目标:
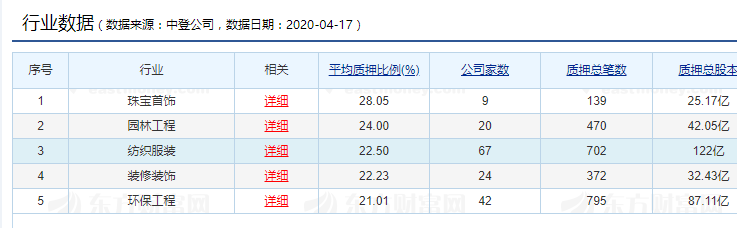
代码:
import requests from lxml import etree from bs4 import BeautifulSoup import re import csv import datetime today = datetime.date.today().strftime('%Y%m%d') url = 'http://data.eastmoney.com/gpzy/' res = requests.get(url) res.encoding = res.apparent_encoding soup = BeautifulSoup(res.text,'lxml') soup = soup.text # html = etree.HTML(res.text) # data = soup.text.strip().lstrip('pageCollect("#datatitle .tit");var pagedata={').rstrip(';}').split(':[') data = re.search(r'hysjlb:[([sS]*?)$',soup).group(1).strip().replace(' ','').replace('T00:00:00','').replace('-','') location = data.find(']};') data = data[:location].replace(' ','').replace(',{',',,{').split(',,') date = [] hy = [] amtshareratio_pj = [] gssl = [] amtsharenum = [] bballowance = [] zysz = [] for i in range(len(data)): das = eval(data[i]) date.append(das["tdate"]) #时间 hy.append(das["hy"]) #行业 amtshareratio_pj.append(das["amtshareratio_pj"]) #质押比例 bballowance.append(das["bballowance"]) #质押总股本 amtsharenum.append(das["amtsharenum"]) #质押总笔数 gssl.append(das["gssl"]) #公司家 zysz.append(das["zysz"]) #最新质押值 f = open('e:\shuju\3.csv', 'w',newline='') #csv数据存储 writer = csv.writer(f) writer.writerow(('序号','时间','行业','平均质押比例(%)','公司家数','质押总笔数','质押总股本(万元)','最新质押市值(万元)','采集时间' )) for i in range(len(hy)): writer.writerow((i+1,date[i],hy[i],amtshareratio_pj[i],gssl[i],amtsharenum[i],bballowance[i],zysz[i],today))
结果:
