1.
软硬件环境
- CentOS 7.2 64 位
- OpenJDK- 1.8
- Hadoop- 2.7
2.
安装SSH客户端
-
安装SSH安装SSH:

安装完成后,可以使用下面命令进行测试:

输入 root 账户的密码,如果可以正常登录,则说明SSH安装没有问题。
3.安装java环境
安装 JDK
使用 yum 来安装1.7版本 OpenJDK:

安装完成后,输入
java和javac命令,如果能输出对应的命令帮助,则表明jdk已正确安装。配置 JAVA 环境变量
执行命令:编辑 ~/.bashrc,在结尾追加:
保存文件后执行下面命令使 JAVA_HOME 环境变量生效:

为了检测系统中 JAVA 环境是否已经正确配置并生效,可以分别执行下面命令:

若两条命令输出的结果一致,且都为我们前面安装的 openjdk-1.8.0 的版本,则表明 JDK 环境已经正确安装并配置。
4.安装hadoop
下载 Hadoop
本教程使用 hadoop-2.7 版本,使用 wget 工具在线下载
安装 Hadoop
将 Hadoop 安装到 /usr/local 目录下:
对安装的目录进行重命名,便于后续操作方便:

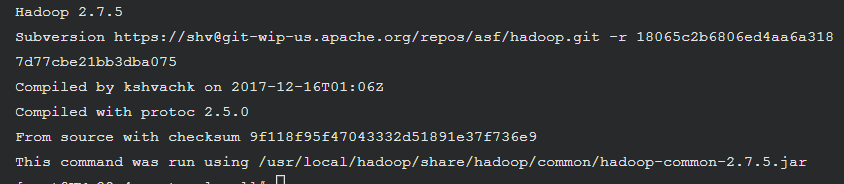
检查Hadoop是否已经正确安装:

如果成功输出hadoop的版本信息,表明hadoop已经成功安装。
5.hadoop伪分布式环境配置
设置 Hadoop 的环境变量

使Hadoop环境变量配置生效:

修改 Hadoop 的配置文件
Hadoop的配置文件位于安装目录的 /etc/hadoop 目录下,在本教程中即位于 /url/local/hadoop/etc/hadoop 目录下,需要修改的配置文件为如下两个:
编辑 core-site.xml,修改
<configuration></configuration>节点的内容为如下所示: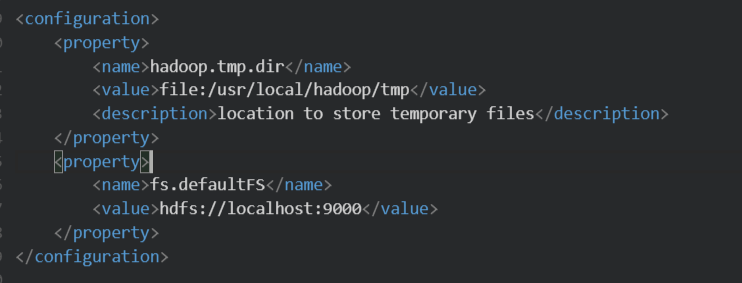
同理,编辑 hdfs-site.xml,修改
<configuration></configuration>节点的内容为如下所示:
格式化 NameNode
格式化NameNode:
在输出信息中看到如下信息,则表示格式化成功:

启动 NameNode 和 DataNode 守护进程
启动 NameNode 和 DataNode 进程:
执行过程中会提示输入用户密码,输入 root 用户密码即可。另外,启动时ssh会显示警告提示是否继续连接,输入 yes 即可。

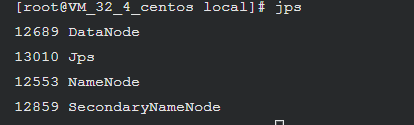
检查 NameNode 和 DataNode 是否正常启动:

如果NameNode和DataNode已经正常启动,会显示NameNode、DataNode和SecondaryNameNode的进程信息:
6.运行伪分布式实例
查看 Hadoop 自带的例子
Hadoop 附带了丰富的例子, 执行下面命令可以查看:


在 HDFS 中创建用户目录
在 HDFS 中创建用户目录 hadoop:
准备实验数据
本教程中,我们将以 Hadoop 所有的 xml 配置文件作为输入数据来完成实验。执行下面命令在 HDFS 中新建一个 input 文件夹并将 hadoop 配置文件上传到该文件夹下:
此时会出现如下警告:

原因:
Apache提供的hadoop本地库是32位的,而在64位的服务器上就会有问题,因此需要自己编译64位的版本。1、首先找到对应自己hadoop版本的64位的lib包,可以自己手动去编译,但比较麻烦,也可以去网上找,好多都有已经编译好了的。
2、可以去网站:http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 下载对应的编译版本
3、将准备好的64位的lib包解压到已经安装好的hadoop安装目录的lib/native 和 lib目录下:




4、然后增加环境变量:

5、增加下面的内容:

6、让环境变量生效

7、自检hadoop checknative –a 指令检查
再次在 HDFS 中创建用户目录 hadoop:

不再提示警告
准备实验数据
本教程中,我们将以 Hadoop 所有的 xml 配置文件作为输入数据来完成实验。执行下面命令在 HDFS 中新建一个 input 文件夹并将 hadoop 配置文件上传到该文件夹下:
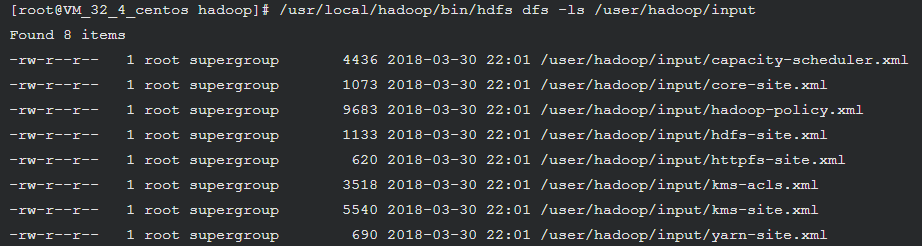
使用下面命令可以查看刚刚上传到 HDFS 的文件:
运行实验


上述命令以 HDFS 文件系统中的 input 为输入数据来运行 Hadoop 自带的 grep 程序,提取其中符合正则表达式 dfs[a-z.]+ 的数据并进行次数统计,将结果输出到 HDFS 文件系统的 output 文件夹下。
查看运行结果
上述例子完成后的结果保存在 HDFS 中,通过下面命令查看结果:
如果运行成功,可以看到如下结果:

删除 HDFS 中的结果目录:

运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录不能存在,否则会提示错误,因此在下次运行前需要先删除输出目录。
关闭 Hadoop 进程
关闭 Hadoop 进程:
再起启动只需要执行下面命令:

7.
部署完成