写了几篇文章都是自己看的,没什么水平,只放了几个注释,供借鉴。
这几天每天在各大交易所爬数据,头大,写几个放在里面怕丢掉了。
一、思路
1 、打开你要爬取的网页

2、拿到你要的网页url

3、找到你所要数据所处的网页位置
F12 点击 ,然后在网页上点你所需要的数据,开发者窗口跳转到你所要的数据上,可以用copy——xpath直接拿数据位置,后面加上 //text(),或者用的是bs4 那么可以用copy——selector ,但是现在大多数网页都是动态的,用刚才的那两种方式都会爬出来 “加载中。。。” 这样的东西,那么我们现在需要找到他动态json的文件的位置
,然后在网页上点你所需要的数据,开发者窗口跳转到你所要的数据上,可以用copy——xpath直接拿数据位置,后面加上 //text(),或者用的是bs4 那么可以用copy——selector ,但是现在大多数网页都是动态的,用刚才的那两种方式都会爬出来 “加载中。。。” 这样的东西,那么我们现在需要找到他动态json的文件的位置
点击 ,
,
然后在网页中刷新一下,这边会重新加载各种request请求,
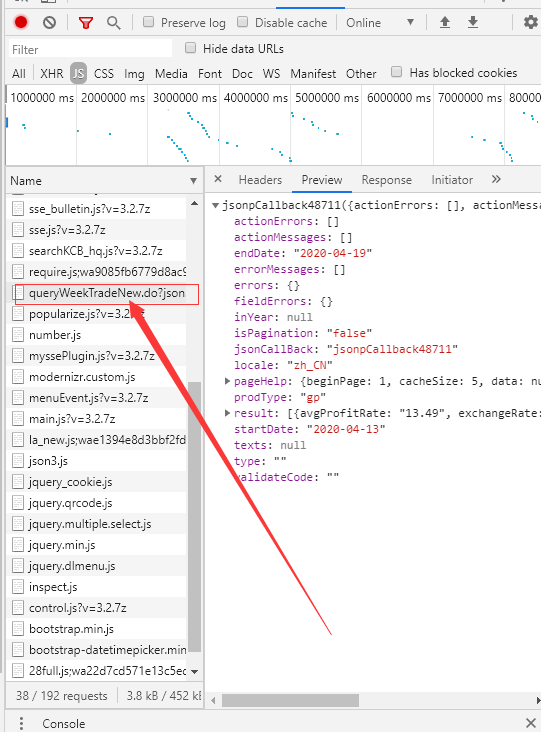
大部分都是这种格式的文件,看这文件的result下的数据是不是你表格中的数据,如果是那就成功一半了。(狗头),这时候
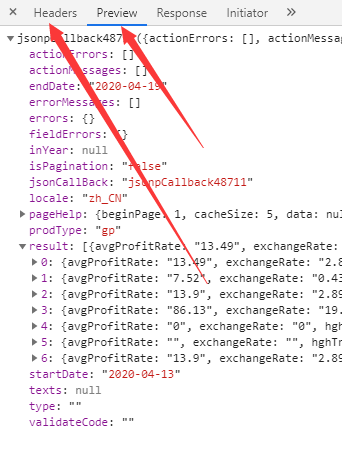
preview旁边这个Headers提供给你一大堆的数据,什么 Cookie url headers referer 等 都有了 ,复制到你代码里面去。
import requests from bs4 import BeautifulSoup import json import re import csv import datetime today = datetime.date.today() today_weekday = today.isoweekday() last_sunday = today - datetime.timedelta(days=today_weekday) last_monday = last_sunday - datetime.timedelta(days=6) last_monday = last_monday.strftime('%Y-%m-%d') last_sunday = last_sunday.strftime('%Y-%m-%d') #构造url内必须的时间段 Cookie = "yfx_c_g_u_id_10000042=_ck20042119410119711157603279361; VISITED_MENU=%5B%228451%22%2C%2211169%22%5D; JSESSIONID=0FA87A107EC2DEF8FF84BE91E7CE3AAA; yfx_f_l_v_t_10000042=f_t_1587469261946__r_t_1587469261946__v_t_1587472096302__r_c_0" url = "http://query.sse.com.cn/marketdata/tradedata/queryWeekTradeNew.do?jsonCallBack=jsonpCallback19066&prodType=gp&startDate="+ last_monday+"&endDate=" + last_sunday headers = { 'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36', 'Cookie': Cookie, 'Connection': 'keep-alive', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Host': 'query.sse.com.cn', 'Referer': 'http://www.sse.com.cn/market/stockdata/overview/weekly/' } req = requests.get(url,headers=headers) req = req.text end_date = re.search(r'"hghVald":([sS]*?)$',req).group(1)[1:11] strat_date = re.search(r'"lowTrnd":([sS]*?)$',req).group(1)[1:11] result_del = ',"startDate":"'+strat_date+'","texts":null,"type":"","validateCode":""})' #后面result需要替换为空的部分 result = re.search(r'"result":[([sS]*?)$',req).group(1).replace('[','').replace(']','').replace(result_del,'').replace(',{',',,{').split(',,') # for i in range(len(result)): # data = eval(result[i]) # print(data) productType =[] #产品种类 1 主板A 2 主板B 12 股票 48 科创板 43 股票回购 exchangeRate =[] #换手率(%) avgProfitRate =[] #平均市盈率(倍) hghTrn =[] #最高成交笔数(万笔) hghVal =[] #最高成交金额(亿元) hghVol =[] #最高成交量(亿股) lowTrn =[] #最低成交笔数(万笔) lowVal =[] #最低成交金额(亿元) lowVol =[] #最低成交量(亿股) mktValue =[] #市价总值(亿元) negotiableValue =[] #流通市值(亿元) tradingTx =[] #成交笔数(万笔) txAmount =[] #成交金额(亿元) txDates =[] #累计交易天数(天) txNum =[] #挂牌数 txVolume =[] #成交量(亿股) for i in range(0,5): data = eval(result[i]) productType.append(data["productType"]) exchangeRate.append(data["exchangeRate"]) avgProfitRate.append(data["avgProfitRate"]) hghTrn.append(data["hghTrn"]) hghVal.append(data["hghVal"]) hghVol.append(data["hghVol"]) lowTrn.append(data["lowTrn"]) lowVal.append(data["lowVal"]) lowVol.append(data["lowVol"]) mktValue.append(data["mktValue"]) negotiableValue.append(data["negotiableValue"]) tradingTx.append(data["tradingTx"]) txAmount.append(data["txAmount"]) txDates.append(data["txDates"]) txNum.append(data["txNum"]) txVolume.append(data["txVolume"]) productType = ['主板A' if i == '1' else i for i in productType] #另一种方法是 先做一个字典用 k v 存储数据 然后同样列表生成式 productType = ['主板B' if i == '2' else i for i in productType] #productType1 = [aaa[i] if i in aaa else i for i in productType] productType = ['股票' if i == '12' else i for i in productType] productType = ['科创板' if i == '48' else i for i in productType] productType = ['股票回购' if i == '43' else i for i in productType]
txNum = ['0' if i == '' else i for i in txNum]
f = open('data.csv', 'w', newline="") #csv数据存储 writer = csv.writer(f) writer.writerow(('开始日期','结束日期', '产品种类', '挂牌数', '市价总值(亿元)', '流通市值(亿元)', '成交金额(亿元)', '最高成交金额(亿元)', '最低成交金额(亿元)','成交量(亿股)','最高成交量(亿股)','最低成交量(亿股)','成交笔数(万笔)','最高成交笔数(万笔)','最低成交笔数(万笔)','平均市盈率(倍)','换手率(%)','累计交易天数(天)')) for i in range(0,5): writer.writerow((strat_date.replace('-',''),end_date.replace('-',''),productType[i],txNum[i],mktValue[i],negotiableValue[i],txAmount[i],hghVal[i],lowVal[i],txVolume[i],hghVol[i],lowVol[i],tradingTx[i],hghTrn[i],lowTrn[i],avgProfitRate[i],exchangeRate[i],txDates[i]))
4、此时啥都有了,就能拿出数据了,更主要的是数据的提取了,我这里主要是把他转成列表,然后对号入座,比较传统,很好理解。
