFile("C:\Users\zuizui\Desktop\result.txt") } }
例子为本地的路径
spark计算过程:
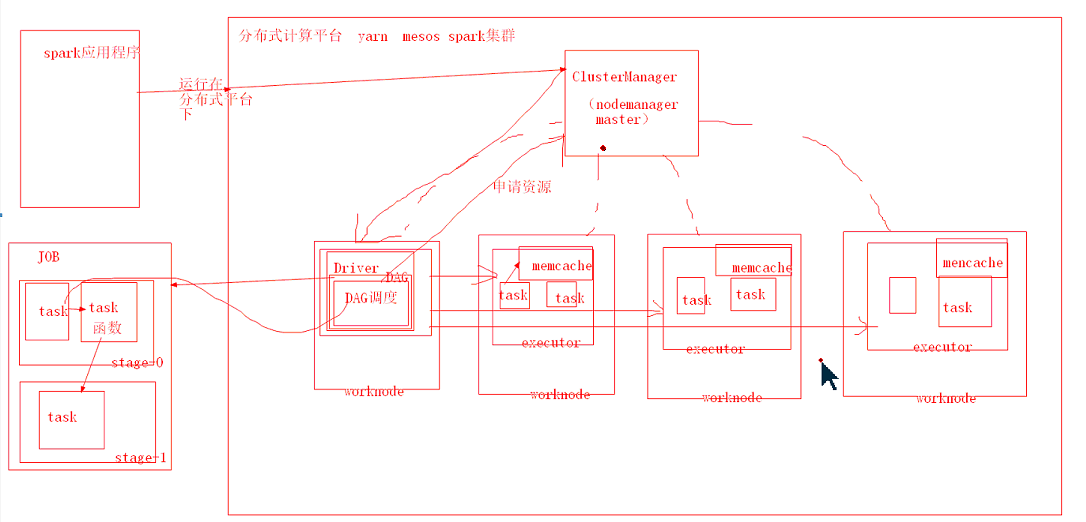
spark程序运行在分布式计算平台之上,Driver会生成一个DAG调度,就是job中的有向无环图,之后会向nodeManager申请资源,nodemanager会创建多个executor,driver中的DGA调度中的task会转移到executor上进行计算,
executor上的task的计算结果会保存在executor的memcache(内存)中,接着进行写一个task的计算,直到有一个task要写到磁盘上;