一、原因
- NameNode是HDFS的黑心配置HDFS有事hadoop的核心组件 NameNode 在Hadoop及群众至关重要
- NameNode的宕机导致集群的不可用
二、解决方案
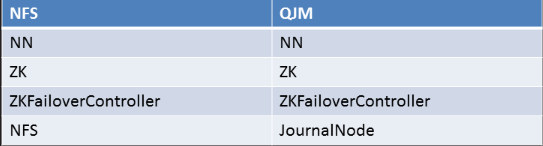
其中 NN表示两台 NameNode ZK表示 zookeeper(保持事务的一致性)
两种 1. HDFS with nfs 2. HDFS with QJM
方案对比
(一)都能实现热备
(二)都是一个Active NN一个 Stabdby NN
(三)都是用zookeeper和zkfc来实践自动失效恢复(事务一致)
(四)失效切换都试用Fencin配置的方法来Active NN
(五)NFS数据共享变更方案把数据存储在共享存储里,我们还需要考虑NFS的高可用
(六)QJM不需要共享存储 但需要让内个DN都知道两个NN的位置 并把块信息和心跳包发送给Active和Standby这两个NN
三、选择QJM
QJM不需要共享存储,客户端访问NameNode1后,数据存储完成,DataNode会返还给NameNode1数据存储位置,这时就会生成fsimage文件,那么把返还的数据信息给NameNode2一份 。fsedit数据变更日志 NameNode1 把数据变成日志记录在 JNS 上(相当于MySQL的中继日志) NameNode2读取JNS的数据(JNS可以做成高可用)
(一)解决NameNode单点故障问题
(二)Hadoop给出的HDFS的高可应用HA方案 HDFS通常有两个NameNode组成 一个处于Active另一个处于Standby状态 ACtive NameNode对外提供服务 比如处理来自客户端的PRC请求 而 Standby NameNode 则不对外提供服务 仅同步 Active NameNode的状态 以便能够在失败时能够进行切换
(三)高可用图

系统规划图(下面有nn01或则nn02即表示NameNode1 NameNode2)

(四)安装
(1)配置 hosts 文件并且传给所有的机器
(2)给nn02配置公钥、私钥(如果是添加的nn02那么可以直接吧nn01的/root/.ssh/下的文件直接复制过去)
(3)安装zookeeper集群
(4)配置Hadoop文件
1.core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> #文件系统
<value>hdfs://hadoop</value> #因为是NameNode有两台所以这里引用一个组的名字把这两台放在组中 这个组的名字不能全是数字
</property>
<property>
<name>hadoop.tmp.dir</name> #数据文件的存放目录
<value>/var/hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> #声明zookeeper
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>hadoop.proxyuser.nfsuser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.nfsuser.hosts</name>
<value>*</value>
</property>
</configuration>
2.hadoop-env.sh
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre" #大约在25行,声明Java的安装路径 export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop" #大约在33行,生命Hadoop的安装路径
3.hdfs-site.xml
<property>
<name>dfs.nameservices</name> #声明组 core-site.xml 在这个文件中写的什么下面就要填什么
<value>hadoop</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoop</name> #声明组中的角色名字
<value>nn1,nn2</value>
<property>
<name>dfs.namenode.rpc-address.hadoop.nn1</name> #组中nn1的机器是哪个 (rpc-address这两个心跳关系)
<value>nn01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop.nn2</name> #组中nn2的机器是哪个
<value>nn02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop.nn1</name> #声明NameNode nn1的机器
<value>nn01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop.nn2</name> #声明NameNode nn2的机器
<value>nn02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name> #声明journalnode的节点(数据更变日志)
<value>qjournal://node1:8485;node2:8485;node3:8485/nsd1905</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name> #声明journalnode的数据存放目录
<value>/var/hadoop/journal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.nsd1905</name> #声明高可用的软件
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> #声明ssh
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name> #声明ssh的存放目录
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name> #自动切换
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>
</property>
4.mapred-site.xml
<property>
<name>mapreduce.framework.name</name> #声明管理方式
<value>yarn</value>
</property>
5.slaves (声明DateNode的节点)
node1
node2
node3
6.yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name> #打开ha高可用
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name> #声明rm的角色
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name> #打开resourcemanage 高可用的软件
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name> #yarn的数据存储的一个类
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name> #声明zookeeper地址
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name> #声明 id 组的名称
<value>yarn-ha</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name> #声明 rm1 对应的机器
<value>nn01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name> #声明 rm2 对应的机器
<value>nn02</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(五)启动服务
(1)验证zookeeper是否正常
(2)同步配置到所有机器
(3)初始化zookeeper集群(在NameNode1上操作)
/usr/local/hadoop/bin/hdfs zkfc -formatZK
(4)启动journalnode服务(node1 2 3 上操作)
/usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
(5)NameNode1初始化
/usr/local/hadoop//bin/hdfs namenode -format
(6)同步配置到 NameNode2上(因为初始化之后生成文件的id是唯一的所以只需要把文件直接 上传给NameNode2就行)
rsync -aSH nn01:/var/hadoop/ /var/hadoop/
(7)初始化JNS(NameNode1上操作)
/usr/local/hadoop/bin/hdfs namenode -initializeSharedEdits
(8)停止journalnode服务(在node 1 2 3 上操作)
/usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
(9)启动集群(在NameNode1上操作)
/usr/local/hadoop/sbin/start-all.sh
(10)启动热备resourcemanager
/usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
(六)验证服务
(1)查看集群状态(可以看到一个是active一个是standby)
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn2
/usr/local/hadoop/bin/yarn rmadmin -getServiceState rm1
/usr/local/hadoop/bin/yarn rmadmin -getServiceState rm2
(2)查看节点是否加入
/usr/local/hadoop/bin/hdfs dfsadmin -report
(3)访问集群
/usr/local/hadoop/bin/hadoop fs -ls /
/usr/local/hadoop/bin/hadoop fs -mkdir /aa
/usr/local/hadoop/bin/hadoop fs -ls /
(4)验证高可用,关闭 active namenode (关闭之后再次查看状态会报错)
/usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode
/usr/local/hadoop/sbin/yarn-daemon.sh stop resourcemanager
(5)恢复节点(回复完在查看)
/usr/local/hadoop/sbin/hadoop-daemon.sh start namenode
/usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager