- 十进制数常用代码
十进制数常用代码有 8421BCD 码、余 3 码、格雷码等。编码原则是将十进制的 0~9 这 10 个基数字,每个都用 4 位的二进制码来代替所形成的代码,见表 1-30。

(1)8421BCD 码的形成
8421BCD 码是一种有权码,它将 4 位二进制码由左至右,即由高位到低位依次赋予 8、4、2、1,即
为权。
从一位的基数字与 8421BCD 码的对应关系看,与十进制数转换成二进制数是一样的。但是,若是两位的基数字就不是这种关系了。例如,32 所对应的编码为 00110010,显然不同于
。因此,人们把这种编码看成是一种假的二进制编码,又称二-十进制码。早年向计算机输入十进制数据大都采用这种编码,并将该码制作在纸带上通过光电设备读孔而完成数据输入。
(2)余 3 码的由来
在 8421BCD 码的基础上加上 3,即二进制的 0011 就得到了 10 个基数字所对应的余 3 码。例如,基数字 1 的 8421BCD 码为 0001,将 0001+0011=0100,就变成了余 3 码。虽然余 3 码是由 8421BCD 码变换而来,但是余 3 码确是一种无权码。
(3)格雷码的生成
格雷码是在二进制数的基础上通过运算而生成的一种代码。n 位长的二进制数可以生成相等位数的格雷码。从二进制数生成格雷码的原则是:“高位不动,(其他位)由本位与高位进行异或运算而产生”。异或运算法则为:相异为 1,否则(即相同)为 0。
- 字符常用代码 —— ASCII 码
ASCII 码是 American Standard Code for Information Interchange的缩写,中文的含义是美国信息交换标准代码,且被国际标准化组织认定成为国际通用的信息交换标准代码,并广泛用于PC中。该码为 7 位码,在计算机中占一个字节,共有 128 个。
该代码可分为控制用代码(33个)和可输出字符代码(95个)。分析该代码,可以得出许多用于信息处理、信息筛选的判据,见表 1-32。

通过对 ASCII 码的分析还可以得出字符变换的方法,见表 1-33。
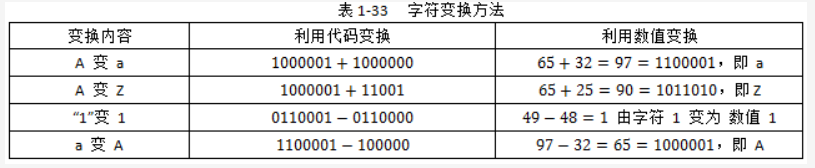
通过以上分析,说明 ASCII 码之间有着内在联系,记住主要的几个关键字符代码就可以推算出其他字符代码。
- 汉字代码
在计算机中使用汉字,可能说是一大创举。为了做到既便于汉字使用者使用,又便于计算机处理,在汉字处理全程中,按照不同的时段使用了几套编码,见表 1-34。

汉字由键盘输入后,首先得到的是表示按键位置的键扫描码,由该码经转换形成内码。
汉字的内码长度为 16 位,因此一个汉字需要占用两个字节的存储空间。汉字的形体一般用点阵来描写,点阵越多,汉字的形体越逼真,而占用的存储量也越大。
汉字在个人计算机(PC)中的处理过程如图 1-5 所示。

为了规范汉字在计算机中的使用,1981 年我国公布了《通讯用汉字字符集(基本集)及交换码标准》,简称 GB2312——80。在该标准中共收集了常用汉字 6763 个,其中包括一级汉字 3755 个,二级汉字 3008 个。此外还有符号及字母共同组成了该字符集。
为了在计算机中使用汉字的同时又能与 ASCII 码兼容,把区码和位码分别平移了一个常数 160。例如,区位码“0101”变为“161161”;区位码“9494”变为“254254”。这样所形成的编码作为汉字(及字符集中的其他字符)的内码。不难看出,汉字代码在计算机中每个字节的高位均为 1,而 ASCII 码为 7 位,字节的高位恒为 0。因此,汉字内码与 ASCII 码有明显区别。
- 信息代码校验方法
为了确保信息交换的准确无误,对信息代码实施校验是十分必要的。常用的校验方法有奇偶校验、海明校验、循环冗余校验等。
对信息代码进行校验是在原信息代码的基础上附加校验位,以增加代码的码距。为了提高编码效率,要求附加的校验位越少越好。但从校验功能上说,附加校验位少会使得检错和纠错能力降低。
1)奇偶校验
奇偶校验是在原信息代码的高位之前或低位之后加上一位奇校验码或偶校验码。按照在“一组代码里凑足奇数个 1”的原则所附加的校验位称为奇校验码;按照在“一组代码里凑足偶数个 1”的原则所附加的校验位称为偶校验码。
信息代码附加的校验位是由编码方程计算得出的,附加位附加到信息代码所生成的代码称为码字。码字经传递、交换后,用监督方程验证是否为码字,若是码字说明传递无误;若不是码字,说明传递出现了错误。值得注意的是,使用奇偶校验在传递中同时发生偶数个错误是发现不了的。
2)海明校验
海明校验是一种能够检查一位错误和纠正一位错误的校验方法。信息在交换之前先由编码方程对信息进行编码,信息交换后再由校验方程对收到的信息进行校验。如果算出的校验值为 0,说明信息传递无误;如果校验值不为 0,说明信息有误;若校验值等于 1,说明错误出在第 1 位;若校验值等于 n,说明错误出在第 n 位。纠正错误的方法是将错误所在处的代码取反。海明校验从编码到校验步骤如下。
①在 n 位的信息代码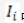
中,插入 m 个校验码 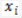
,m 的个数由下式计算:
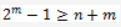
若 n = 4 ( 以 4 位信息代码为例 ),算得 m = 3,则在 4 位信息代码中需要插入 3 个校验码形成 7 位海明校验码。
②按照插入的校验码 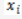
下标与海明码 H 小标的关系,即:

算出插入的校验码在海明码中的位置,并在海明码中排定插入的校验码。海明码中所剩余的位置按照“由低位到高位排列信息代码”的原则排列信息代码,从而构成 n + m 位的海明码。
③信息代码及插入的校验码在海明码中的位置排定后,下一步是利用已知的信息代码计算插入校验码的值,即生成海明码。根据校验码在海明码中的关联关系可以得出计算校验位之值的编码方程。
海明码经传递后,在接收一方可以进行海校验。海明校验是根据校验方程进行的。
④根据任一个校验位 x “自我异或”必为 0 的原理,即 x⊕x=0。
⑤检错与纠错试验。
3)循环冗余校验
循环冗余校验可以检查一位错误和纠正一位错误。循环冗余校验在编码时使用 3 个余数,在校验时又使用 3 个余数。循环冗余校验先由信息代码与生成代码按编码规则生成循环冗余码,也称为 CRC 码。若把 CRC 码表示为 CRC(7,4),其含义是 7 位长的 CRC 码,其中有 4 位是信息代码,而另外 3 位就是上面所说的编码所使用的余数。经编码生成的循环冗余码经传递接收后,再用生成代码去除所接收到的循环冗余码,又得到一个余数,这就是上面所说的第二个余数。若余数为 0,说明传递无误;若余数不为 0,则根据余数就可以得出出错的位置,将该位置处的代码取反则纠正了传递错误。下面是编码生成及校验的方法简介。
(1)循环冗余码生成
已知信息代码 n(x),将其左移 r 位,即 image,用一个约定的 r 次多项式去除image,得到余数 image,由 image,便得到循环冗余码。
在生成中有几点需要注意:
①左移位数 r 与约定多项式(即生成代码)的关系。若左移 3 位,就要用 4 位的生成代码,4 位的生成代码必然是 3 次的多项式。
②生成多项式的低次项必须为 1。
③相除时,被除数的高位为 1,则商 1,否则商 0。
④相减时对位相减不借位,即对位进行异或运算。
(2)校验方法
将接收到的循环冗余码再用编码时的生成多项式(即生成代码)去除,若余数为 0,则传递无误,若余数不为 0,则根据余数与错误位置的对应关系确定错误发生的位置。找到错误的位置后,将该位的代码值取反,则完成了纠错。
难点分析
- 汉字编码
(1)汉字的外码
目前用于汉字输入的外码有很多种,按照编码的特征可以归纳为以下几种类型。
①音码:以汉语拼音字母作为汉字的外码,称为音码。例如,汉字“王”,其外码为“WANG”。
②形码:以汉字的形体特征转换为按键组合作为汉字的外码,称为形码。五笔字型输入码就是形码的一种。汉字的形体编码有很多种,例如汉字形体的 4 个角,令“横为 1;竖为 2;点位 3;捺为 4……”,则“王”字的编码为 1121。
③音形码:利用汉字的发音及形体特征组合在一起进行编码,称为音形码。例如,“王”字的音码为 WANG,形码为 1121,则音形码为 W1121。使用音形码既可以避免“汪”、“王”在音码中的重音,又可以区分“玉”、“王”在形码中的同形。
④表形码:利用 26 个英文字母的形来表示汉字的形所生成的汉字编码,称为表形码。例如,把“叶”字中的“口”用 O 表示,把“叶”字中的“十”用 X 表示,则“叶”字的表形码为“OX”。照此规则,“可”字为“OT”,“订”字为“IT”。
⑤区位码:把汉字排成若干行,若干列。行为区,列为位。用每一个汉字所在行的序号及所在列的序号作为汉字输入码,称为区位码。例如,“啊”字在 16 行(区),01 列(位),则“啊”字的区位码为 1601。每个汉字对应一个 4 位的区位码,没有重码的问题。
区位码是根据 1981 年我国公布的通讯用汉字字符集基本集 GB2312——80 中包含的汉字及字符排列成 94 个区,94 个位,总计容量为 94 X 94 = 8836 个。
由字符集的区位结构可以看出:01~09 区为符号及字母;10~15 区为自定义符号区;16~55区为以汉语拼音为序的一级汉字,共有 3755 个。所谓一级汉字,是指使用频率高的汉字;56~87 区为以部首排序的二级汉字,共有 3008 个;88~94 区为提供给用户的自定义汉字空间。
在整个字符集中,收入的汉字及符号共 8000 多个,除空白备用区没有放入字符外,还有一个区中未放满 94 个汉字或字符的情况。如此众多的汉字和字符,在输入中记住每一个成员的区、位号并不是一件容易的事。
这种编排的区位码已列为国家标准,所以区位码也称国标区位码。
(2)汉字的内码
汉字在计算机内存储、交换、处理的编码,称为汉字的内码。汉字的内码是在国标区位码、国标码的基础上,根据实用上的需要而形成的一种编码。
汉字的内码长度为 16 位,每一个汉字占两个字节。这种内码是怎样形成的呢?还得从国标区位码说起。国标区位码是汉字的外码,如果将其也作为汉字的内码就可以使汉字的内、外码统一为一种编码。但是,由于直接使用区位码作为汉字的内码会造成与西文 ASCII 码的冲突,考虑到汉字兼容性而没有区位码作内码。
国标码是在国标区位码的基础上,分别将“区号 + 32”、“位号 + 32”而形成的一种编码。
使用国标码作为汉字的内码在实用中也有不协调之处,国标码的最大编码 126 | 126 在计算机中每个字节也只是个 7 位码:0111 | 1110 | 0111 | 1110,而西文的 ACSII 码也是 7 位码。这样,在计算机中当以字节为单位处理代码时,就不好辨认究竟是 ASCII 码,还是汉字一个字节的代码。因此,国标码也没有直接作为汉字的内码。
为了在计算机中把汉字内码与 7 位的 ASCII 码明显地区分出来,汉字内码在国标码的基础上将每个字节的高位都由 0 变为 1,这样所形成的汉字内码就成了每个字节都是高位为 1 的 8 位码,而这个高位 1 对一个字节来说,其值为 128.到此为止,分析了从国标区位码生成国标码,再由国标码生成汉字内码的过程。
国标区位码、国标码、汉字内码三者之间的关系是:区位码的区和位分别加上 32,则形成了国标码;国标码的第一、第二字节分别加上 128,则形成了汉字内码;区位码的区和位分别加上 160,就得到了汉字内码。
(3)汉字的字形码
表示汉字形体的代码,称为汉字的字形码。GB2312——80 字符集里的任何一个汉字或字符、如需要显示或打印输出,必须借助字形码。字形码是由表示汉字形体的点阵转换而来的一组 0、1 代码,而汉字的点阵是汉字的形体在一个矩形区域内被离散化后所形成的点的阵列。
离散汉字的点阵越密,表达的汉字形体越逼真,而所占用的存储空间越多。一般点阵的规格为:简易型 16 X 16 点阵;普及型 24 X 24 点阵;提高型 32 X 32 点阵;精密型 48 X 48 点阵。
汉字的字型码是 0、1 的矩阵码。当显示汉字时,用字形码去激发显示器的像素,代码为 1 时使像素发亮,代码为 0 时像素不亮,这样就把一个汉字显现在显示器上。打印汉字时,字形码 1 出笔画,字形码 0 不出笔画,于是汉字被打印输出出来。通常处理汉字是预先把每个汉字的字形码编号,汇集成一个汉字(字形编码)库,需要时由汉字外码转换成内码,再由内码去查找汉字库,调出字形码后进行汉字输出。
输出西文的字母、符号,也需要该过程。
- 奇偶校验码
(1)编码概述
在计算机中不论是哪种信息代码都是 0 和 1 的组合,而在一组代码中所包含 1 的个数不是奇数就是偶数,奇偶校验就是根据这个事实而建立起来的一种校验方法。奇偶校验分为奇校验和偶校验。奇校验是按照奇数个 1 为基准进行编码奇校验的,偶校验时按照偶数个 1 为基准进行编码和校验的。由于实施奇偶校验较为方便,且编码效率较高,所以它是一种广为采用的校验方法。
(2)编码方法
奇偶校验码是在 n 位的信息代码上附加一个校验位而构成的一种编码,所以编码效率为 n / (n + 1 ) 。附加的校验位可以设置在一组信息代码的面前,也可以设置在其后。
①奇校验码:在 n 位的信息代码上附加一个校验码,使其成为奇数个 1。附加的校验码 x,按下式计算:
image
式中,⊕ 为异或运算符,运算法则是:“相异为 1,否则为 0”。
②偶校验码:在 n 位的信息代码上附加一个校验码,使其成为偶数个 1。附加的校验码 x,按下式计算:
image
式中,⊕ 为异或运算符。
(3)校验方法
奇偶校验是在接收端用监督方程式检验接收码,监督方程分别如下。
①奇校验监督方程为:
image
将接收到的奇校验码带入该方程,如果其值等于1,表示交换无误,否则表示有错。但应该指出,如果同时发生两位或偶数个错误代入方程也会产生其值为 1 的结果。
②偶校验监督方程为:
image
将接收到的偶校验码代入该方程,如果其值等于 0,表示交换无误,否则表示有错。但若同时发生两位及以上偶数个错误,校验就将失灵。
(4)实用形式
①水平校验:按行设置校验码的编码形式,称为水平校验码。
②垂直校验:按列设置校验码的编码形式,称为垂直校验码。
③水平、垂直双重校验:按行、按列分别设置校验码的编码形式,称为水平、垂直双重校验码。
利用水平、垂直双重校验既可以检查出一位错误,还可以纠正一位错误。
- 海明码(Hamming code)
(1)编码概述
海明码是 1950 年由贝尔实验室的海明(Richard Hamming)提出,能够检查并纠正一位错误的编码。海明码是由信息代码(如 ASCII 码、汉字编码)按照规定,插入校验码而形成的。海明码经交换后可用监督关系式计算其值,若结果为 0,说明传递无错;若结果不为 0,说明传递有错。若结果为 1,说明错在第 1 位;若结果为 2,说明错在第 2 位;以此类推。纠正错误的方法是将错误所在位的值取反(0 变 1,1 变 0)。
(2)编码组成
海明码是在 n 位的信息代码之间插入 m 个校验码组成的,当信息代码长度确定后,第一要由信息代码长度 n 计算出所需插入的校验码个数 m;第二是排列信息代码与校验码的位置。
(3)编码生成
在海明码中包括已知的信息代码和未知的校验码,当信息代码和插入的校验码位置排定后,生成海明码的任务就是计算所插入的校验码的值。从海明校验的原理来说,它也是利用编码的奇偶特性,并把这种特性集中在校验码上。具体地说,校验码的值是根据被校验的信息代码的奇偶性而确定的。(P94)
(4)编码实例
(5)校验方法
海明码的校验是通过校验方程,也称监督方程实施的。在海明码的编码中,借助校验位与被校验位之间的奇偶性得出了编码方程,而校验方程的建立也是利用编码之间的奇偶性。(P96)
- 循环冗余码
(1)编码概述
循环冗余码也称 CRC 码(Cyclic Redundancy Code),又称多项式码,是一种在计算机网络和数据通信中被广泛采用的校验码。
循环冗余码,顾名思义,它既是一种具有循环特点的编码,又是一种与冗余相关的编码。关于循环的特点是指,对一个循环冗余码进行循环移位所形成的编码仍热是一个循环冗余码。关于冗余的特点是指,在形成循环冗余码时利用了一个余数。
循环冗余码是在信息代码后面附加上冗余位而形成的。若把循环冗余码表示为(7,4),说明循环冗余码长度为 7 位,信息代码为 4 位,而附加的冗余位为 7 – 4 = 3 位。
由信息代码生成循环冗余码,在对信息代码操作的同时,还需要一个特定的已知代码,这个代码叫生成代码,也叫生成多项式。为什么把一个已知的生成代码称为生成多项式呢?这是因为任何一个二进制数或二进制形式的代码都可以用一个多项式来表示。
(2)编码方法
为了直观地理解循环冗余码的编码方法,先用一个编码实例展示一下该编码的形成过程。(P100)
(3)编码实例(P101)
(4)校验方法
对接收到的循环冗余码进行校验,还需要借助编码时使用过的生成多项式。用生成多项式去除接收到的循环冗余码,若余数为 0,说明传递无误,这个原则是在编码时就早已设定好的。若相除余数不为 0,则说明接收到的循环冗余码有错误,而确定错误出现的位置只与使用的生成多项式有关。