不得不说对于菜鸟级的我,这是一次心酸的经历啊。。。自打接到王老师布置的这个任务(个人项目)之后,我心里一直在想着自己要用哪种语言来完成我的任务。以前多多少少写过一些程序的,这又想起了数据库小学期与永哥和小强哥一起奋斗的日子来了,和大牛一起合作就是长见识,哈哈!
好吧,介绍一下题目,对一个英文文本进行词频统计,并把出现频率最高的10个词打印出来。
发愁是肯定的,努力也是肯定的,既然对一个英文文本进行词频统计,那么肯定会用到文件的读写函数,所以先找到了c语言课本,对这一部分的知识做了一下系统地复习。并且对该部分的知识做了一个小小的总结,虽然不是很全面吧,但是是自己对知识的深入理解。当然这对我们班的神人来说就是小case了,所以还是很惭愧滴!
对文件的读写操作搞懂了之后呢,就要设计自己的思路了。首先,定义一个结构体,(想必,我的同学们也有好多用结构体的...)
1 struct wordcount//定义一个结构体Wordcount 2 { 3 char *word; 4 int count; 5 struct wordcount *next; 6 };
然后定义了一些指向结构体变量的指针,和缓冲区用来存放从文本文件中获取的内容。然后运用isalpha()来判断读到缓冲区的内容是否为字母。
/* 函数:isalpha
原型:int isalpha(int ch)
用法:头文件加入#include <cctype>(旧版本的编译器使用<ctype.h>)
功能:判断字符ch是否为英文字母,当ch为英文字母a-z或A-Z时,在标准c中相当于使用“isupper(ch)||islower(ch)”做测试,返回非零值,否则返回零。*/
之后就是判断缓冲区中的单词有没有超过规定的最大限度,以及把大写字母转换为小写字母等等。部分代码如下

用strcpy()函数来判断是否和buff内的单词相同,若相同,则count+1
1 while (wc)//如果有的话则计数加1 2 { 3 if (strcmp(wc->word,buff)==0) 4 { 5 wc->count=wc->count+1; 6 isfinded=1; 7 break; 8 } 9 else 10 wc=wc->next; 11 }
对出现次数最高的10个词进行排序则可能弱了一些,我选用的是交换排序,所以效率会慢了一些。自然所用的时间就会长好多了(和那些大牛级的任务了)。下面是全部的代码:
#include <stdio.h> #include <ctype.h> #include <stdlib.h> #include <string.h> #define MAXLEN 30 struct wordcount//定义一个结构体Wordcount { char *word; int count; struct wordcount *next; }; struct wordcount *head,*wc,*sort,*headsort; char buff[MAXLEN]; char *zs_c;//buf[]数组用来存放英文字母 int buff_count=0, isfinded; int main() { FILE *fp; char ch; int i; int k; char filename[20]; printf("请输入文件名: "); scanf("%s",filename); if ((fp=fopen(filename,"r"))==NULL) { printf("不能打开该文件! "); exit(0); } while ((ch=fgetc(fp))!=EOF)//读取英文文本中的内容 if (isalpha(ch)) { buff[buff_count++]=tolower(ch);//判断是否为字母若果是则把它放到数组Buff[] if (buff_count>=MAXLEN) { printf("单词长度超过最大限度! ");//判断单词的长度是否超过最长限度 fclose(fp); return -1; } } else { //若果不是字母,且buff[]中没有单词的话则把其放到Wordcount link中 if (buff_count!=0) { buff[buff_count]='�'; wc=head; isfinded=0; while (wc)//如果有的话则计数加1 { if (strcmp(wc->word,buff)==0) { wc->count=wc->count+1; isfinded=1; break; } else wc=wc->next; } if (isfinded==0) { zs_c=(char *)malloc(buff_count); if (zs_c==0) { printf("错误!: zs_c ! "); fclose(fp); exit(0); } memcpy(buff,zs_c,buff_count); wc=(struct wordcount *)malloc(sizeof(struct wordcount)); if (wc==0) { printf("分配有误! "); fclose(fp); exit(0); } wc->word=zs_c; wc->count=1; wc->next=head; head=wc; } buff_count=0; } } fclose(fp); if (head)//对单词进行排序 { sort=head->next; head->next=0; while (sort) { wc=sort; sort=sort->next; if ((wc->count) > (head->count)) { wc->next=head->next; head=wc; } else { headsort=head; while ((headsort->next) && (headsort->next->count > wc->count ))//交换进行排序 { headsort->count=headsort->next->count; wc->next->count=headsort->next->count; wc->next->count=headsort->count; headsort->word=headsort->next->word; wc->next->word=headsort->next->word; wc->next->word=headsort->word; } } } } while (head)//对结果进行输出 { wc=head; head=head->next; printf("序号 单词 频率 "); for(i=1;i<11;i++) printf("NO%d %s %d ",i,wc->word,wc->count); } return 0; }
运行结果:
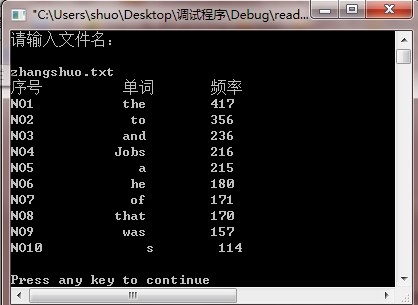
个人工作总结:
实话说来对于好久没有碰过程序的我来说不得不说这是很困难的。
2.22就开始构思如何实现这个问题,开始进行咨询,并开始复习文件的读取。
2.27上机时间(2:00--4:00)开始写程序,事实表明情况是不乐观的,此时多么希望神可以拯救我啊!(抓狂)。后来了解到,用trie树,map实现起来效率比较高,所以对这两种方法进行了查询,但是能力有限,所以还是沿用了最先的想法,周五自打吃完晚饭,就开始继续调试程序,就因为文件无法读取这个问题困扰了一晚上,最终和娇哥交流后,(因为她也遇到了相同的问题,难姐难妹啊),才知道是文件默认的格式就是.txt,是自动隐藏的,还以为是自己安装的vc有问题呢或者和电脑本身有关系,看来写程序这个东西是要和同仁交流的!!!。
周六晚8:00又出现了一个大大的问题那就是死循环,所以那更是一个痛苦,程序的调试是必须的了,终于,发现了!原来是在进行数据交换的时候丢了一个指针。本来想使用argv传递参数的,argv[0]是执行的该文件,argv[1]是传递的第二个参数,即在屏幕上输入的第一个内容,本来是想用这种方法来获取文件的名称的,但是失败了,所以又改用了原来c语言传统的文件读取方式。
不得不承认我的这个工程效率是不高的,比如说排序用到的算法啊,(有时间一定要再研究一下)如果文本的大小再大些的话,速度是相当的慢了就。自己的能力还不是很高,自己都觉得着急了,因为对trie树也进行了一定的学习,我想自己接下来能否可以用这种数据结构来实现,最让我崇拜的就是辉哥的hashtable了,自己一定要对这些知识进行学习。多学习,多联系,这是我对写程序的深刻体会!