https://zhuanlan.zhihu.com/p/336793481
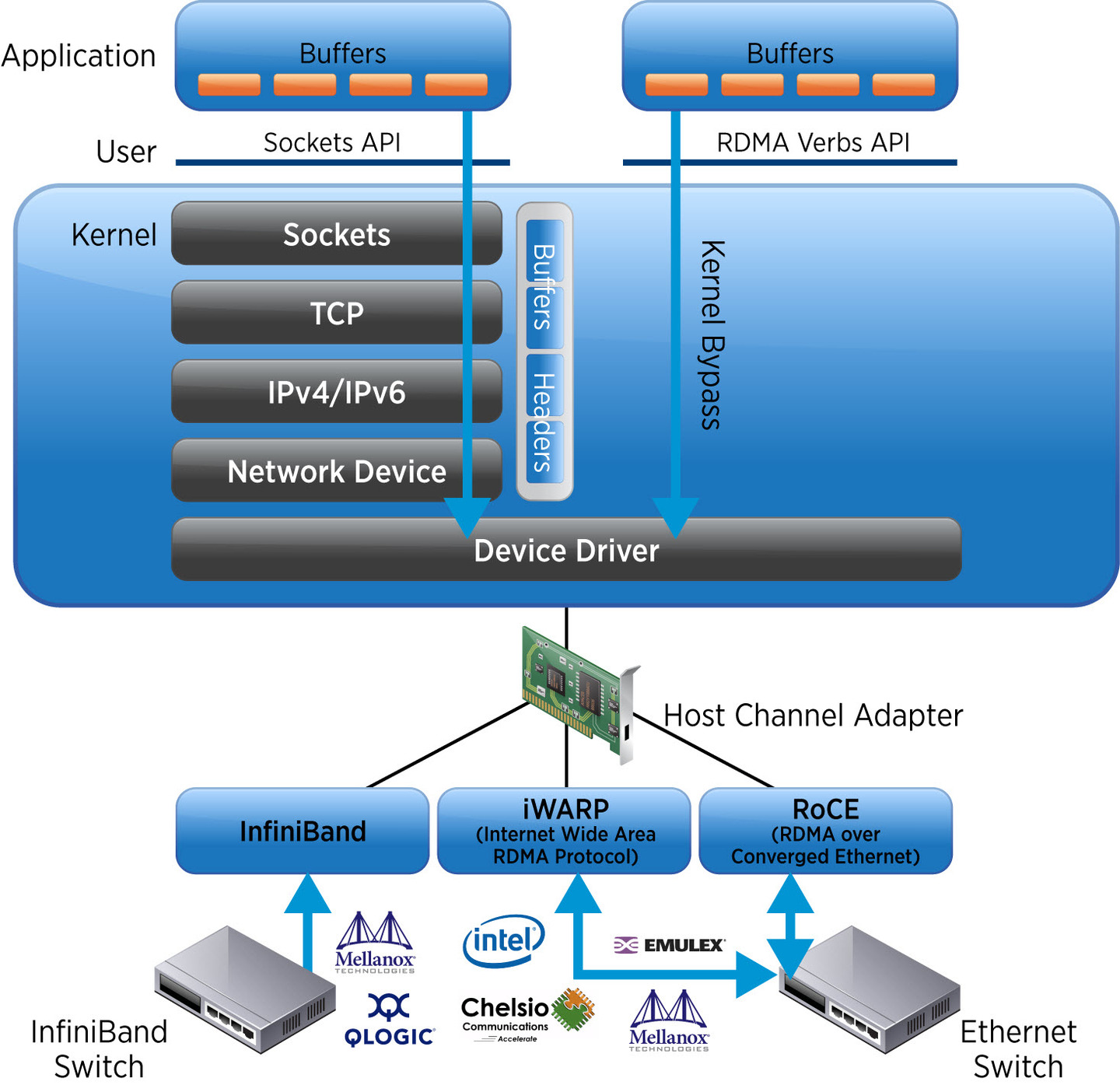
简介
Remote
- data transfers between nodes in a network
Direct
- no Operating System Kernel involvement in transfers
- everything about a transfer offloaded onto Interface Card
Memory
- transfers between user space application virtual memory
- no extra copying or buffering
Access
- send, receive, read, write, atomic operations
- RDMA通过专有的RDMA网卡RNIC,绕过内核直接从用户空间访问
RDMA enabled NIC网卡。
- 要运行RDMA,除了加载mlx5_core,还有其他模块
mlx5_ib,ib_core,ib_ucm,rdma_core - RDMA is a method of accessing memory on a remote system without interrupting the processing of the CPU(s) on that system. -- RDMA over Commodity Ethernet at Scale
rdma和普通的tcp/ip有什么不同
- zero copy – data transferred directly from virtual memory on one node to virtual memory on another node
- kernel bypass – no operating system involvement during data transfers
- asynchronous operation – threads not blocked during I/O transfers
- tcp网络收发的过程,涉及了多个队列和缓冲区。
- rdma链路免拷贝,但是要提前申请内存(pin住内存)
tcp网络收发过程涉及的缓冲区
- 网卡收发网络包时,通过 DMA 方式交互的环形缓冲区;
- 网卡中断处理程序为网络帧分配的,内核数据结构 sk_buff 缓冲区;
- 应用程序通过套接字接口,与网络协议栈交互时的套接字缓冲区。
名词
OFED:目前的理解是OFED实现的是RDMA编程的接口层(编程库),底层的协议栈是靠别的团队完成的。libibverbs和librdmacm库:libibverbsis a library that allows userspace processes to use RDMA "verbs" as described in the InfiniBand Architecture Specification and the RDMA Protocol Verbs Specification. 其中librdmacm在libibverbs上封装了一层Roce v1:ib 二层Roce v2:udp 三层rc:reliable connectionuc:unreliable connection
RDMA操作细节
- RDMA提供了基于消息队列的点对点通信,每个应用都可以直接获取自己的消息,无需操作系统和协议栈的介入。
- 消息服务建立在通信双方本端和远端应用之间创建的
Channel-IO连接之上。当应用需要通信时,就会创建一条Channel连接,每条Channel的首尾端点是两对Queue Pairs(QP)。每对QP由Send Queue(SQ)和Receive Queue(RQ)构成,这些队列中管理着各种类型的消息。QP会被映射到应用的虚拟地址空间,使得应用直接通过它访问RNIC网卡。除了QP描述的两种基本队列之外,RDMA还提供一种队列Complete Queue(CQ),CQ用来知会用户WQ上的消息已经被处理完。 - RDMA提供了一套软件传输接口,方便用户创建传输请求
Work Request(WR),WR中描述了应用希望传输到Channel对端的消息内容,WR通知QP中的某个队列Work Queue(WQ)。在WQ中,用户的WR被转化为Work Queue Element(WQE)的格式,等待RNIC的异步调度解析,并从WQE指向的Buffer中拿到真正的消息发送到Channel对端。
RDAM单边操作 (RDMA READ)
READ和WRITE是单边操作,只需要本端明确信息的源和目的地址(在建立连接的前提下),远端应用不必感知此次通信,数据的读或写都通过RDMA在RNIC与应用Buffer之间完成,再由远端RNIC封装成消息返回到本端。
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先A、B建立连接,QP已经创建并且初始化。
- 数据被存档在B的buffer地址VB,注意VB应该提前注册到B的RNIC (并且它是一个Memory Region) ,并拿到返回的local key,相当于RDMA操作这块buffer的权限。
- B把数据地址VB,key封装到专用的报文传送到A,这相当于B把数据buffer的操作权交给了A。同时B在它的WQ中注册进一个WR,以用于接收数据传输的A返回的状态。
- A在收到B的送过来的数据VB和R_key后,RNIC会把它们连同自身存储地址VA到封装RDMA READ请求,将这个消息请求发送给B,这个过程A、B两端不需要任何软件参与,就可以将B的数据存储到A的VA虚拟地址。
- A在存储完成后,会向B返回整个数据传输的状态信息。
单边操作传输方式是RDMA与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用的参与其中,这种方式适用于批量数据传输。
RDMA 单边操作 (RDMA WRITE)
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先A、B建立连接,QP已经创建并且初始化。
- 数据remote目标存储buffer地址VB,注意VB应该提前注册到B的RNIC(并且它是一个Memory Region),并拿到返回的local key,相当于RDMA操作这块buffer的权限。
- B把数据地址VB,key封装到专用的报文传送到A,这相当于B把数据buffer的操作权交给了A。同时B在它的WQ中注册进一个WR,以用于接收数据传输的A返回的状态。
- A在收到B的送过来的数据VB和R_key后,RNIC会把它们连同自身发送地址VA到封装RDMA WRITE请求,这个过程A、B两端不需要任何软件参与,就可以将A的数据发送到B的VB虚拟地址。
- A在发送数据完成后,会向B返回整个数据传输的状态信息。
单边操作传输方式是RDMA与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用的参与其中,这种方式适用于批量数据传输。
read/write不会消耗srq
RDMA 双边操作 (RDMA SEND/RECEIVE)
RDMA中SEND/RECEIVE是双边操作,即必须要远端的应用感知参与才能完成收发。在实际中,SEND/RECEIVE多用于连接控制类报文,而数据报文多是通过READ/WRITE来完成的。
对于双边操作为例,主机A向主机B(下面简称A、B)发送数据的流程如下:
- 首先,A和B都要创建并初始化好各自的QP,CQ
- A和B分别向自己的WQ中注册WQE,对于A,WQ=SQ,WQE描述指向一个等到被发送的数据;对于B,WQ=RQ,WQE描述指向一块用于存储数据的Buffer。
- A的RNIC异步调度轮到A的WQE,解析到这是一个SEND消息,从Buffer中直接向B发出数据。数据流到达B的RNIC后,B的WQE被消耗,并把数据直接存储到WQE指向的存储位置。
- AB通信完成后,A的CQ中会产生一个完成消息CQE表示发送完成。与此同时,B的CQ中也会产生一个完成消息表示接收完成。每个WQ中WQE的处理完成都会产生一个CQE。
双边操作与传统网络的底层Buffer Pool类似,收发双方的参与过程并无差别,区别在零拷贝、Kernel Bypass,实际上对于RDMA,这是一种复杂的消息传输模式,多用于传输短的控制消息。
编程步骤
- 打开设备
ibv_open_device - 申请protect-domain
ibv_alloc_pd ibv_alloc_pdcreates a protection domain (PD). PDs limit which memory regions can be accessed by which queue pairs (QP) providing a degree of protection from unauthorized access.- 注册内存
ibv_reg_mr - 通过上一步申请的pd,注册内存,同时规定使用权限,不同的pd可以访问同一块mr,内存可以使用一片mmap出的内存区域,也可以是
spdk_zmalloc申请出的大页内存 - 同时这个命令也申请出了lkey,rkey
- 可是使用任何类型的内存
- 创建Complete Queue
ibv_create_cq, - 多个qp可以共用一个cq,sending和receiving也可以共用一个cq
- 默认是polling模式,也可以配置参数
ibv_comp_channel配制成事件通知的模式 - 创建shared receive queue
ibv_create_srq - 申请出的srq会被
ibv_post_srq_recv调用 - 多个qp共用一个srq
- 创建queue-pair
ibv_create_qp - 创建新的qp,会关联cq,srq
- init/ready to receive/ready to send (modify_qp)
- 放置receive buffer
ibv_post_srq_recv - 把一系列的wr放到srq中
- 接收消息的时候才要用到,因为接收方需要开辟内存放置收到的信息
- 客户端发送消息过来的时候会占用一个当前空闲的wr,如果当前srq中没有空闲的wr了,发送端会报错
- 交换qp信息,建立连接
- 发送
ibv_post_send - poll cq
ibv_poll_cq
参考链接
- 深入浅出全面解析RDMA
- 使用RDMA ibverbs 编程
- RDMA学习路线总结
- nvme-rdma需要使用OFDE选项with-nvmf
- HowTo Compile MLNX_OFED for Different Linux Kernel Distribution
- MLNX_OFED Documentation Rev 5.0-2.1.8.0 pdf
- Mellanox Linux Driver Modules Relationship (MLNX_OFED)
- 华为云部署全球首个PFC-Free的RDMA网络HUAWEI CurreNET
- 两种以太网 RDMA 协议: iWARP 和 RoCE
- OpenVSwitch 硬件加速浅谈 ovs hw-offload
- OVS Offload Using ASAP2 Direct 裸金属实际上还是虚拟机
- Raw Ethernet Programming: Packet Pacing - Code Example
- RDMA read and write with IB verbs 写的很好,还有例程
- RoCE Debug Flow for Linux看不懂
- RDMA技术详解看过了,挺好的
- Understanding mlx5 Linux Counters and Status Parameters比如/sys/class/infiniband/mlx5_bond_0/ports/1/hw_counters/np_cnp_sent和 /sys/class/infiniband/mlx5_bond_0/ports/1/hw_counters/np_ecn_marked_roce_packets
- TCP中ECN详细工作机制讲解一
- RDMA/RoCE Solutionsmlx一系列的文章
- mlnx_qos
- ibv_post_send() RDMAmojo
- ibv_create_qp()
- Connecting Queue Pairs
- ibv_modify_qp()
- Revisiting Network Support for RDMA - Extended version of the SIGCOMM 2018 paper论文挺好的,很多基本概念也有,比如NACK: negative acknowledgement
- RDMA over Commodity Ethernet at Scale SIGCOMM 2016 paperguochuanxiong的论文
- Congestion Control for Large-Scale RDMA deployments 2015 sigcomm,首篇提到DCQCN的论文
- Verbs programming tutorial
- Priority Flow Control (PFC)
- 7.7. USING CHANNEL BONDING讲bonding redhat真的是有很多不错的文章
- [RoCE]拥塞控制机制(ECN, DC-QCN) ecn标记有它的不足之处,如果qpair很多,而ecn又是随机标记的,会导致有些qpair标记不到,导致单凭ecn无法避免拥塞
- VLAN 基础知识
- 数据中心网络监控小结pingmesh