三次作业设计分析
第一次作业
类图:

第一次作业思路:在第一次作业中有三个类,入口函数是CalPoly,读取参数、进行求导、输出。在第一次作业中模仿课堂上机矩阵运算的形式,在Poly类中进行各种运算,检查格式正确性、分离项、指数系数分离、化简等等。Poly是由Polyitem构成,求导过程在因子层面进行。
优缺点分析:
优点:第一次作业中能够从表达式-项-因子层面进行思考,在判断方面采用正则表达式进行分析,虽然是正则表达式,但是每个因子从小到大分开写,再合并增强可读性。
缺点:作业不写注释,当我在互测过程中看到不写注释的代码,如果说不是特别认真看的话确实比较费力;readme.md文档也没有两句话,这是编程陋习。其次是类有点少、没有InputHandle单独处理输入结构,检查格式是否正确放在Poly类中不太合适,分离指数系数也不是Poly类应该做的事儿,当时没有考虑到构造形式可以多样化,因此代码糅杂在一块。判断格式时采用大正则判断,不太合适。互测过程中看到用Pattern、matcher和group的方法,值得学习。
度量分析:采用IDEA自带插件Metrics
方法复杂度:
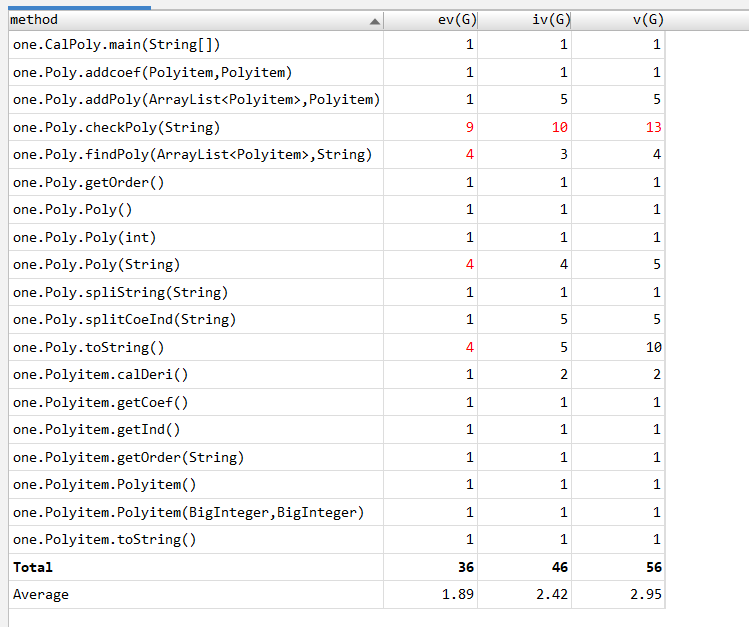
之所以checkPoly复杂度如此高,重要原因是当时我判断 全部字符属于合法字符采取循环判断模式,没有用到正则表达式,之后判断是否合法就采取正则表达式的方法了。
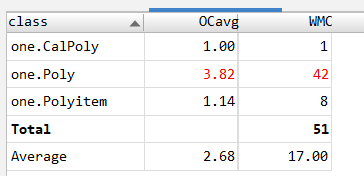
类复杂度:

第二次作业
类图:
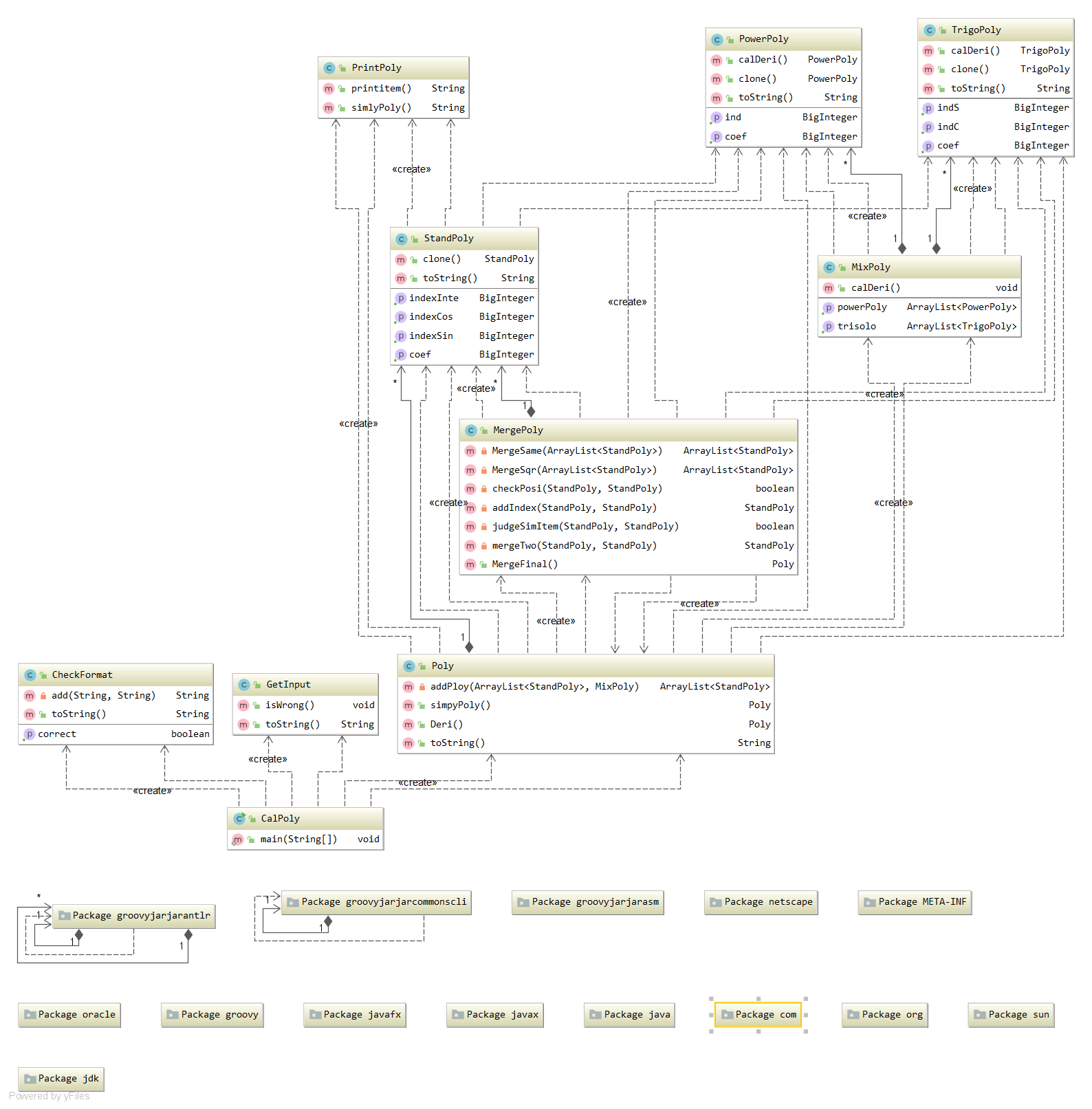
类复杂度:
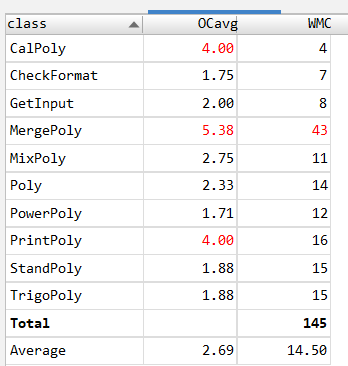
MergePoly类复杂度过高,详细情况如下:
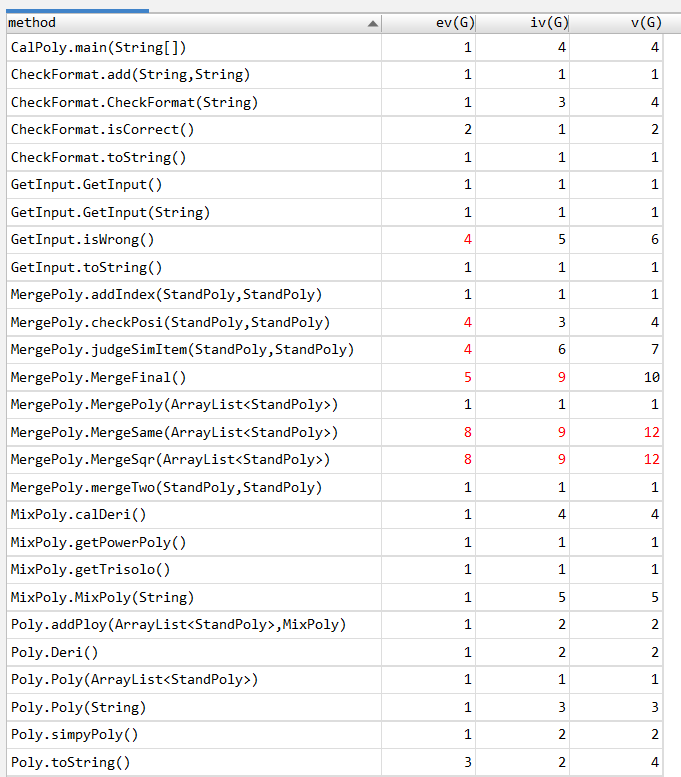
第二次作业思路:因子-项-表达式,但是实现过程中由于项建立的对象是链表,导致我重新建立一个StandPoly的类,里面存取的是一项的系数和三个指数。
优缺点分析:
优点:本次作业有GetInput类,单独处理输入,检查格式类别也已分开,代码中有注释,readme也对自己每个类各个方法进行说明。正则表达式引入Pattern和Matcher进行匹配,同时利用Group进行分离,很容易提取指数和系数。
缺点:但是到第三次作业我才发现自己理解有问题,还是在入口函数进行读取字符串,传给GetInput类是字符串,只是单纯建立一个输入类别,没有真正达到效果。在类中数据类型没有考虑好,导致进行求导的过程中得转化为另一个标准项类,造成代码冗杂。在化简中漏掉 cos(x) ^ 2 = 1 - sin(x) ^ 2。
第三次作业
类图:
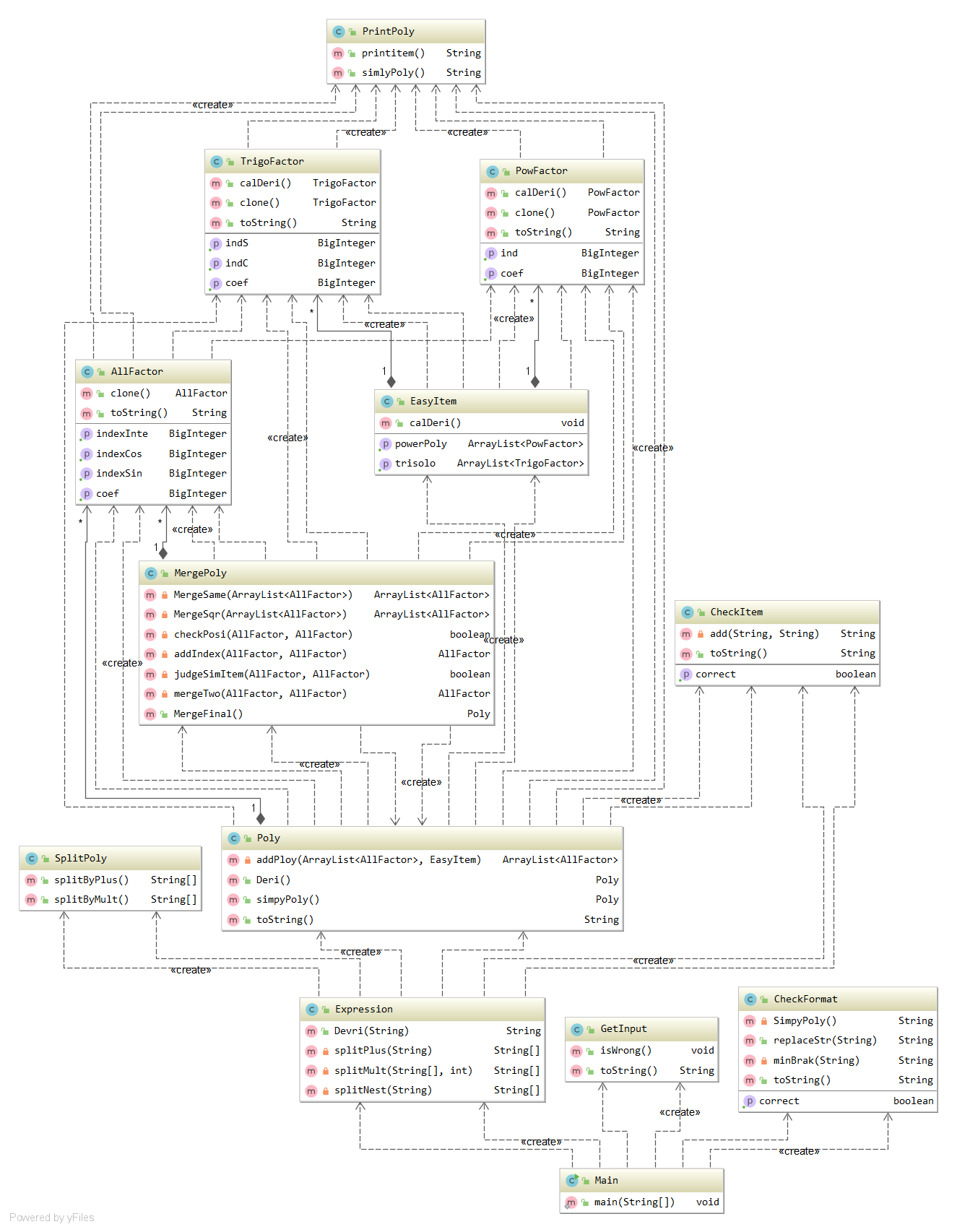
度量分析图:
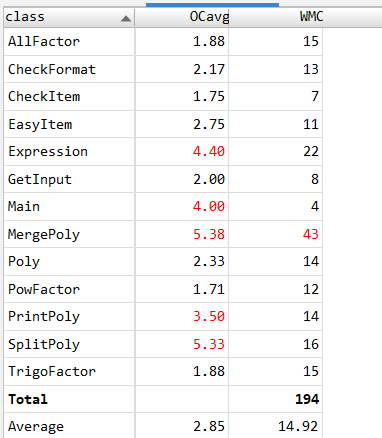
第三次作业思路:
由于短时间内担心无法用好接口和继承,本次作业沿用第二次作业,类基本一致,增加Expression类别进行递归求导,求导的终止条件是判断表达式是作业2中的表达式;CheckFormat类对格式进行判断;SplitPoly类对项进行分离。
优缺点分析:
优点:第三次作业没什么优点。
缺点:由于是沿用第二次作业,因此类别依旧冗杂,没有用到接口,递归下降应该是一个比较好的思路,战略性放弃了。没有花时间进行化简,输出很长。
三次作业总结
三次作业让我从正则表达式小白逐渐成长,从大正则到利用matcher和group进行分步判断最后迫于不会用递归下降法而再次使用大正则,确实让我在一次次debug中学到很多东西,同时仍尚存很多疑惑。通过作业迫使我不断思考该如何构建自己的程序,实现可移植性、可修改性等等。而面向对象,我在第二次作业中感到自己简直是在面向过程,思考求导我应该做什么,分离-求导-化简合并-输出。甚至类别二都是如此,比如单独类别用来进行化简,修改层面确实比较合适,但是是否真正是从对象进行考虑,我不太清楚。对于代码风格,命名上时常感到词穷,无法直观从命名上看出变量的作用,这也是需要锻炼的。
分析自己程序中的Bug
在第一次作业中,公测和互测均未发现Bug。
第二次作业中,虽然强测中没有发现问题,但是互测中同学给我指出问题,我发现在除去多于正负号的时候,我是采取如下方式:
String strSimpOp1 = strDetWhi.replaceAll("([+]{2})|([-]{2})", "\+");
strSimpOp1 = strSimpOp1.replaceAll("([+]{2})|([-]{2})", "\-");
String strSimOp2 = strSimpOp1.replaceAll("(\+\-)|(\-\+)", "\+");
strSimOp2 = strSimOp2.replaceAll("(\+\-)|(\-\+)", "\-");
可以发现如果出现+-+的情况其实是没有完全进行化简的,而且我发现自己的程序竟然没有抛出异常,而是进行错误的计算。后来我采取其他同学提供的建议,重新调整替换顺序,得到正确化简形式。即如下代码:
String strSimpOp1 = strDetWhi.replaceAll("([+]{2})|([-]{2})", "\+");
strSimpOp1 = strSimpOp1.replaceAll("(\+\-)|(\-\+)", "\-");
String strSimOp2 = strSimpOp1.replaceAll("([+]{2})|([-]{2})", "\+");
strSimOp2 = strSimOp2.replaceAll("(\+\-)|(\-\+)", "\-");
同时这也告诉我在课下测试中应该对自己的程序有较强的测试,在第一次oo分享课中同学谈道对自己代码进行逐行解释,我认为这虽然比较耗时间但是确实能对自己的代码全面分析找bug。
第三次作业就比较有意思,傍晚6点开放互测窗口,最初两小时我因为x ^ 10000*x ^ 10000的数据被hack,当时我只能看见自己被hack,但并不清楚原因,直到周五偶然测x ^ 10000 * x ^ 1发现全组中出现一个wf,是自己的名字,结果发现这种类型的数据竟然已经交不上去了。百思不得其解,这种数据到底是合法还是非法的呢?之前助教的意思是不能提交Wrong Format 的数据,但我知道根据指导书的意思这种数据应该是正确类型,是自己的问题。这个问题的修复我开始想得很复杂,因为我判断指数是否合法的情况是在因子里边进行的,即PowFactor和TriFactor两个类都进行判断,实际上在求导前我进行同类项的化简,导致我后来再构建多项式过程中引用PowFactor和TriFactor两个类时,指数可能会大于10000而出错。最初我只想着在因子层面去判断指数范围,但是我发现我总会引用多项式类,而多项式的构建是基于各个项,项是由因子构成,但实际上我只想在最初的时候对指数进行判断之后。思考再三,既然只是修复这个bug,我决定在判断多项式格式正确性上进行改动,即利用正则表达式提取指数进行判断:
private static final String NUMBER = "(\s*\^\s*[+-]?\s*(\d+)\s*)";
private static final BigInteger MAXSIZE =
new BigInteger("10000");
Pattern pattern = Pattern.compile(NUMBER);
Matcher matcher = pattern.matcher(nowPoly);
while (matcher.find()) {
if (matcher.group(2) != null) {
BigInteger bigInteger = new BigInteger(
matcher.group(2)
);
if (bigInteger.compareTo(MAXSIZE) > 0) {
System.out.println("WRONG FORMAT!");
System.exit(0);
}
}
}
这大概就是测试中遇到的问题。在写代码中也遇到一些bug,比如第二次作业中第一次和第二次提交时第4个和最后一个测试点我都没有通过,在对输入格式进行逐行排查时发现了问题成功修复;还有就是我是用空格将每项进行分隔,但漏考虑*+(整数)的情况,导致此类数据虽然能计算但是是错误输出。而后者是通过同学进行覆盖性测试向我提出的,因此我认为写测试数据还是十分有必要的!
自己发现别人程序bug所采取的策略
第一次作业是可以看到别人被hack多少回,因此在经历最初的盲测后就从被hack最多的人代码开始看起,由于水平有限,在看完该同学代码后我觉得写得真好,怎么被找出这么多bug,难以置信,因为我真的一个bug都没找出来。接着就依次看hack次数由多到少的同学的代码,看完第三位同学代码便放弃了,之后没有考虑过他们的设计结构。第二次作业由于在互测前写了一部分数据,因此测起来还是比较方便,同时因为代码量的增多,想要逐份代码阅读我觉得不太现实,结果别人程序在我设计的数据集中并没有出错。于是我选取一份我觉得逻辑比较清晰的代码进行阅读学习,领会面向对象的思想。我认为如果在短时间内想要将屋子里7个人代码全部读透,这不太现实。虽然不太清楚之后的程序是否是类似可采取自动化测试,如果说可以的话,我们可以借助自己构造的数据在发现别人输出不正确的基础上找到根源,也是一种能力的提升。当然,时间允许的话我希望能够理解别人作业的架构,理解别人的思想,也希望大家能够好好利用readme,将自己的思路大致描述一下,给其他同学有理解的基础。
Applying Creational Pattern
通过三次作业在求导功能上的逐渐复杂,出题人本意是想让同学们逐渐领会到面向对象编程的思想。但是我觉得自己还是写出了面向过程的味道。在第三次作业中我没有用到接口和类,求导递归终止条件是第二次作业的基本表达式形式,实际上是没有达到锻炼效果的。我在互测过程中看到组里面有一个接口写得挺清楚的代码,是值得我学习的!通过最近对创建对象模式的学习,我发现至今仍是处于简单工厂模式,有需求产生时就new对象。而继承和接口的使用则会将程序转为工厂方法模式,让实例化推迟到子类,我认为此类模式能够实现更好地封装性。希望在接下来的学习中能够好好领悟。
总结